- Make your first AI API call and understand modern model interactions.
- Build and deploy AI features using agent frameworks and prompt engineering best practices.
- Implement vector databases and a semantic search engine for technical documentation to retrieve by meaning rather than keywords.
- Combine retrieval and generation using Retrieval-Augmented Generation (RAG) for more accurate, context-aware outputs.
- Design stateful, graph-based workflows and agents that remember, reason, and react over time.
- Extend workflows with external tools, observability, and production-ready safety patterns.
First steps — verify your environment
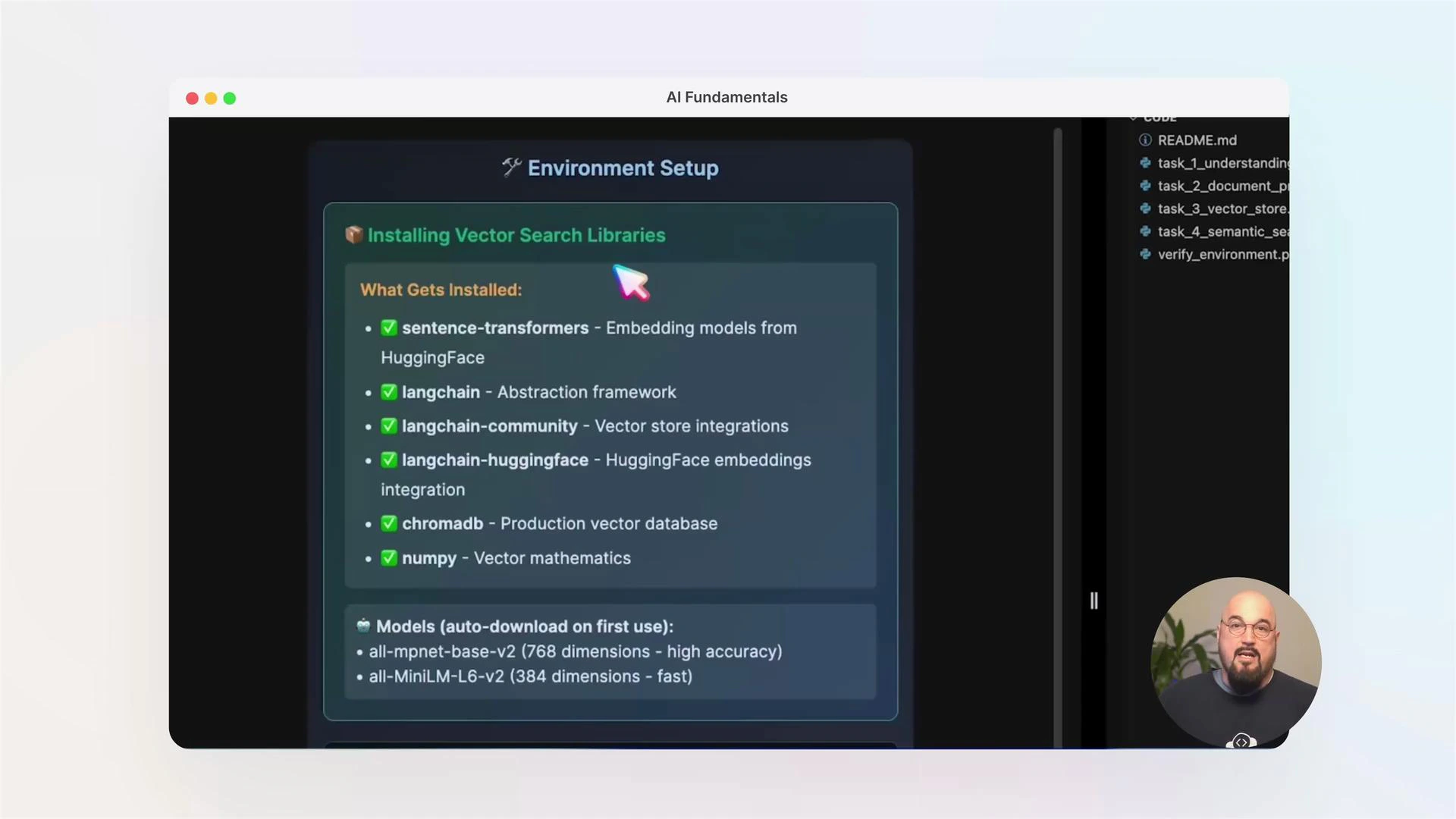
Before you run labs, activate your virtual environment and ensure required packages are installed. Typical packages used in these labs include langchain, chromadb, sentence-transformers, numpy, and related dependencies.
Run this simple verification command after activating your venv:
Make sure your virtual environment is activated before running verification or lab scripts. If you created the venv in a different path, update the
source command to point to your activate script.- LangChain — orchestration of prompts and chains
- ChromaDB / Chroma — lightweight vector database options
- sentence-transformers — high-quality embedding models
- numpy — numerical operations for preprocessing
- Additional tooling: Docker, cloud object stores, monitoring/observability tools (for advanced labs)
- Ingest documents (split into passages / chunks).
- Compute embeddings with a suitable encoder (e.g., sentence-transformers).
- Store embeddings in a vector store (ChromaDB, FAISS, Milvus, etc.).
- Query by embedding for nearest neighbors, then re-rank or filter before use.
- User query → embedding → nearest-neighbor documents → concat or summarization → conditioned generation

- Integrate external tools (APIs, databases, search) into graph workflows.
- Add observability and logging for debugging and auditing agent behavior.
- Apply safety patterns and guardrails (rate limits, input sanitization, rejection sampling).
- Compose multi-step flows and orchestrate complex agent behavior suitable for production.
- LangChain: https://docs.langchain.com/
- Chroma (ChromaDB): https://www.trychroma.com/
- sentence-transformers: https://www.sbert.net/
- Retrieval-Augmented Generation (overview): https://en.wikipedia.org/wiki/Retrieval-Augmented_Generation