Follow a reproducible troubleshooting pattern: observe symptoms, gather cluster state (svc/pods/endpoints/events/metrics/quotas), link evidence to possible causes, and apply the smallest safe remediation. Use
kubectl + events + metrics to avoid misdirection.Task 1 — Order API: Service exists but traffic not routed
Reproduce symptom:- From the host try the NodePort:
- Gather basic cluster state in the
defaultnamespace:
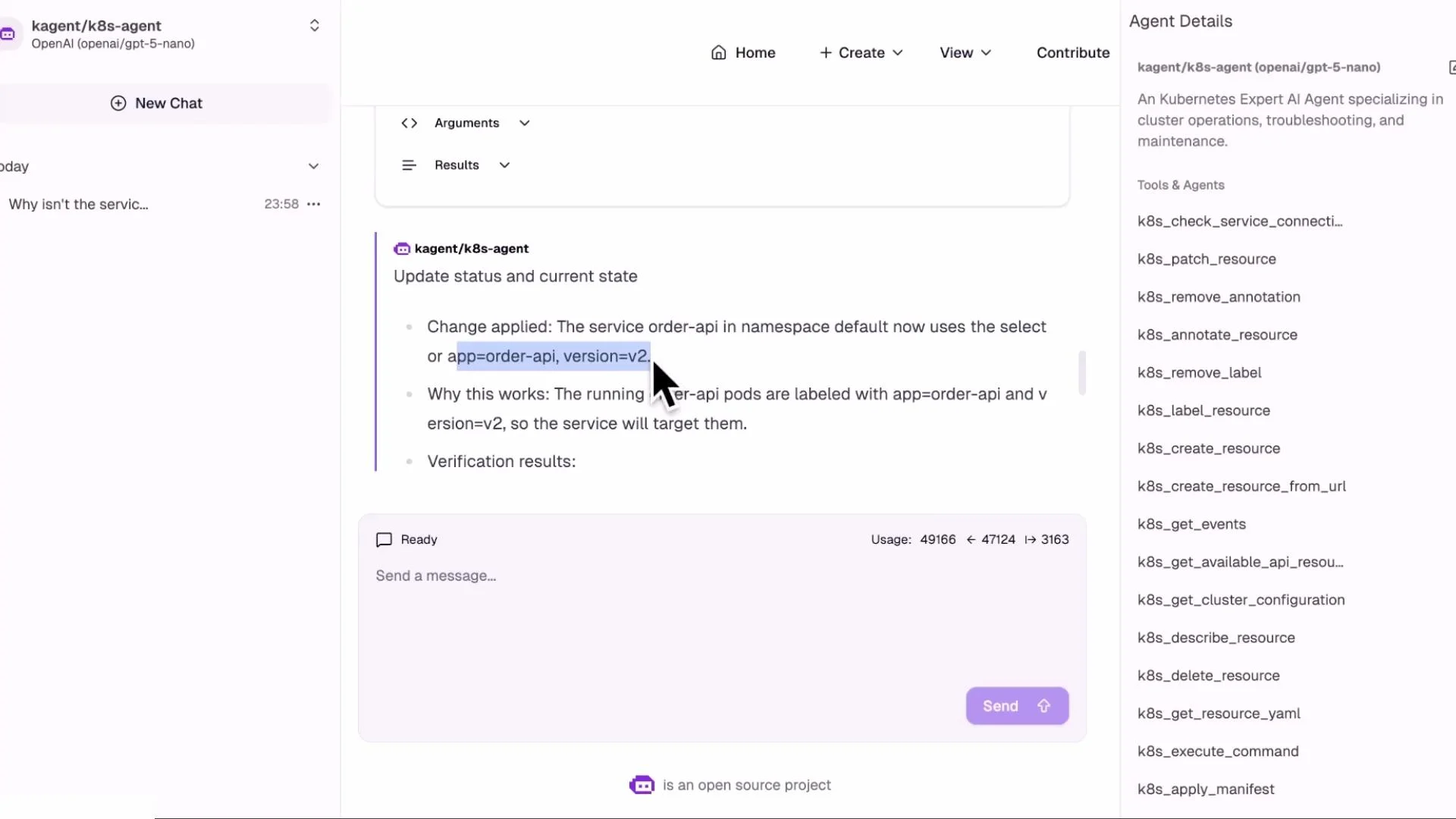
order-api Service present but with empty endpoints. Inspect the Service manifest to check selectors:
- Running pods show label
app=order-apibutversion=v2(pod template usesv2). - The Service selector is
version=v1. This selector mismatch means the Service selects no pods → no endpoints → traffic not routed.
- Edit the Service selector to match pods, or update the Deployment labels to match the Service.
- To change the Service selector to
v2(example usingkubectl patch):
- Alternatively, edit the Service interactively:
version=v1 vs version=v2) between the Service and the Deployment pods.
Task 2 — HPA not reaching minReplicas in backend-apps
Scenario: An HPA is configured for inventory-service with:
- CPU target: 80%
minReplicas: 3maxReplicas: 10
- Inspect HPA and pods:
- Describe the HPA to view events/conditions:
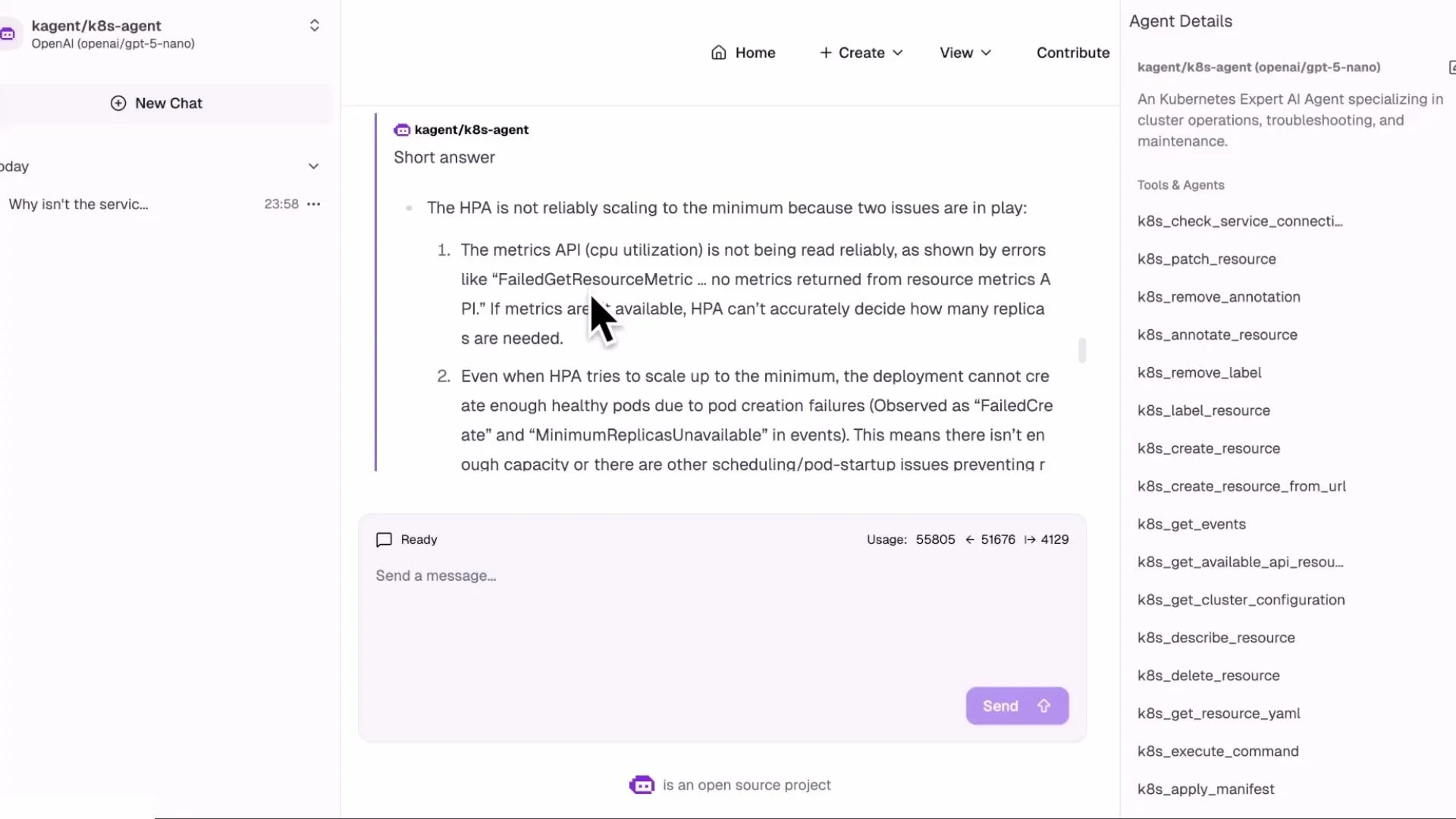
- Check cluster metrics availability:
kubectl top nodes returns values, node metrics server is responding. HPA CPU/resource metrics may still be affected if Pods’ metrics are missing or metrics-server has issues.
- Inspect namespace events for pod creation failures:
Pod ... Forbidden: exceeded quota or FailedScheduling.
- Check ResourceQuota in the namespace:
1/1, preventing the HPA from creating the minReplicas=3.
Fix:
- Update the ResourceQuota to allow more pods (for example
pods: 10) or adjust quota to match expected application scale.
- After increasing the quota, the cluster can create additional pods and the HPA should converge to the desired replicas.
- The HPA warnings about metrics indicate a metrics failure path that should be investigated (metrics-server, kubelet metrics, scraping), but the immediate blocker preventing scale-up was the
ResourceQuotarestricting pods to 1. Always correlate events + quotas + metrics to determine the decisive cause.
Do not increase namespace quotas indiscriminately in production. Align quota changes with capacity planning and organizational policies. If unsure, request approval or test changes in a non-production environment first.
Manual troubleshooting summary
Troubleshooting tip: Combine
kubectl get/describe, events, metrics (kubectl top), and namespace quotas to build the causal chain.
KAgent: AI-powered Kubernetes troubleshooting
KAgent exposes a chat-style UI and executes a defined toolset (get resources, describe, get YAML, apply manifests, etc.). When given a natural language prompt such as: “Why isn’t the serviceorder-api in namespace default routing?”
the agent runs investigative commands, aggregates the results, and sends them to an LLM for analysis. The agent can iterate (requesting additional data) until it provides a prioritized diagnosis and actionable remediation.
Example metadata the agent uses to identify resources:
version=v1 vs pods version=v2), recommends updating the Service selector to version=v2, and can apply that change automatically (via a manifest or kubectl apply) and then re-check endpoints.
inventory-service: describe HPA, check events, inspect ReplicaSet/Deployment, and verify ResourceQuota. It produces a prioritized list of causes (metrics-server issues vs quota) and recommends changing the ResourceQuota to allow more pods as the decisive remediation.
- Natural language triage: describe the issue in plain English and let the agent gather evidence.
- Faster discovery: consistent, repeatable investigative flow reduces manual rework.
- Evidence surfacing: shows exactly which commands and outputs lead to a conclusion.
- Improved MTTR and operational consistency across teams.
Closing and next steps
In this lesson we:- Manually diagnosed two common Kubernetes problems: a Service selector mismatch and a namespace
ResourceQuotapreventing HPA scaling. - Demonstrated how KAgent can automate the same investigative steps and recommend or perform safe remediation.
- Building custom agents and configuring LLM providers
- Defining a safe toolset and guardrails for automated remediation
- Instrumenting clusters to improve metrics and observability