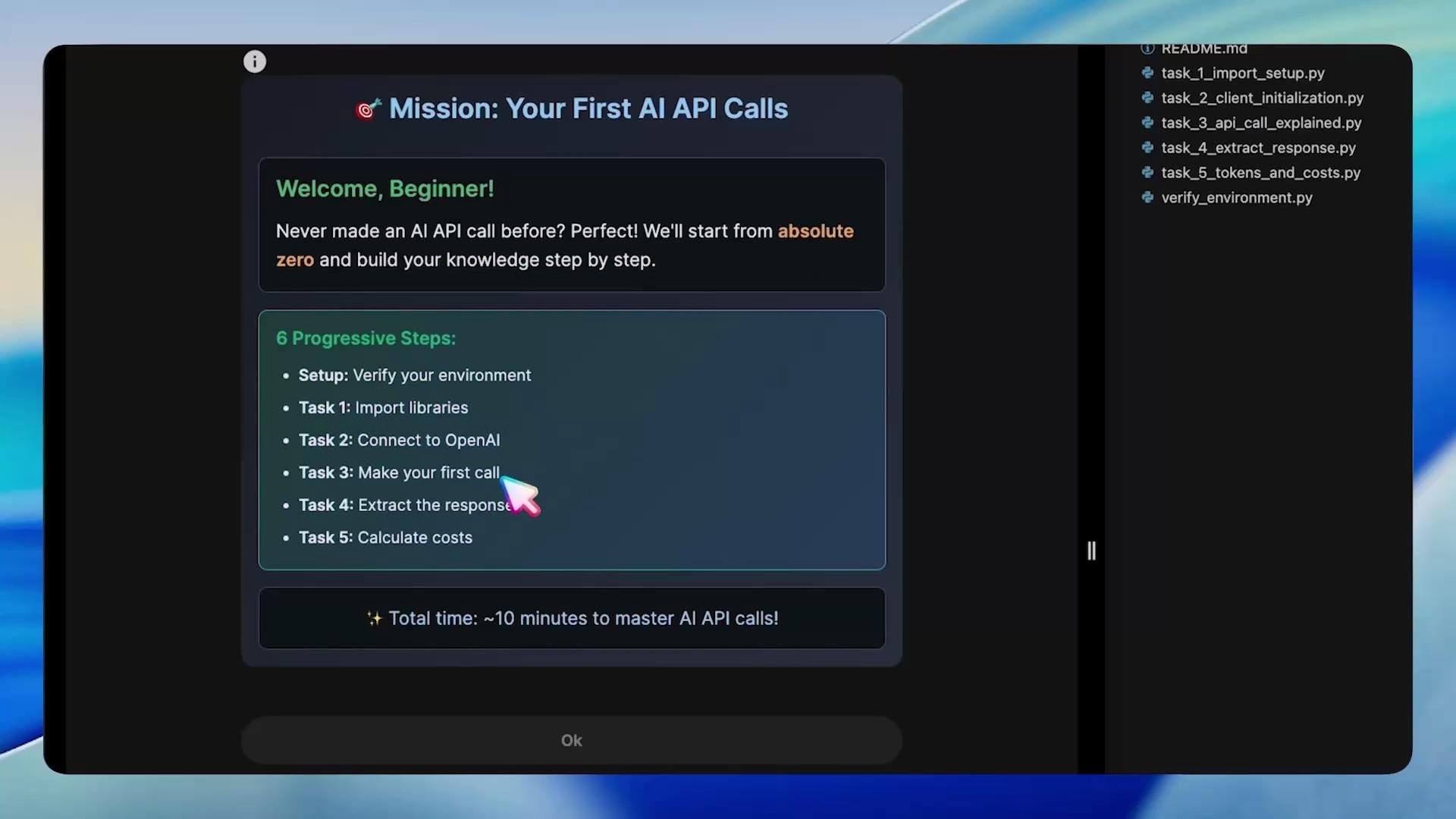
1 — Verify the environment
Before writing code, verify that your runtime is ready: activate the virtual environment, confirm Python is available, ensure the OpenAI package is installed, and verify your API keys are present. Run these commands in the lab VM:What is OpenAI?
OpenAI builds ChatGPT and families of large language models (e.g., GPT-4, GPT-4.1 Mini, GPT-3.5). The OpenAI Python client is the bridge between your Python code and the API.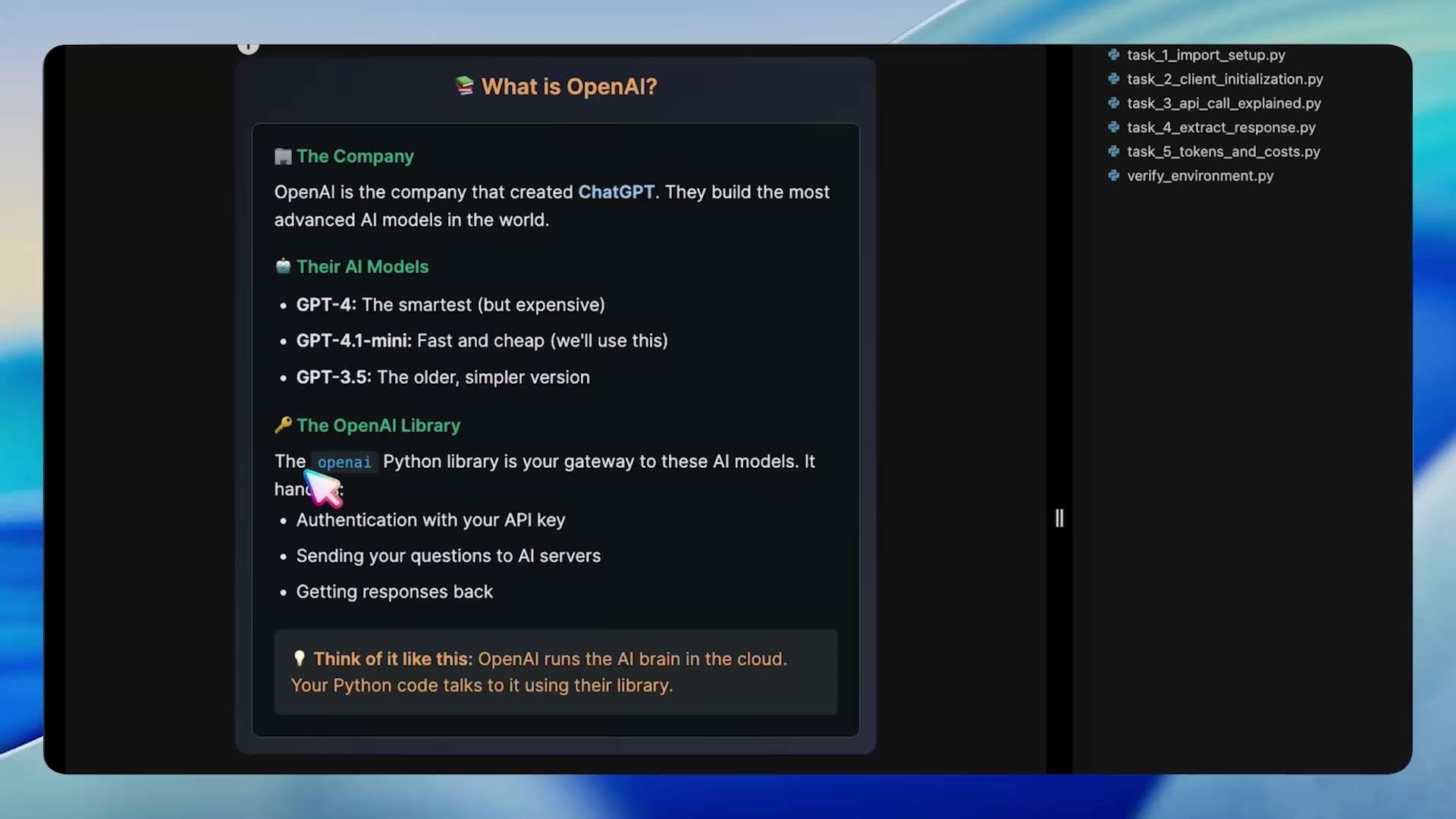
Task 1 — Import required libraries
Opentask_1_import_setup.py. You need to import the OpenAI client library and the os module to read environment variables. The following file shows the required imports and writes a completion marker for the lab system.
Authentication and client setup
To authenticate you need:- OPENAI_API_KEY — your secret API key
- OPENAI_API_BASE — (optional) custom API base URL
Task 2 — Initialize the OpenAI client
Opentask_2_client_initialization.py and initialize the OpenAI client using environment variables. This example creates a client object you can reuse across requests.
Chat completions — the basics
Chat completions implement conversational interactions. You send an ordered list of messages (with roles) and the model returns assistant messages. Minimal Python pattern:- system — high-level instructions that define behavior
- user — user input
- assistant — model replies
Task 3 — Make an API call
Opentask_3_api_call_explained.py. Configure the model and messages, then make a call where the AI introduces itself.
Task 4 — Extract the AI’s response
Responses contain nested structures. The straightforward path to the assistant’s reply is:task_4_extract_response.py to extract and print that text.
Tokens and costs
Tokens are the billing and processing unit used by models. Every request consumes tokens from your account:
Output tokens are often priced higher than input tokens, so being concise helps control costs.
Keep your API key secure. Never hard-code it in scripts or check it into version control. Use environment variables or a secrets manager.
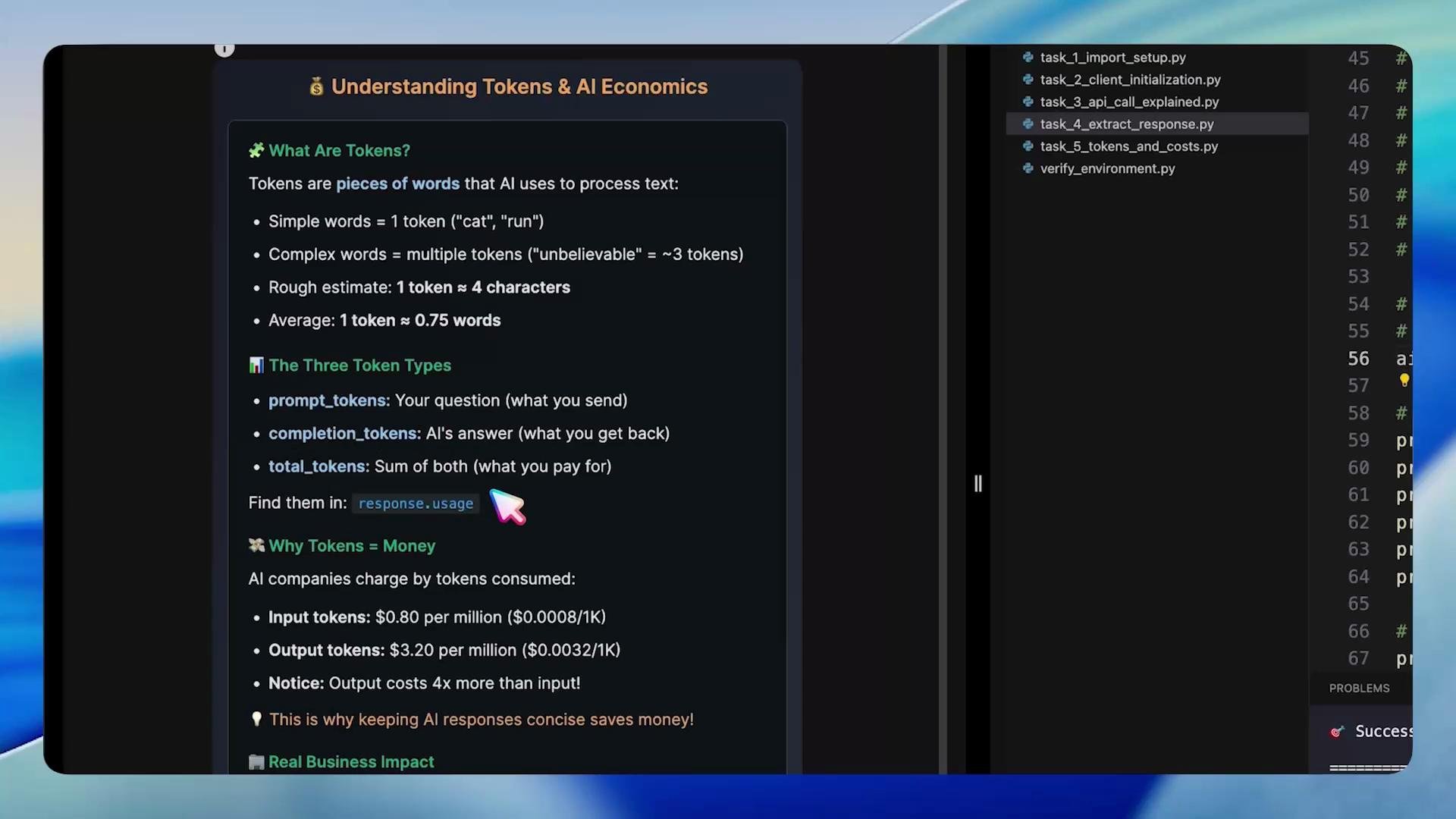
Task 5 — Extract token usage and compute cost
Opentask_5_tokens_and_costs.py. The response includes a usage object with three fields: prompt_tokens, completion_tokens, and total_tokens. Use these values to compute a simple cost estimate with your per-token pricing.
Be careful with long model responses or high-frequency calls — costs can add up quickly. Use concise prompts, set max tokens when needed, and monitor usage.
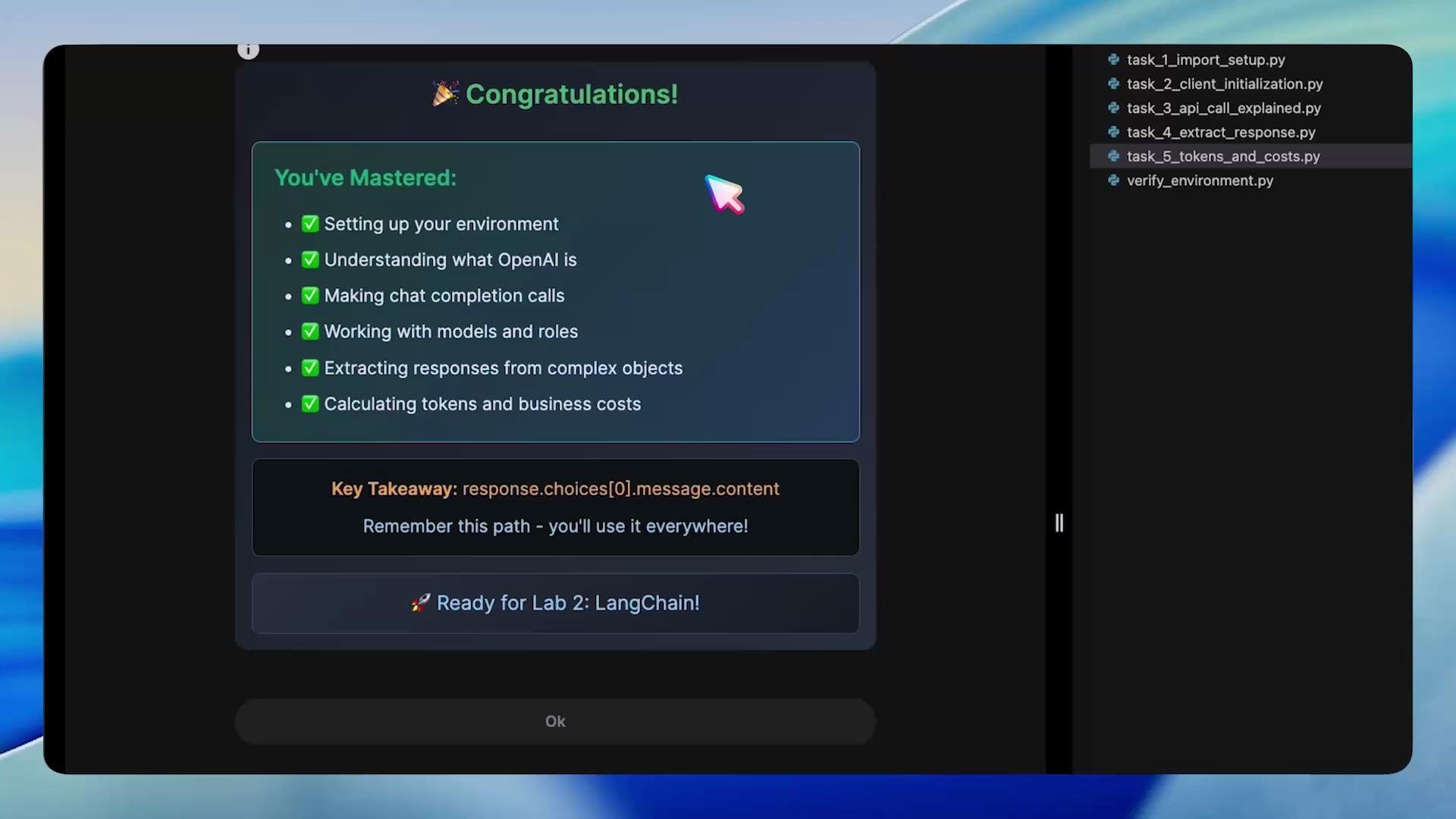
Wrap-up
Congrats — by completing this lab you:- Verified your environment and runtime
- Initialized the OpenAI Python client
- Made chat completion requests
- Extracted assistant replies via response.choices[0].message.content
- Read token usage and estimated costs
Quick reference and links
- OpenAI API docs: https://platform.openai.com/docs
- OpenAI homepage: https://openai.com
- LangChain (multi-provider tooling): https://learn.kodekloud.com/user/courses/langchain
You’re ready to build on this foundation and explore richer prompts, system instructions, and multi-turn dialogues. Good luck!