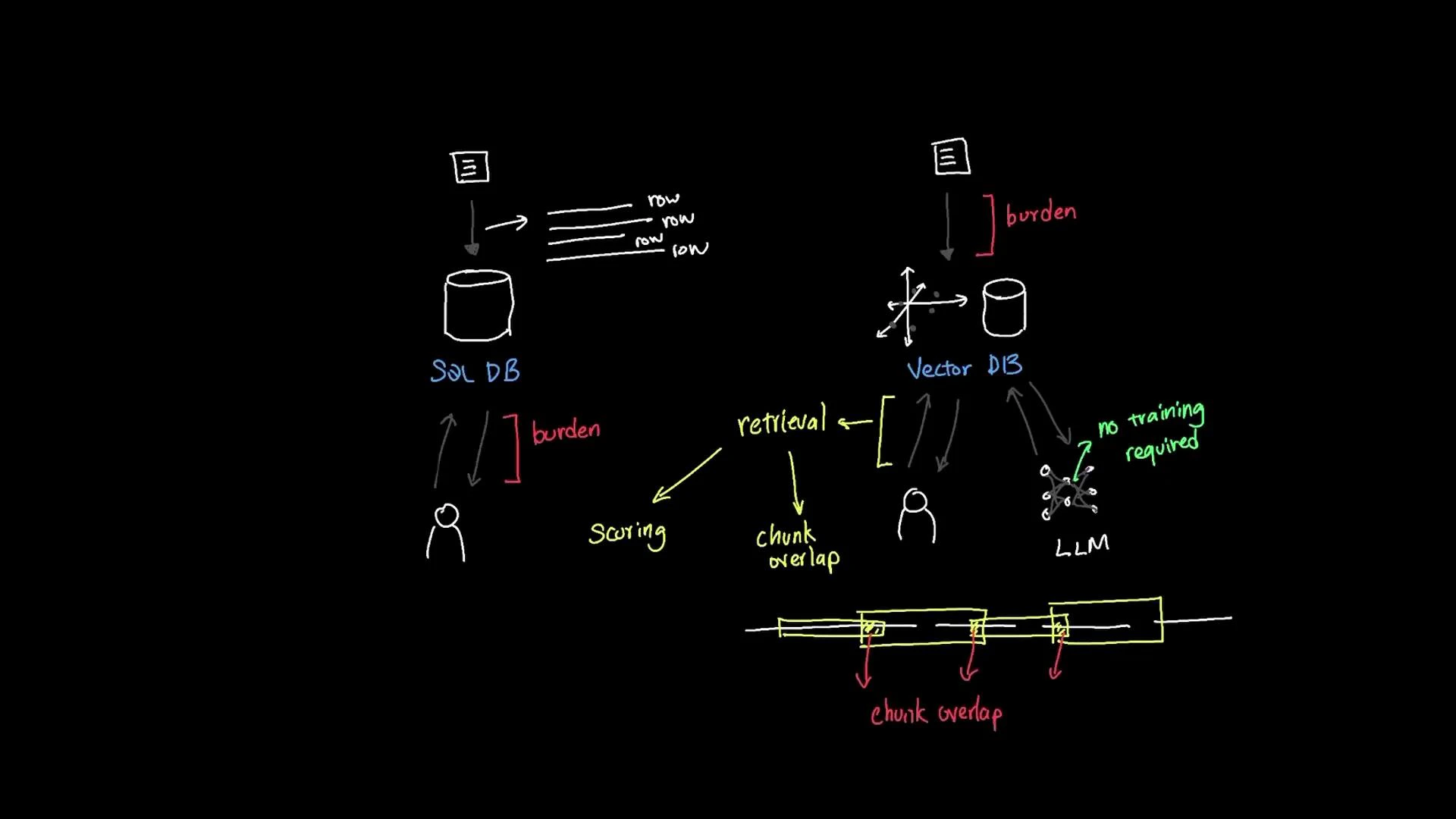
- Suppose the 500 GB dataset contains an employee handbook covering policies like time off, dress code, and equipment use.
- Users may phrase the same intent using different words: “vacation policy”, “time off guidelines”, or “Can I request time off on a holiday?” Keyword-based search often misses relevant content unless the exact words are present.
- SQL and text-index approaches use exact or pattern matching (LIKE, full-text search). Users must guess correct words or rely on manual synonym expansion.
- Drawbacks: brittle to phrasing, requires query engineering, and often produces noisy or incomplete results.
- Embeddings convert text into fixed-length numeric vectors that capture semantic meaning. Related texts (e.g., “vacation” and “holiday”) map to nearby vectors in the embedding space.
- When a user asks a natural language question, the system compares the embedding of the query with document embeddings and returns semantically similar content even if the wording differs.
- This approach is ideal for RAG systems and LLM-driven assistants because it surfaces relevant context without retraining the LLM.
(Also commonly used: FAISS for offline/embedded ANN indexing, Milvus for large-scale open-source vector search.)
Embeddings: turning text into meaning
- Embedding models map text chunks (sentences, paragraphs) to numeric vectors. Similar meanings yield nearby vectors.
- Example workflow:
- Split documents into chunks (paragraphs or sections).
- Call an embedding model to convert each chunk into a vector.
- Store vectors in a vector DB with metadata (source, offsets, timestamps).
- For a user query, embed the query and retrieve the nearest vectors (top-K or above a threshold).
- Benefit: the LLM receives relevant passages for context regardless of exact phrasing.
- Choose dimensionality based on the embedding model you select and the latency/storage budget.
- Common similarity measures:
- Cosine similarity: robust when vectors are length-normalized.
- Dot product: often used for models that produce normalized vectors or when scaling factors matter.
- Index types:
- Exact: brute-force nearest neighbors (slow for large corpora).
- ANN (approximate): e.g., HNSW — trades minimal accuracy for large speed and memory gains.
- Tuning:
- Choose top-K results and/or a similarity threshold to filter noisy matches.
- Too-low thresholds can return loosely related content (false positives); too-high may omit relevant passages.
- Rather than embedding whole documents, split into chunks (paragraphs, sliding windows) and embed each chunk.
- Overlap windows (e.g., 200-token chunks with 50-token overlap) preserve context across boundaries.
- Trade-offs:
- Smaller chunks → more precise matches, but more vectors to store and search.
- Larger chunks → fewer vectors but higher risk of mixing topics and lowering retrieval precision.
Operational considerations and trade-offs
- Design choices: embedding model, dimensionality, chunk size, overlap, similarity metric, ANN configuration, scoring thresholds.
- Costs: storage for vectors, runtime cost of embedding generation, and compute for ANN queries.
- Monitoring: track retrieval precision, false positives, and downstream LLM output quality to iterate on knobs.
- Integration: vector DBs pair well with LangChain-style retrieval chains and RAG pipelines for chatbots and assistants.
- Prototype: use a small subset of documents with an open-source embedding model and Chroma/FAISS to validate chunk size and overlap choices.
- Production: evaluate managed options (Pinecone, managed Milvus) for indexing, scaling, and operational support.
- RAG integration: feed retrieved chunks into your LLM prompt or LangChain retrieval chain and measure answer quality.
When designing a vector-backed retrieval system, treat embedding creation, chunking strategy, similarity metric, and scoring thresholds as tunable knobs. Proper configuration upfront reduces noise in retrieval and improves downstream LLM responses.
- LangChain course
- Fundamentals of RAG
- Pinecone
- ChromaDB
- Kubernetes Documentation (general infra reference)