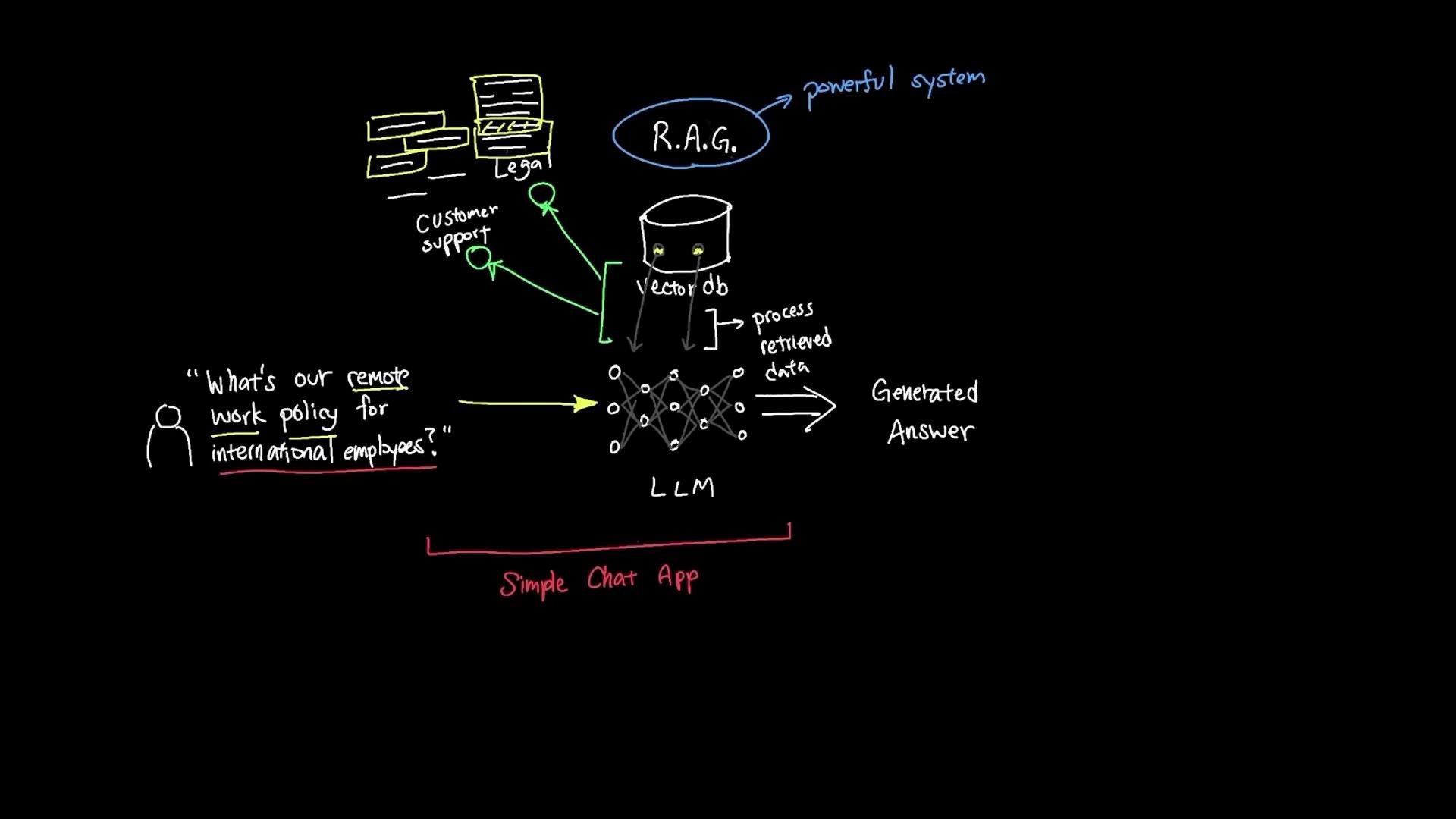
remote-work-policy.pdf for the query “work from home”), the RAG pipeline retrieves relevant context and uses a large language model (LLM) to generate concise, grounded answers such as: “Yes — employees may work up to three days per week from home.”
Key concepts covered:
- Vector store initialization and persistence (ChromaDB)
- Semantic embeddings with sentence-transformers
- Smart document chunking for context preservation
- LLM integration and prompt engineering for RAG
- A complete pipeline that returns answers with source attributions
Environment setup and verification
Install required libraries. Common libraries used in this lab:- ChromaDB (vector database): https://www.trychroma.com/
- Sentence Transformers (embeddings): https://www.sbert.net/
- LangChain (RAG orchestration): https://python.langchain.com/
- OpenAI-compatible model endpoints (for example, GPT-4.1 Mini)
Task 1 — Setup the vector store (ChromaDB)
Create a persistent ChromaDB client and a collection to store document embeddings. Load the sentence-transformers modelall-MiniLM-L6-v2 (384-d vectors) to embed document chunks and queries.
Example setup code (task_1_setup_vectorstore.py):
Task 2 — Document processing and smart chunking
Chunking strategy is critical for RAG quality. Prefer paragraph-based chunking with small overlaps so chunks preserve complete thoughts and transitions. This helps the LLM use coherent context without requiring large token budgets. Example implementation (task_2_document_processing.py):- Paragraph-based chunking preserves semantics better than fixed-character slices.
- Make chunk size and overlap parameters configurable for tuning to prompt token limits.
Task 3 — LLM integration
Connect a deterministic, production-ready LLM client (for example, GPT-4.1 Mini via an OpenAI-compatible client). Use conservative generation settings (low temperature, token limits) to reduce hallucination and produce concise answers. Example code (task_3_llm_integration.py):Task 4 — Prompt engineering for RAG
Craft a prompt template that:- Injects retrieved context chunks into the prompt,
- Explicitly instructs the model to answer only from the provided context,
- Requires a fixed fallback phrase when the context does not contain the answer to avoid hallucination.
Design prompts that explicitly constrain the model to the retrieved context and provide a clear fallback phrase for missing information to prevent hallucinations.
Task 5 — Complete RAG pipeline
Assemble the end-to-end pipeline:- Embed the user’s query using the same embedding model that encoded document chunks.
- Query ChromaDB for top-k most relevant chunks (semantic search).
- Build a context-aware prompt from those chunks.
- Send the system + user prompt to the LLM to generate an answer.
- Return the answer along with source attributions (document metadata).
Practical considerations and next steps
- Tune chunking size and overlap to balance contextual completeness against token limits for your target LLM.
- Experiment with embedding models (quality vs. cost) and with LLM temperature/length settings.
- Add filters for document recency, confidentiality tags, or department-level access control.
- Implement caching, rate limiting, and logging for production usage.
- Consider connecting to HR systems or identity-aware access control when answers depend on user-specific entitlements.
Handle confidential or restricted documents with care. Ensure access controls and document classification are enforced before including sensitive content in embeddings or returning it in generated answers.