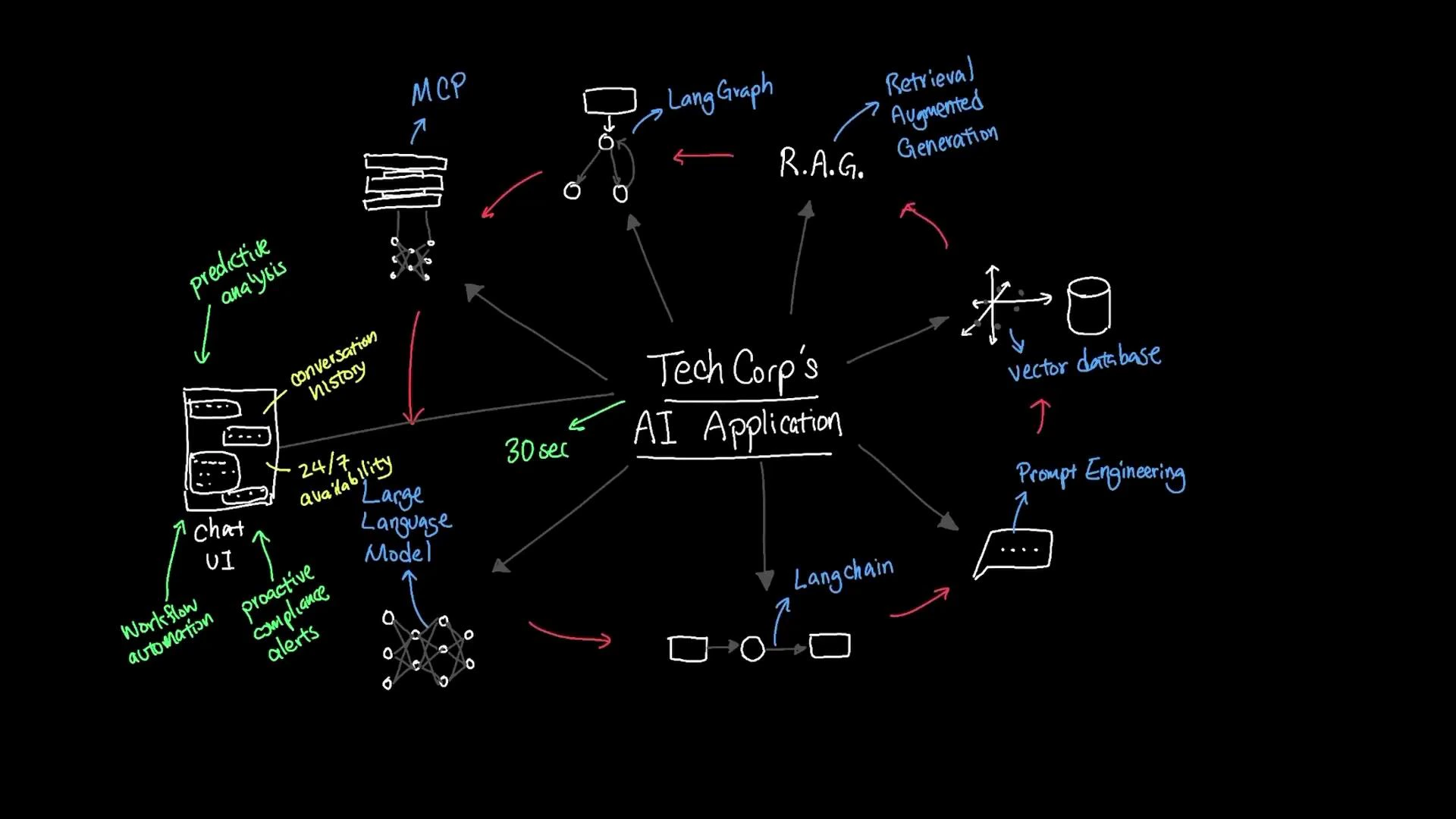
Blueprint for building a context-aware document search agent using RAG, vector databases, orchestration, model management, and prompt engineering to improve enterprise knowledge access
In this lesson we combined context windows, vector databases, orchestration layers, model management practices, and prompt engineering to build a practical, context-aware document search agent for TechCorp. The architecture demonstrates how retrieval-augmented generation (RAG) and semantic vector search convert slow, manual lookups into fast, accurate, context-rich answers—transforming knowledge access across the organization.Key outcomes at a glance:
Benefit
Practical impact
Notes for implementation
Performance & accuracy
Queries that previously took ~30 minutes now return relevant answers in under 30 seconds
Use semantic embeddings, nearest-neighbor search in a vector DB, and RAG to surface and synthesize evidence for answers
User experience
Chat-style UI preserves conversation state and supports follow-ups without repeated context
Keep short-term and long-term context windows and display provenance for trust
Operational availability
24/7 assistance while the application is running, across time zones and shifts
Automate health checks, autoscaling, and graceful degradation in orchestration layers
Extendability
Foundation for predictive analytics, proactive compliance agents, and workflow automation
Expose modular APIs and pipelines so new capabilities can be plugged into the system
Practical next steps: ensure data governance (access controls and redaction), implement monitoring and evaluation for relevance and hallucination, set up model versioning and cost monitoring in your model management platform (MCP), and iterate on prompts and retrieval strategies based on user feedback.
Moving from static repositories to living, intelligent systems is a turning point for enterprise knowledge management. With the right engineering patterns—vector stores for retrieval, LLMs for understanding and synthesis, orchestration layers for reliability, and an MCP for governance and observability—you can build applications that not only answer questions but increasingly anticipate and resolve business problems.Recommended next actions
Establish data governance: role-based access, redaction, and encrypted storage for sensitive documents.
Monitor model outputs: log provenance, measure relevance, and detect hallucinations with automated tests.
Version and cost control: track model versions, deployments, and runtime costs in your MCP.
Iterate on retrieval and prompts: A/B test retrieval strategies, embedding models, and prompt templates based on user metrics.
The approach outlined here is a practical blueprint for TechCorp and similar organizations that want to unlock knowledge at scale—reducing time-to-answer, improving accuracy, and enabling proactive automation that adds real business value.