High-level tip: choose the prompting technique that matches your goal — speed, format consistency, tone, or complex reasoning — and provide explicit constraints (format, length, audience) to get predictable outputs.
Do not commit API keys or secret files to version control. Keep credentials in environment variables or a secure secret store and verify access only from trusted machines.
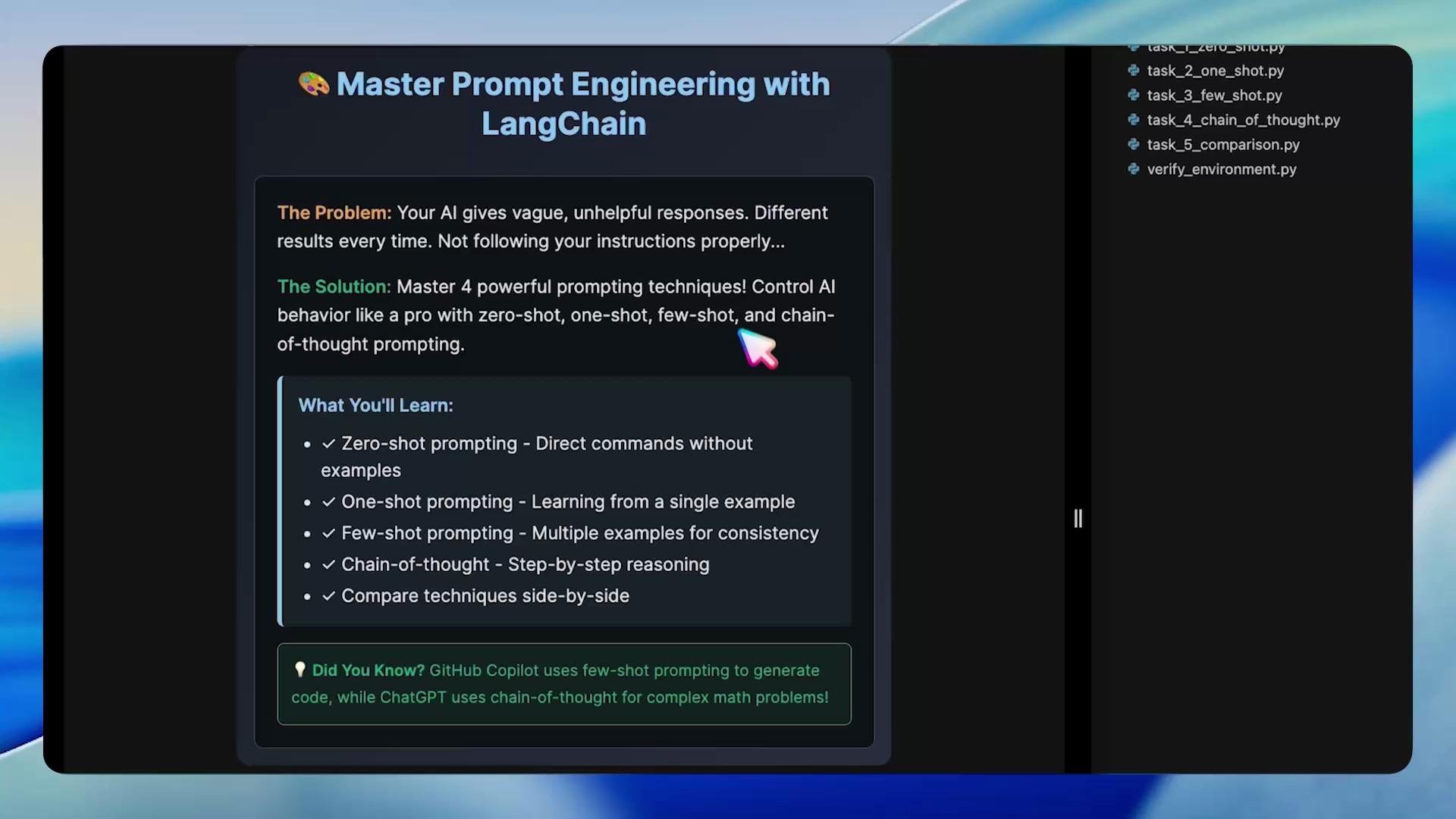
Task 1 — Zero-Shot Prompting
Zero-shot prompting asks the model to perform a task with no examples. The quality of the output depends heavily on how explicit and constrained the instruction is.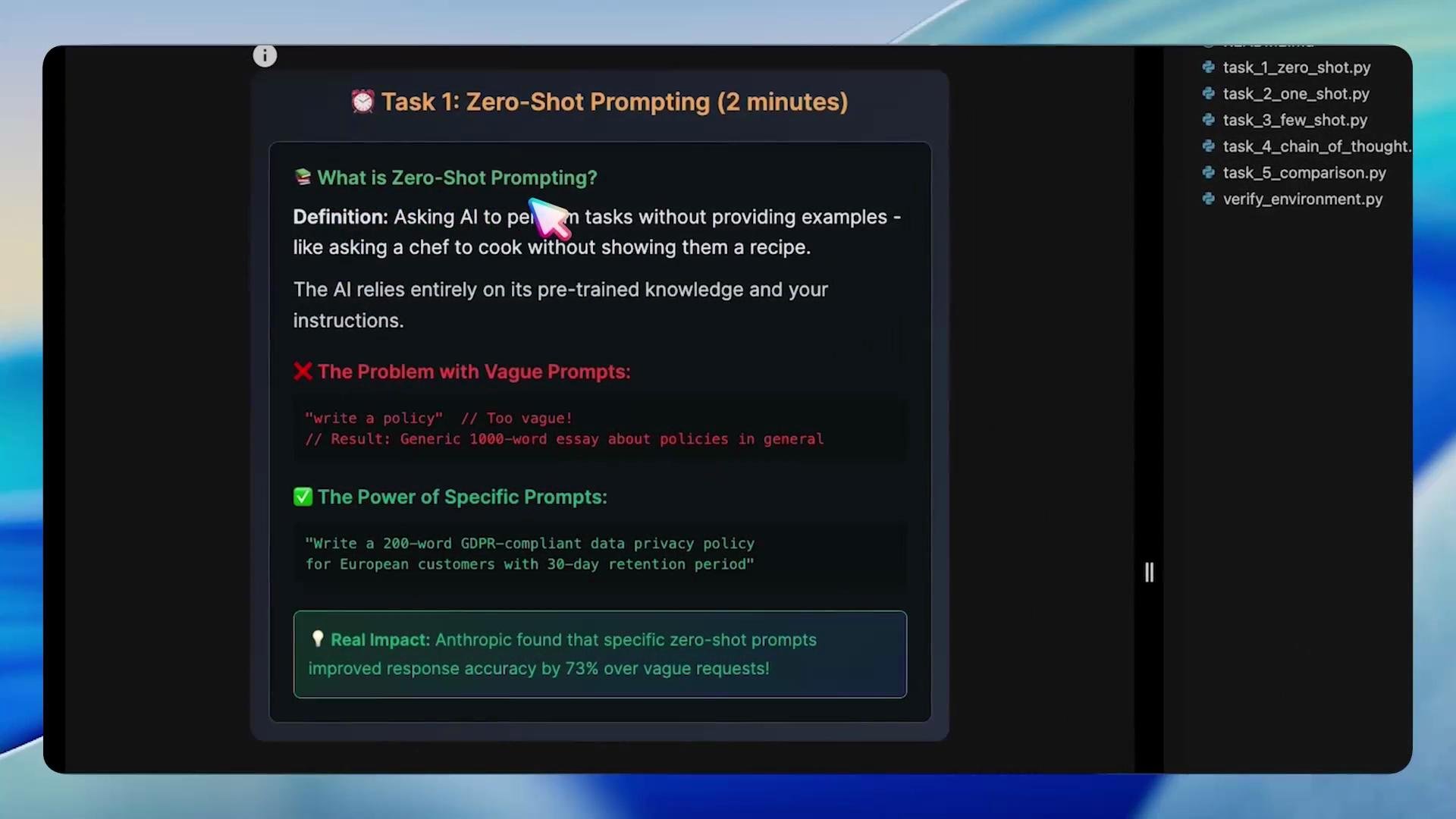
- State the exact task and desired length.
- Define context (jurisdiction, audience, domain).
- List required sections or bullet points the output must include.
- Constrain format where necessary (e.g., JSON, Markdown, or numbered sections).
Task 2 — One-Shot Prompting
One-shot prompting supplies a single example that demonstrates the desired format, tone, or structure. It’s useful when you want the model to reproduce a template or layout across many inputs. Example: Provide a refund policy template as the one-shot example and ask the model to produce a remote work policy using the same structure. One-shot example (refund policy template):- Enforces a single-template formatting.
- Fast to set up for repetitive, structured documents.
- Good when you want to preserve a strict layout without many examples.
Task 3 — Few-Shot Prompting
Few-shot prompting gives the model several diverse examples so it can learn format, tone, and response patterns. This technique is ideal for customer support, marketing copy, or any content that requires consistent voice across variations.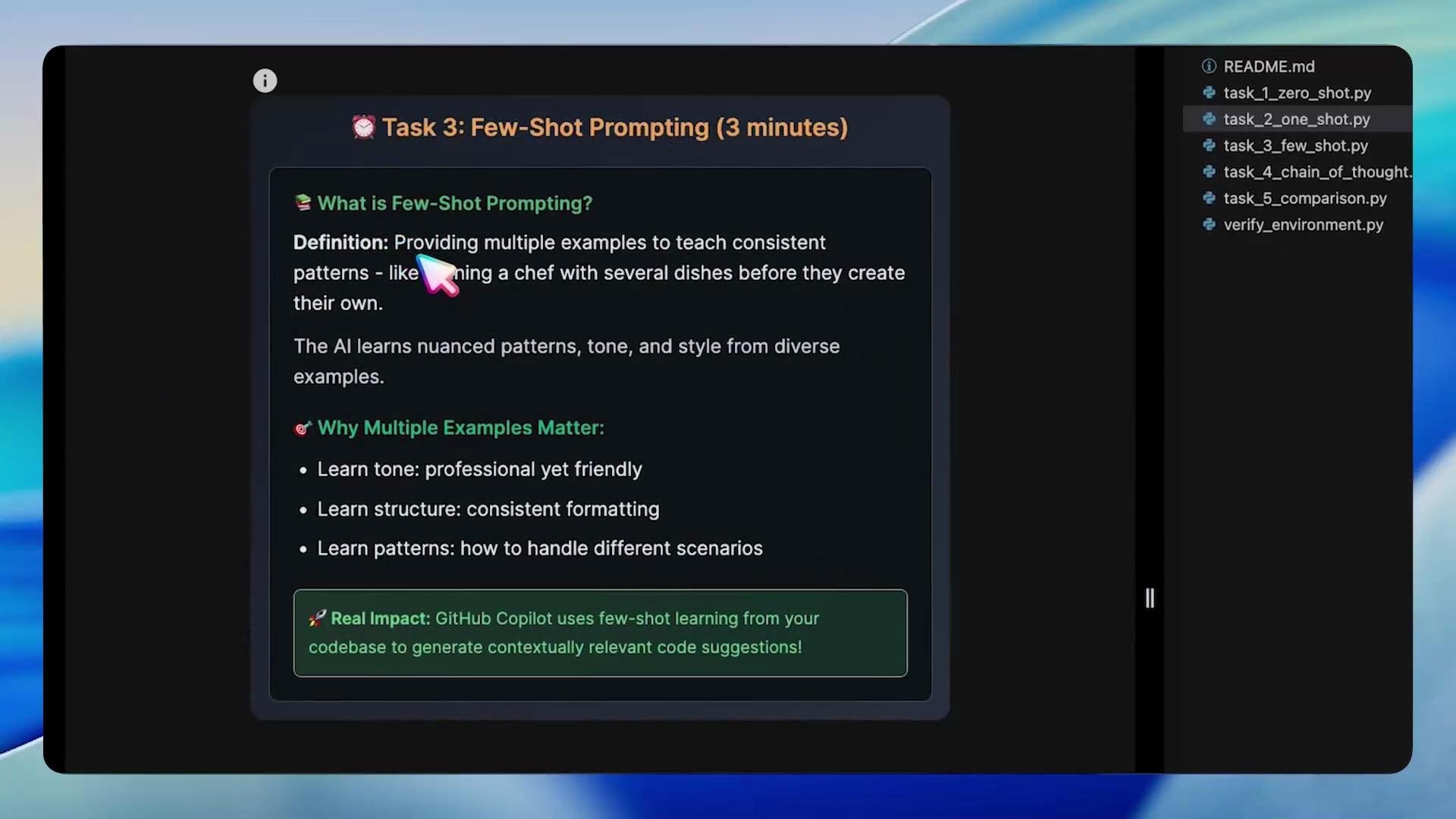
- Learns subtleties of tone and phrasing across examples.
- Keeps responses consistent across agents or channels.
- Reduces need for labeled fine-tuning for many use-cases.
Task 4 — Chain-of-Thought (CoT) Prompting
Chain-of-Thought prompting encourages the model to expose intermediate reasoning steps. This produces more accurate and defensible answers for complex or multi-step tasks. Use CoT when you need the model to enumerate assumptions, weigh options, or provide a stepwise troubleshooting path. Example LangChain prompt templates (fixed and syntactically correct):- Provide worked examples that demonstrate intermediate steps.
- Ask the model to enumerate assumptions and order steps by likelihood.
- Use models/configurations that support longer contexts for full reasoning chains.
- Prefer CoT when correctness and traceability matter.
Task 5 — Technique Showdown (Comparison)
Compare the techniques by running the same task through each style and evaluating differences in structure, tone, and completeness.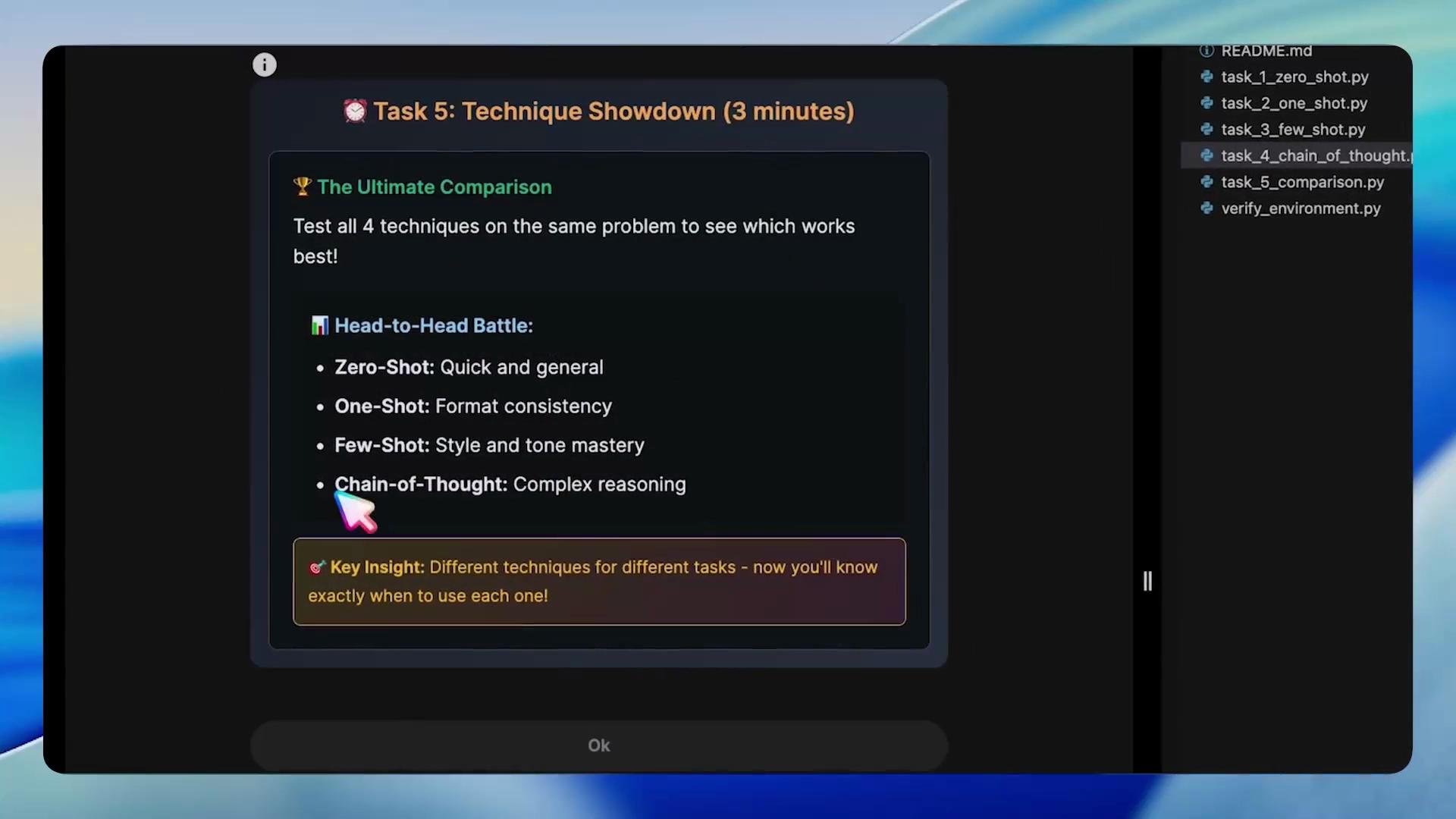
- Zero-Shot: fastest but may miss company specifics or required sections.
- One-Shot: enforces a strict format from a single template.
- Few-Shot: matches tone and variations across multiple examples.
- Chain-of-Thought: produces longer, structured reasoning and more comprehensive policies.
Wrap-up and Practical Tips
By completing these exercises you should now be able to:- Choose the right prompting technique based on goals (speed, format, tone, or reasoning).
- Design explicit constraints (format, length, audience) to get predictable outputs.
- Use One-Shot and Few-Shot prompts to enforce structure and brand voice.
- Use Chain-of-Thought when you need traceable, stepwise reasoning.
- Provide role/context to the model (e.g., “You are an expert HR advisor”).
- Include required sections and constraints.
- Use examples to teach format or tone when needed.
- Keep a simple evaluation rubric (empathy, actionability, timeline) to compare outputs.
- Run the provided tasks in your environment and compare outputs across multiple model sizes.
- Iterate on prompts and evaluate with a small rubric (correctness, format, tone).
- Automate comparisons with simple scripts (as shown in task_5_comparison.py) to measure improvements over prompt versions.