- Remember conversation history
- Access the company knowledge base (documents, FAQs, manuals)
- Handle complex multi-step interactions and take actions when needed
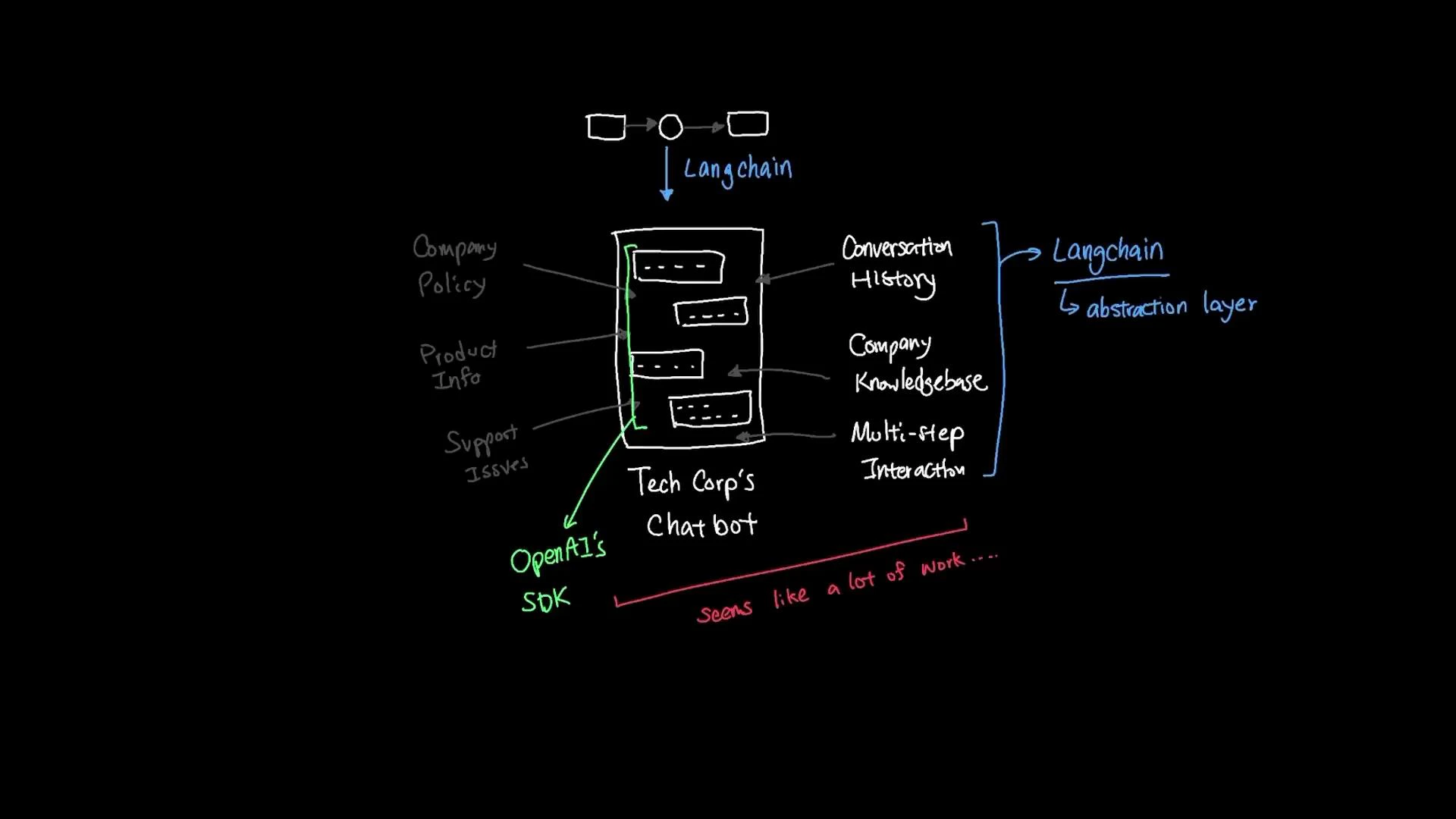
- Retrieve the relevant policy from the company knowledge base,
- Check prior conversation context to confirm whether the customer already provided an order number,
- Call an internal customer-database tool to validate purchase details,
- Open a support ticket if required — without you hard-coding an if/else flow for each step.
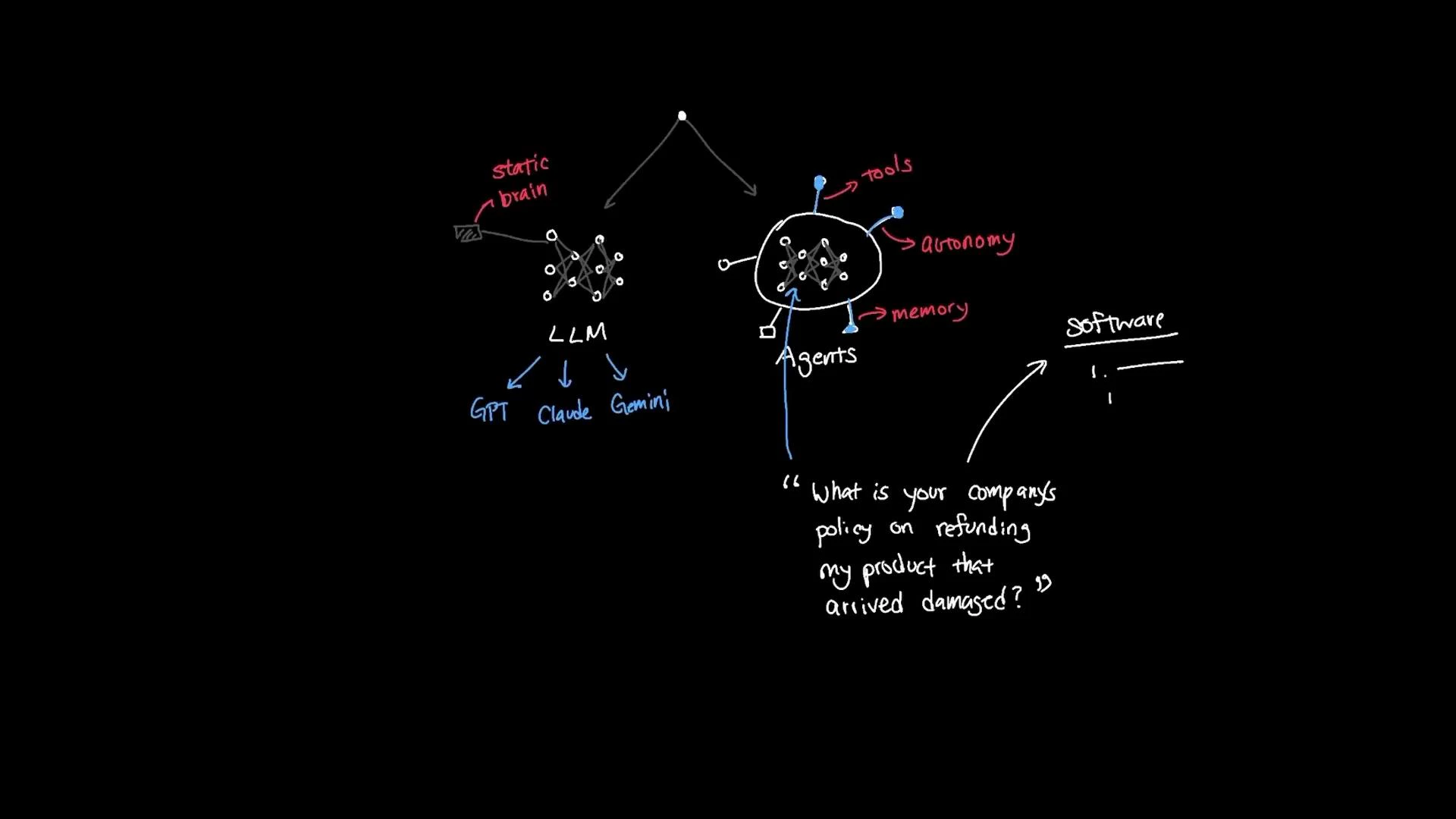
- Chat models: unified interfaces to LLM providers (OpenAI, Anthropic, Google). Switching providers often becomes a single-line change.
- Memory: session-aware memory components to store and retrieve conversation state without implementing a custom schema.
- Vector DB integration: standard adapters for vector databases (Chroma, Pinecone, etc.) so semantic search is consistent across providers.
- Embeddings: standardized embedding components to convert documents into vectors.
- Tools: easy definitions for external tool access (customer DB queries, web search, ticket creation), which agents can call when appropriate.
Putting it together (example)
This concise example shows one way to wire a chat model, embeddings, vectorstore, memory, and a conversational retrieval chain — the core pattern for a retrieval-augmented chat agent. Import paths and class names can change between LangChain releases; check the documentation for your version.
Note: LangChain import locations and class names can change across releases. If an import fails, consult the LangChain docs for your installed version. Also ensure environment variables for provider API keys (e.g., OPENAI_API_KEY, ANTHROPIC_API_KEY) are set before running the code.
- LLM: natural-language reasoning and response generation.
- Embeddings: convert company documents into dense vectors for semantic indexing.
- Vector store / Retriever: performs semantic search over indexed documents and returns relevant context to the agent.
- Memory: holds recent chat history so replies are context-aware and coherent across turns.
- Tools: allow the agent to call external APIs or perform actions (customer DB lookups, ticket creation, web searches).
Warning: Avoid sending sensitive PII or confidential documents to third-party LLMs unless you have contracts and controls in place. Review your data privacy, retention, and compliance requirements before indexing private documents or integrating internal systems.
- Defining your data sources (documents, databases, support tickets).
- Choosing an embedding provider and vector store (Chroma, Pinecone).
- Wiring a conversational chain with memory and a retriever.
- Adding tools for any external actions your agent must perform.
- LangChain — learn.kodekloud course
- OpenAI Docs
- Chroma: https://www.trychroma.com/
- Pinecone: https://www.pinecone.io/
- Retrieval-augmented generation (RAG) overview: https://en.wikipedia.org/wiki/Retrieval-augmented_generation