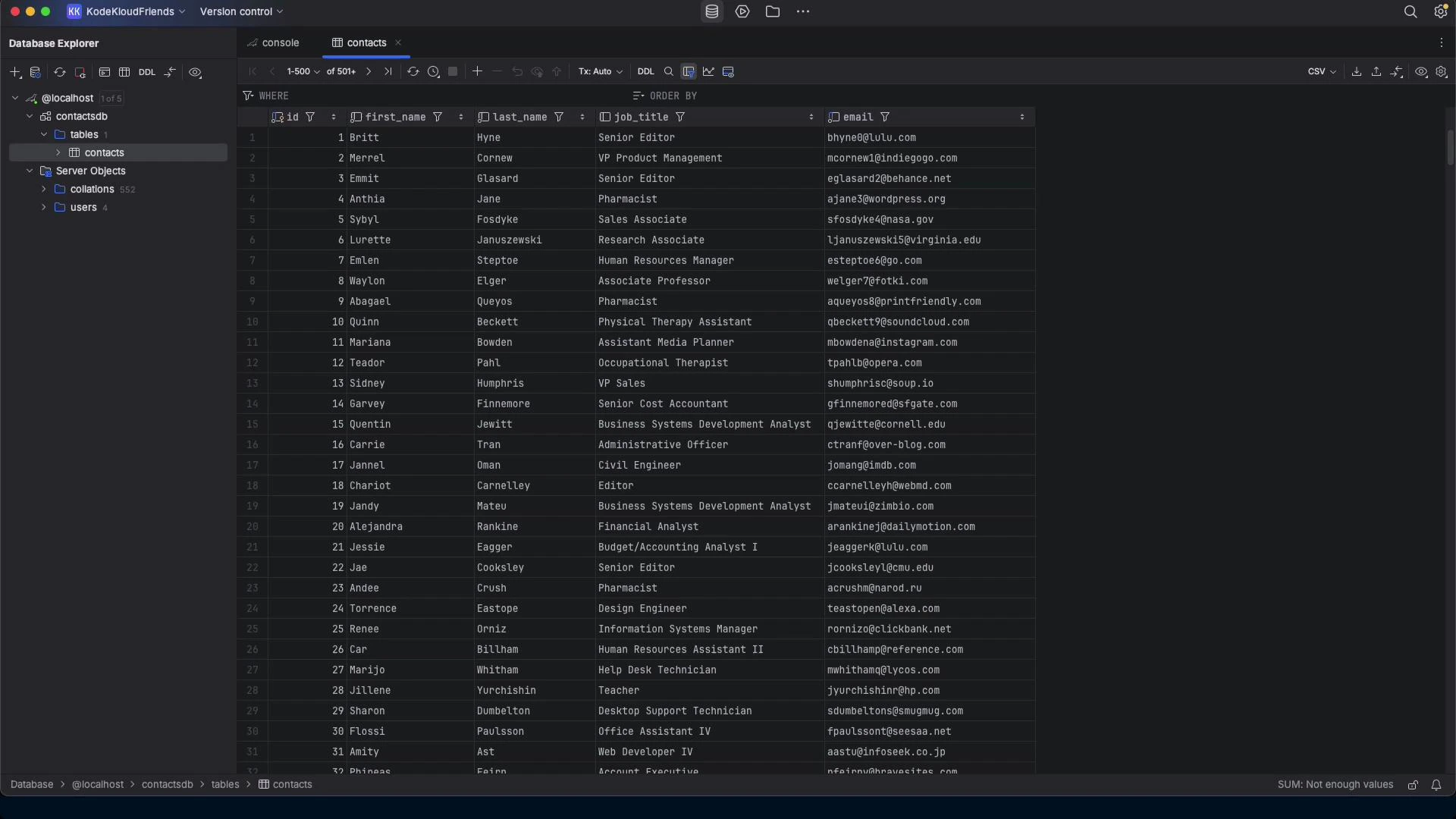
Scenario
- Source: local MariaDB server with a contacts table (id, first_name, last_name, job_title, email).
- Target: a single SQLite database file (contacts.db) containing the same rows and a mapped schema.
- Motivation: reduce operational complexity for small/low-traffic databases by moving to SQLite.
- Detect schema and map types with sensible defaults.
- Export rows safely and import into SQLite using parameterized inserts.
- Produce .sql artifacts for auditing and replay.
- Verify migration (row counts and spot checks).
Prompt‑first workflow
- Try a concise instruction and let the model propose a plan.
- If that plan is brittle or incomplete, request a production-quality script (Python) implementing:
- Schema discovery (INFORMATION_SCHEMA),
- Type affinity mapping,
- Safe data export/import with parameterized queries,
- Optional CLI args and logging,
- Simple verification (row counts),
- Optional output .sql files for auditing.
Example detailed requirements (used to generate the final script)
- Environment & dependencies:
- Language: Python 3.10+
- Connectors: mysql-connector-python (or pymysql) + stdlib sqlite3
- Optional: click (CLI), tqdm (progress), tenacity (retries)
- Script requirements:
- Run locally; accept connection via CLI args or environment variables
- Detect server version and charset
- Discover schema: tables, columns, nullability, defaults
- Primary keys/unique keys/indexes; document foreign keys, views, triggers
- Export data safely and import into SQLite with parameterized queries
- Emit .sql artifacts for auditing/replay
- CLI args (examples): —mysql-host, —mysql-port, —mysql-user, —mysql-password, —mysql-db —sqlite-path, —output-dir, —force-overwrite
MariaDB → SQLite: Type mapping (approximate)
Note: SQLite uses type affinity, so these are pragmatic mappings rather than exact conversions. Document and review columns with special constraints (e.g., unsigned integers, auto-increment semantics).
Practical run — repository inspection and initial interaction
The model inspected repository files (contacts CSV, contacts_data.sql, migration.md) and asked for connection info. Never share production credentials in untrusted environments — use a local test account or pass secrets at runtime.Do not share production credentials or secrets in an environment you do not control. Use local test credentials or create scripts that accept credentials at runtime (environment variables or interactive input) rather than embedding secrets in chat history or files.
Initial inspection & mysqldump
Quick inspection commands the model proposed: Inspect table schema:Why quick shell-based piping is brittle
A naive pipeline that reads mysql tab-separated output and pipes it into sqlite3 (with sed and shell parsing) often fails on real data: names with apostrophes, embedded tabs, newline characters in text fields, or other quoting issues break the parsing and produce invalid SQL. Example brittle approach (DO NOT use in production):Safer approach: Python migration script with parameterized queries
A robust approach uses a Python script that:- Reads rows via a MariaDB client (mysql-connector-python or pymysql),
- Inserts rows into SQLite using parameterized queries to avoid quoting/injection issues,
- Creates a minimal SQLite schema with mapped types,
- Optionally writes .sql files for auditing.
- Expand the script to discover schema programmatically (INFORMATION_SCHEMA) if migrating multiple or unknown tables.
- Add CLI parsing (click/argparse) and optional logging for production use.
- Optionally write INSERT statements to .sql files for auditing or replay.
Environment setup
Create and activate a virtual environment, then install the connector:Verification
Verify row counts and sample rows after migration. Row count comparison:Artifacts and repeatability
For repeatability and auditing, keep:- The migration script (migrate.py),
- The mysqldump (contacts_data.sql) or generated .sql insert files,
- The detailed prompt or runbook describing how the migration was performed.
Inspect the resulting SQLite database
Open contacts.db in a GUI such as DB Browser for SQLite to inspect schema, indexes, and rows.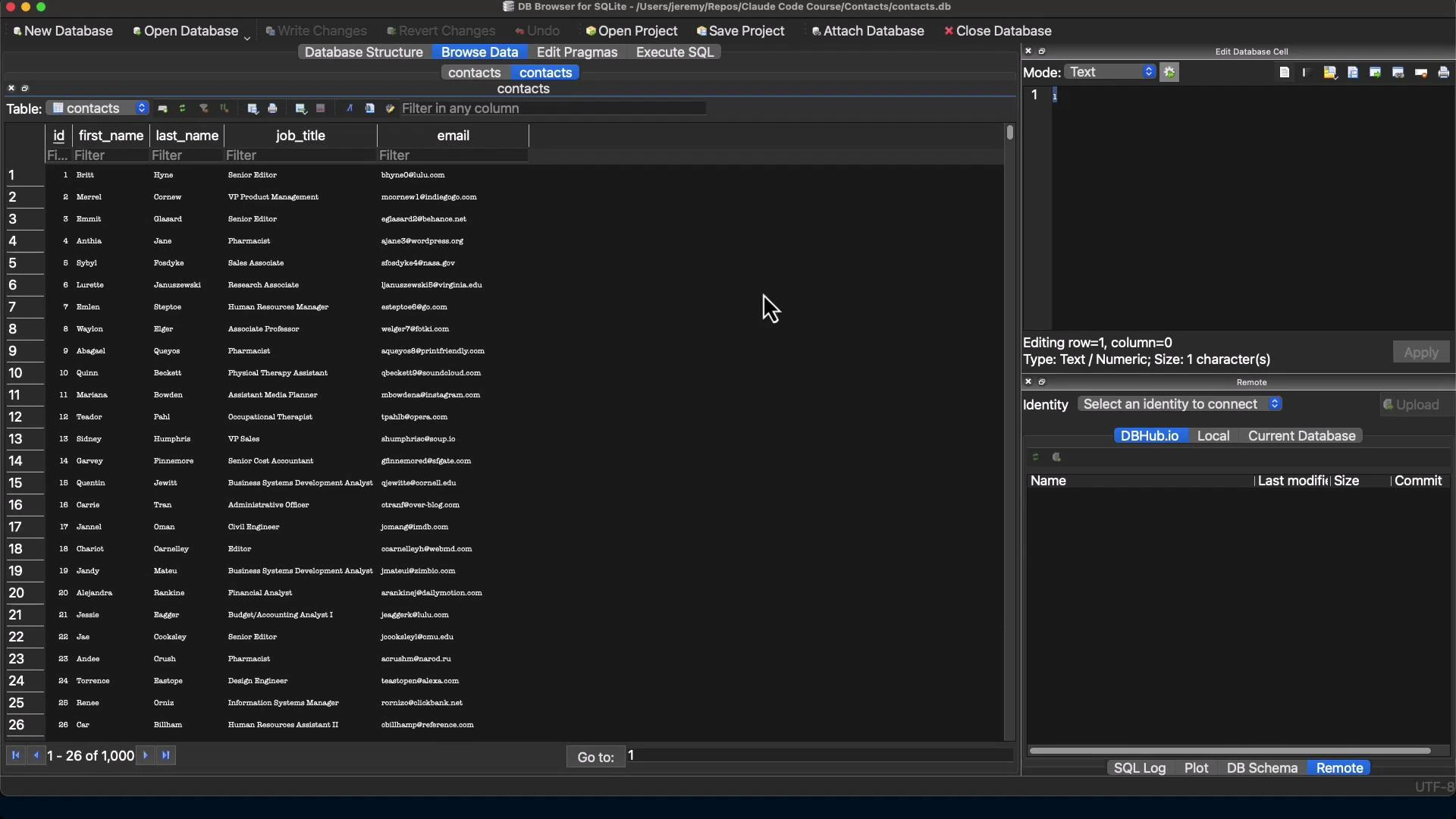
Summary and practical notes
- For simple tables, a compact Python script using mysql-connector-python + sqlite3 is reliable and avoids quoting pitfalls.
- For complex schemas (foreign keys, triggers, stored routines), plan for manual mapping or schema redesign; SQLite lacks some MariaDB features.
- Always test migrations in a sandbox and verify row counts and spot-check data.
- Prefer parameterized queries to avoid quoting and injection issues.
- Keep a dump (.sql) or TSV export for auditing and replay.
Links and references
- MariaDB Documentation
- SQLite Documentation
- DB Browser for SQLite
- Kubernetes Documentation — for related infra topics
- Python mysql-connector-python on PyPI