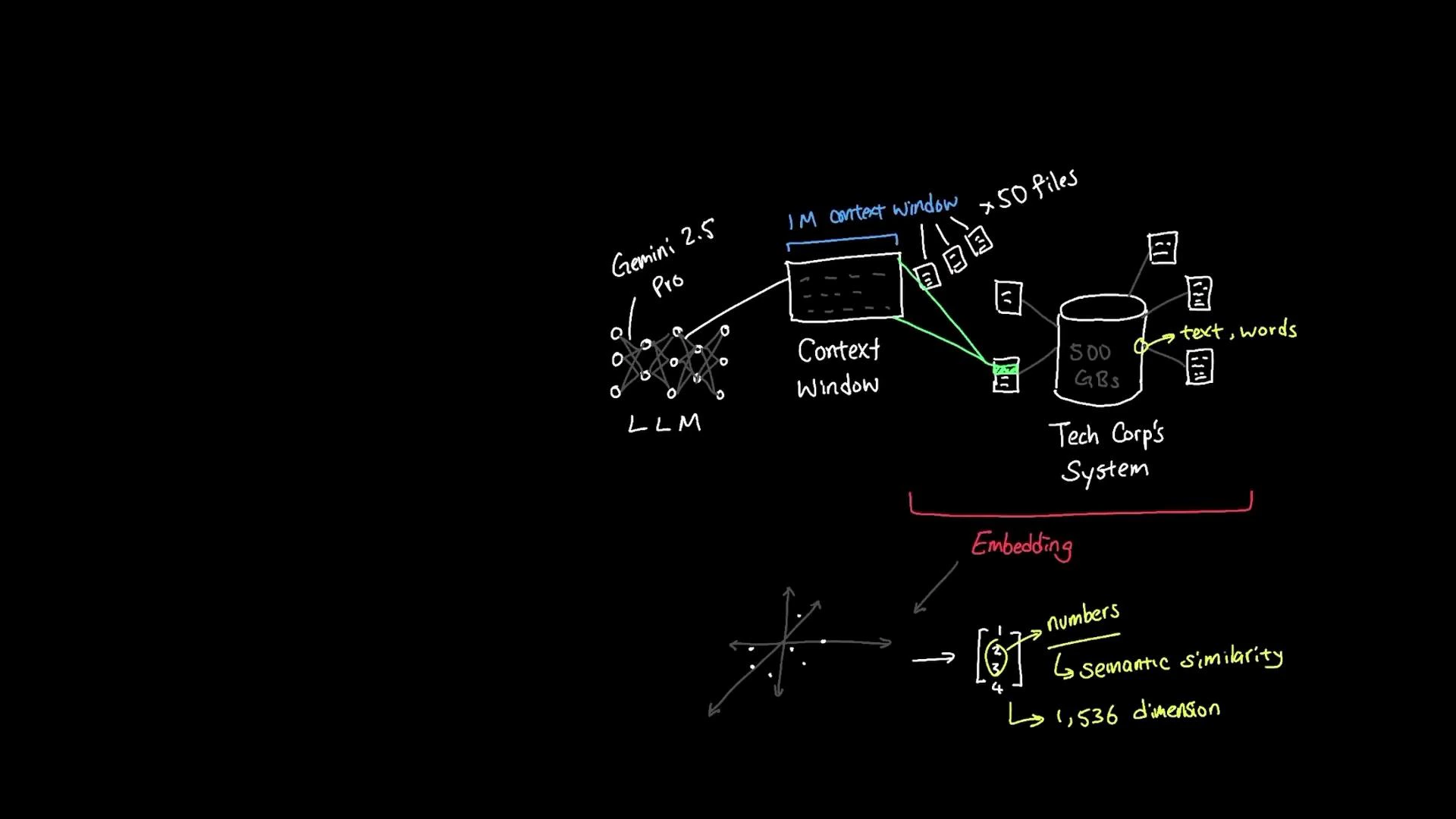
- User query -> embed: Convert the user’s question into an embedding vector.
- Vector search: Compare the query embedding against stored document embeddings in a vector database (vector store) to find nearest neighbors.
- Context assembly: Retrieve the top matching documents (e.g., HR policies, dress-code documents).
- LLM grounding: Provide those retrieved documents as context to a large language model so it can generate a grounded answer — returning responses based on meaning and relevant documents rather than only keyword matches.
- Semantic search across a large document corpus (e.g., 500 GB) to find intent-matching documents.
- Robustness to paraphrase and synonyms: employees get correct answers even if they ask questions differently.
- Better relevance ranking by combining vector similarity with metadata and filters (date, author, department).
Normalize embeddings (L2 normalization) if you plan to use cosine similarity — this simplifies comparisons and often improves search quality. Combine vector similarity with metadata filters (time, department) to reduce false positives.
- Convert the question to an embedding.
- Query the vector store to retrieve top N documents about attire, dress code, and HR policies.
- Provide those documents as context (prompting context window) to the LLM so it can answer with citations or specific policy language.
- Optionally, re-rank or filter results by document freshness or source trustworthiness.
- Introduction to Embeddings — Google Developers
- OpenAI — Embeddings
- Vector databases and nearest-neighbor search — Faiss
- Semantic search: architectures that combine embeddings + vector DB + LLMs.
- Vector database options: Pinecone, Milvus, Weaviate, and Faiss.
- Prompting strategies: how to assemble retrieved documents into LLM prompts for grounded answers.