Pretraining datasets do not include your private company files (for example, TechCorp’s 500 GB of internal documents) unless they were explicitly added to the training data. To get an LLM to answer questions about private data, you must provide that data to the model at query time.
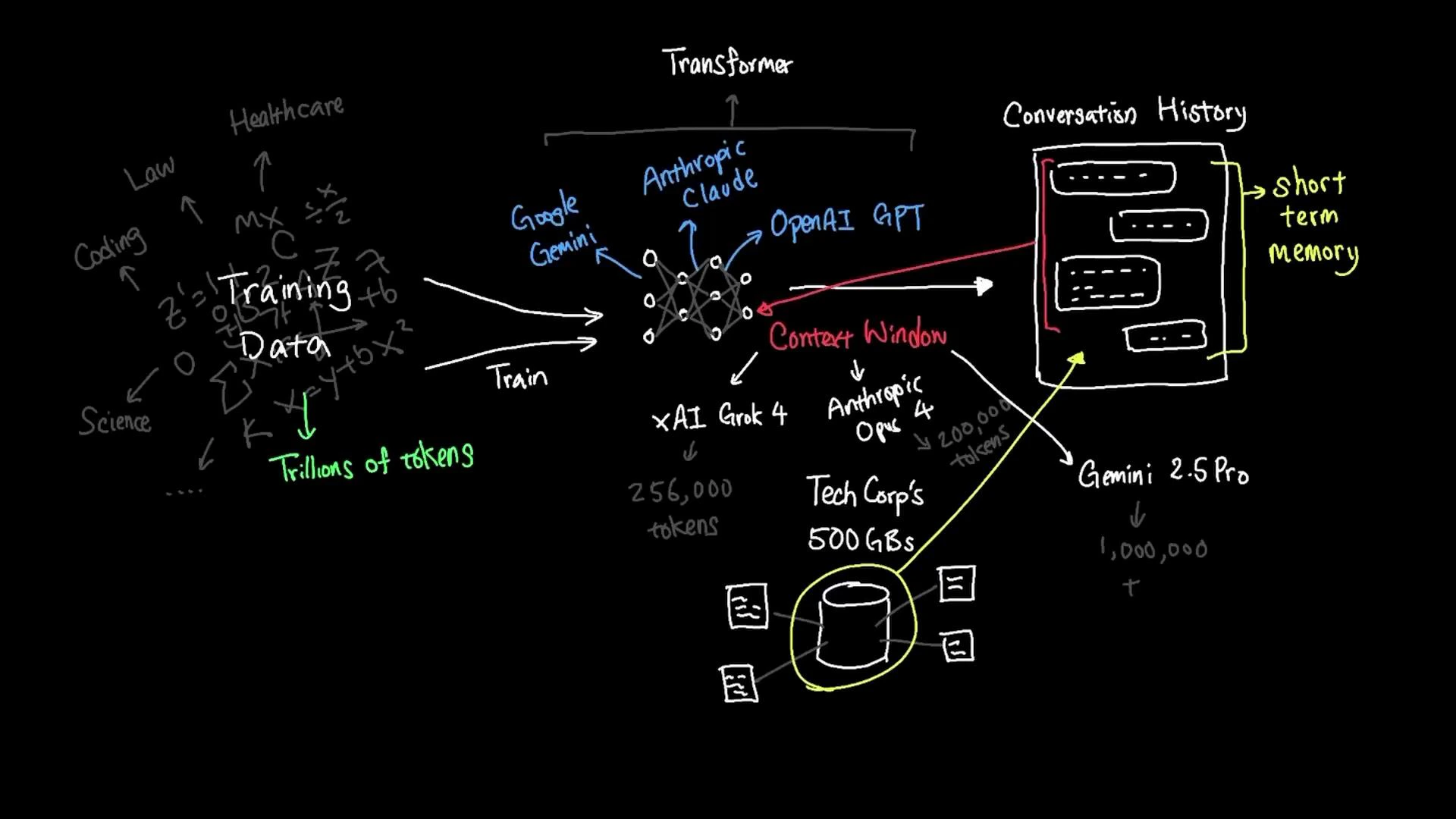
- Smaller models (2k–4k tokens) are well-suited to short interactions and lower-latency use cases.
- Larger models with huge windows (hundreds of thousands to a million tokens) can handle long documents, entire books, or many source files at once.
- Regardless of size, only the tokens that are actually included in the context are visible to the model at query time.
Sally has 14 apples.
Apples are often red.
12 is a nice number.
Bob has no red apples, but he has two green apples.
Green apples often taste bad. How many apples do they all have? To answer correctly, the model must extract the relevant facts (Sally has 14, Bob has 2) and ignore irrelevant details (apple color, taste, or unrelated numbers). The correct total is 16.
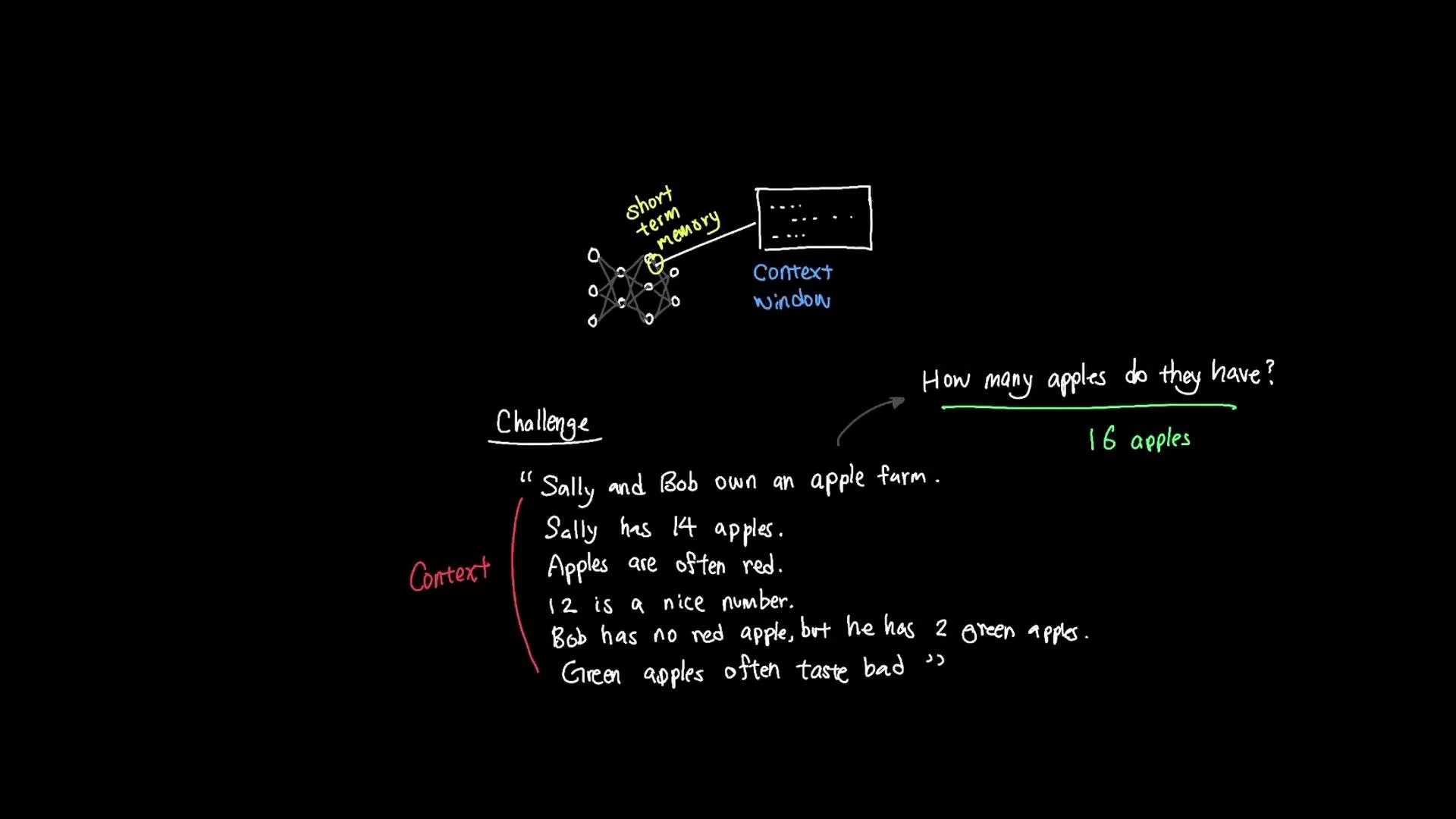
- Irrelevant information in the context consumes token budget and can distract the model.
- Only a fraction of a very large knowledge store can be presented to the model at one time.
- Document chunking: split large files into smaller, semantically coherent chunks that fit the context window.
- Embeddings + vector search: convert chunks to embeddings, perform similarity search to find the most relevant passages, and surface those passages in the prompt.
- Retrieval-augmented generation (RAG): combine retrieval (vector search) with generation so the model uses retrieved documents to answer queries.
- Summaries & hierarchical retrieval: use summaries to locate relevant sections, then retrieve full content for finer-grained answers.
- External tools & workflows: call external search engines, databases, or specialized tools to fetch data the model can use.
When designing systems that use private documents with LLMs, combine embeddings-based retrieval with concise prompt engineering (and fine-grained chunking) to ensure the model receives only the most relevant context within its token budget.
- Transformer architecture: https://en.wikipedia.org/wiki/Transformer_(machine_learning_model)
- Retrieval-augmented generation (RAG): https://en.wikipedia.org/wiki/Retrieval-augmented_generation
- OpenAI GPT: https://openai.com/gpt-4
- Anthropic Claude: https://www.anthropic.com/claude
- Google Gemini: https://gemini.google/