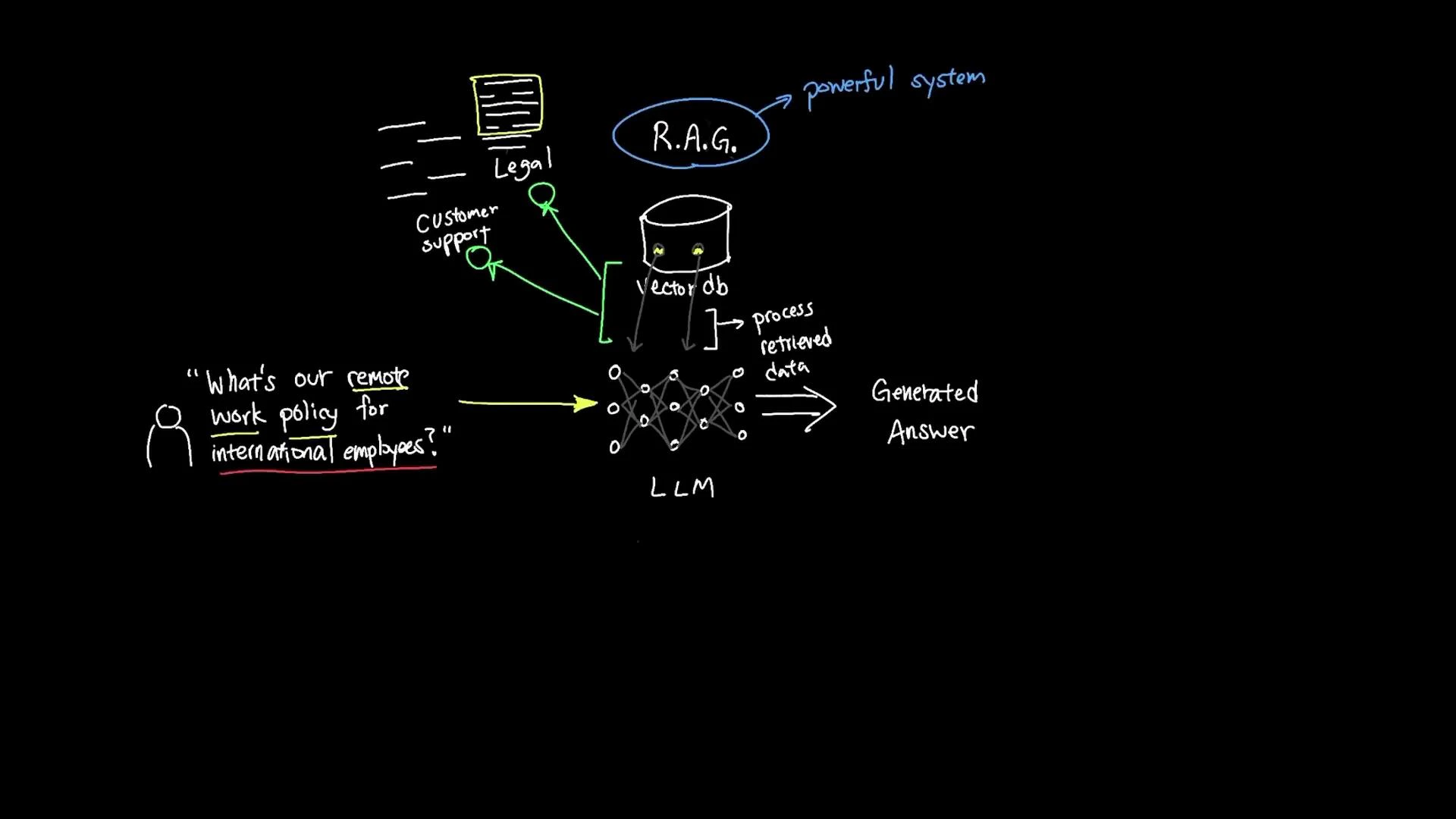
With RAG, the assistant locates the exact policy passages and uses them to produce a targeted, current response. RAG can be understood as three sequential steps: Retrieval, Augmentation, and Generation.
1) Retrieval
- Convert documents and the incoming user question into vector embeddings.
- Compare the query embedding against stored document embeddings in a vector database using semantic similarity.
- Return the top-matched documents or document chunks (not simple keyword matches — the search finds semantically related passages).
2) Augmentation
Augmentation injects the retrieved text snippets into the model’s prompt at runtime. Typical augmentation steps:- Select the top-k passages returned by the vector search.
- Optionally filter or re-rank passages by metadata, recency, or source trust.
- Insert these passages into a prompt template so the LLM can reference them while generating an answer.
RAG usually avoids costly model fine-tuning: you provide retrieved context at runtime so a base LLM can generate accurate answers using up-to-date, private data without being retrained.
3) Generation
- The LLM receives a prompt that includes the user question plus the retrieved context.
- The model synthesizes information from those passages and its own knowledge to produce a coherent, accurate answer tailored to the query (for example, applying policy details to “international employees”).
Why RAG matters
- Extends an LLM’s effective knowledge beyond its training cutoff by supplying current documents at query time.
- Enables private, domain-specific answers without embedding proprietary data into model weights.
- Preserves context fidelity by surfacing the exact passages used to answer a question, improving traceability and trust.
Calibrating and designing a RAG system
Getting reliable outputs requires careful design and iterative tuning. Key factors include chunking, retrieval size, scoring, and prompt templates.
Common engineering considerations:
- Preserve important structure (headings, numbered lists, dates) when chunking.
- Store metadata (source, timestamp, author) with embeddings for filtering and auditing.
- Use recency or source trust to weight retrievals when answers must favor the latest policy or authoritative documents.
- Evaluate with end-to-end metrics: precision/recall of retrieved passages, hallucination rate, and human feedback loops.
Implementation resources
- Vector databases and similarity search: Pinecone, Weaviate, Milvus
- Embeddings and semantic search guides: OpenAI Embeddings, semantic search overview
- Prompt design and safety: best practices for context injection and hallucination mitigation