
Approach overview
We’ll build a production-grade semantic search pipeline by following these core steps:- Convert text (documents and queries) into vector embeddings using an embedding model (sentence-transformers / Hugging Face).
- Store embeddings in a fast vector database (ChromaDB) for nearest-neighbor search.
- For each query, find nearby document embeddings (semantic similarity) and retrieve the top-K chunks.
- Rank and return the most relevant document chunks to the user.
Environment setup
Install the packages used for embeddings, orchestration, and vector storage:- sentence-transformers — embedding models (e.g. all-MiniLM-L6-v2)
- LangChain — orchestration utilities & text splitters
- langchain-community & langchain-huggingface — community integrations for LangChain
- ChromaDB — vector database
- numpy, tempfile, and other utilities

Understanding embeddings
Embeddings are the backbone of semantic search. Rather than working with individual keywords, embeddings convert text into dense numerical vectors where semantically similar texts are close in vector space. That enables the search engine to connect queries and documents that use different words but share meaning.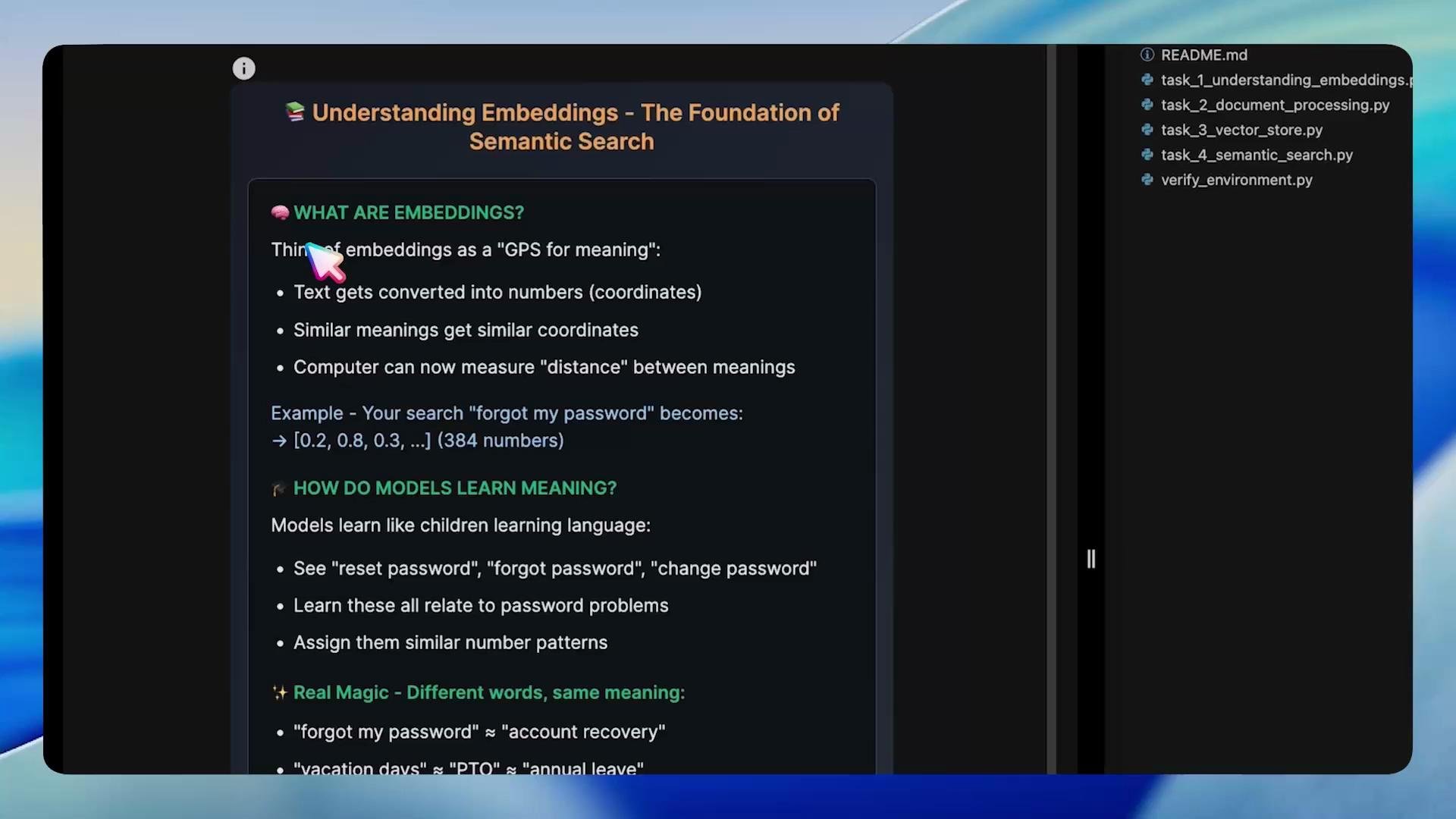
Quick embedding example (Task 1)
This concise example demonstrates loading a sentence-transformers model, encoding a query and several documents, computing cosine similarity, and printing results. Normalizing embeddings (normalize_embeddings=True) can improve cosine-similarity stability.Document chunking
Large documents should be split into smaller chunks for embedding for two reasons:- Embedding models have context limits; extremely long texts can be truncated or produce noisy embeddings.
- Smaller, focused chunks preserve local context and improve retrieval accuracy.
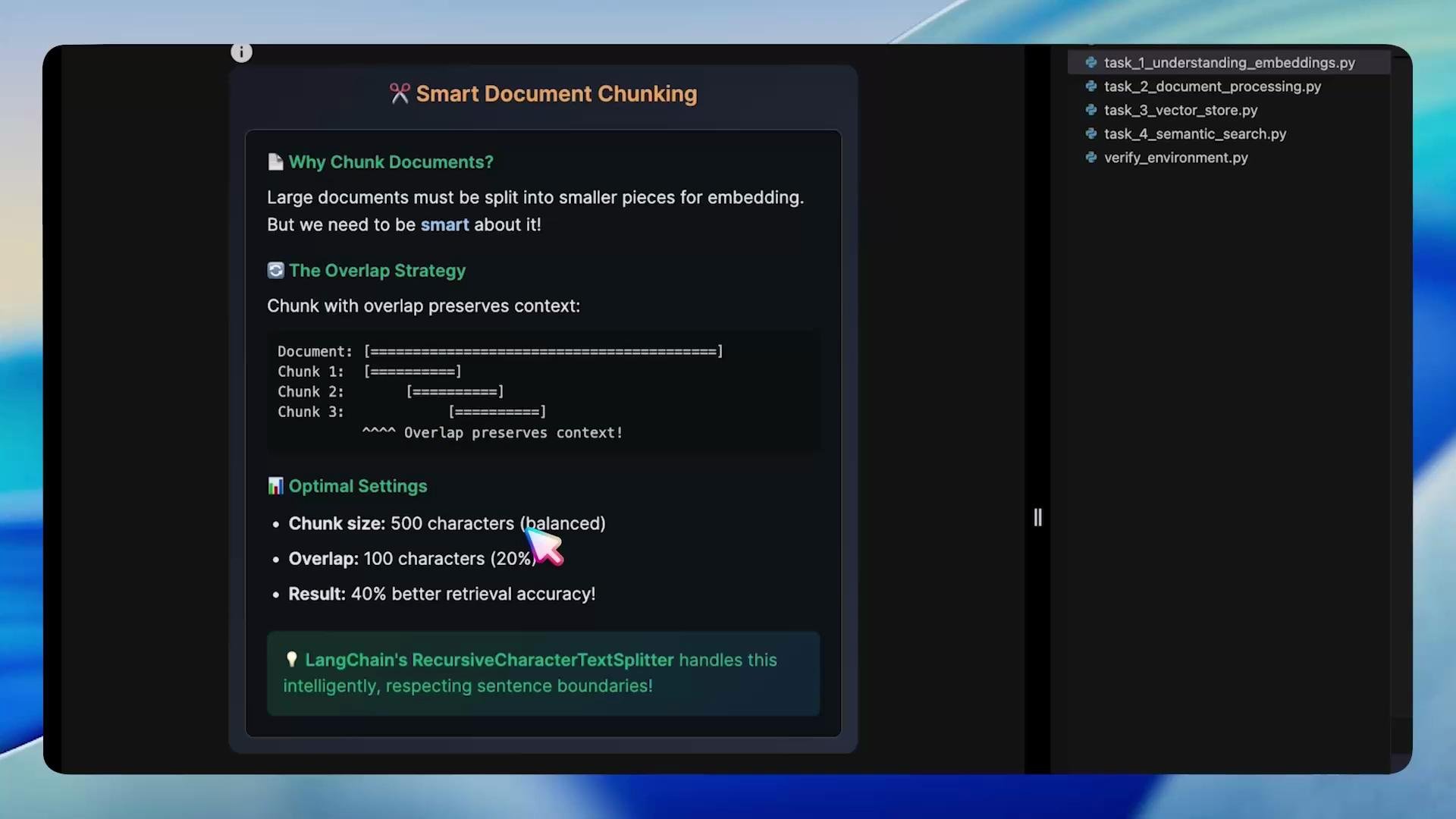
• Preserves sentence boundaries
• Maintains context with overlap
• Optimizes chunks for embedding models
• Can improve retrieval accuracy significantly
• Maintains context with overlap
• Optimizes chunks for embedding models
• Can improve retrieval accuracy significantly
Vector stores (ChromaDB)
Embeddings are vectors; we need a vector store to index and search them efficiently. ChromaDB is a production-ready vector database that supports fast similarity search and metadata filtering. LangChain integrates with ChromaDB to simplify storing and querying embeddings. How vector search works (high-level):- Document → embed → store in DB
- Query → embed → find similar embeddings
- Return top-K results ranked by cosine similarity
Create a Chroma vector store and index documents (Task 3)
This example shows how to initialize HuggingFace embeddings via LangChain, create Document objects, and build a Chroma vector store in a persistent temporary directory.Semantic search — Bringing it all together
Now implement the search pipeline: convert the user query to an embedding, query the ChromaDB vector store for the top-K similar chunks, optionally filter by a score threshold, and return the best results.
Full search example (Task 4)
This example assumes you have a builtvectorstore (as in Task 3). It shows how to run a similarity search, obtain scores, apply a threshold, and print filtered results.
Recap & next steps
In this lab we:- Set up an environment for embeddings and vector search.
- Learned how embeddings capture semantic similarity beyond keywords.
- Implemented smart, overlapping document chunking.
- Built a ChromaDB-backed vector store and indexed document chunks.
- Implemented a semantic search pipeline that converts queries to embeddings, performs similarity search, and returns ranked, filtered results.
- Try different embedding models (speed vs. accuracy tradeoffs).
- Tune chunk sizes and overlap parameters based on document structure.
- Persist vector stores to a stable location and design a scalable deployment.
- Add metadata filtering (document type, last-updated) and combine with a ranker or reranker for hybrid retrieval.
Next steps: experiment with model variants, tune chunking/thresholds, and add metadata filters (e.g., document type, last-updated) to further improve relevance.
Tools & resources
Further reading:
- Kubernetes Basics (for deploying scalable services)
- LangChain Documentation
- ChromaDB Docs