How KEDA Leverages CPU Metrics
KEDA integrates with the Kubernetes HPA to fetch CPU metrics and make scaling decisions. The following diagram illustrates the flow: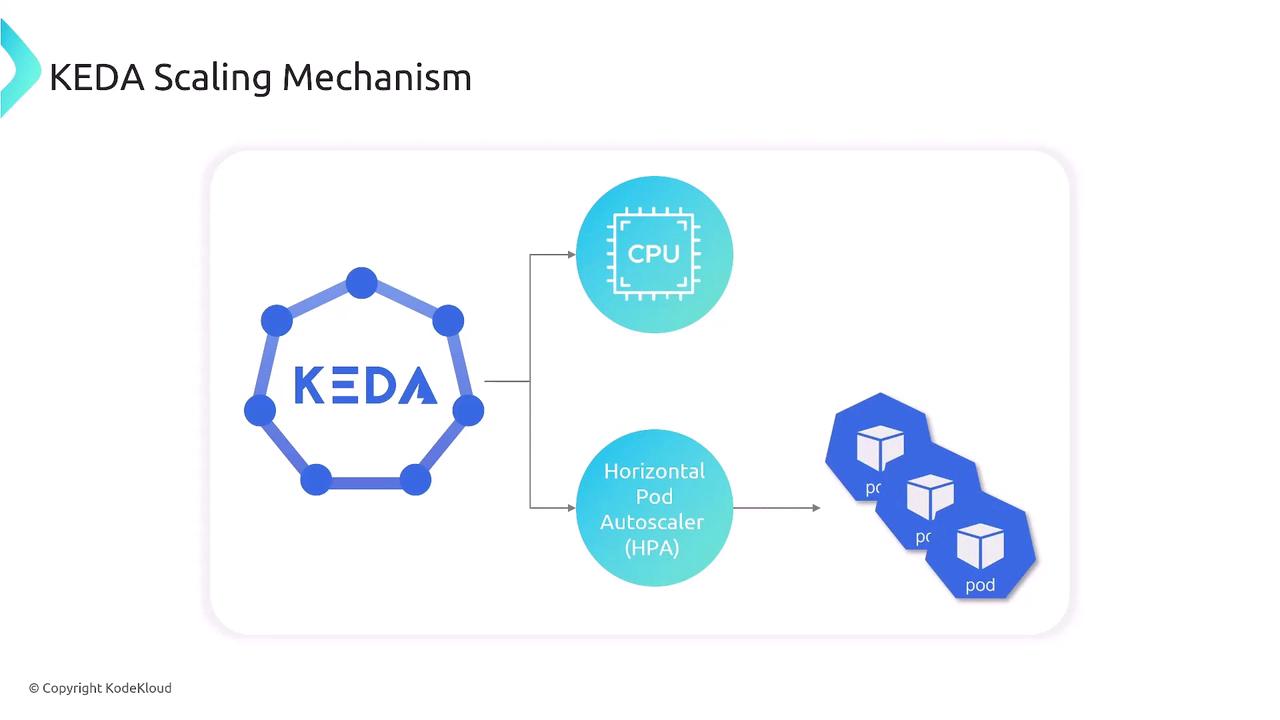
- Metrics Server exposes CPU usage for each pod.
- HPA retrieves metrics and compares against defined thresholds.
- KEDA’s ScaledObject configures HPA targets and min/max replica counts.
- Pods scale out/in based on real-time CPU usage.
Prerequisites
Before you begin, ensure your cluster meets the following requirements:- Metrics Server is deployed and operational.
- Pods specify CPU
requests(and optionallylimits) to enable accurate metrics. - Kubernetes v1.27+ or compatible version for HPA and Custom Metrics API.

Defining CPU Requests in Your Deployment
Specify resource requests and limits in your Deployment manifest so the Metrics Server can report CPU usage correctly:Defining CPU
requests ensures the HPA can calculate utilization percentages. If no limits are set, pods can burst beyond the request but HPA will still use the request as the baseline.Configuring the CPU Trigger in KEDA
KEDA supports two CPU trigger modes:| Mode | Description |
|---|---|
| Utilization | Percentage of CPU request (e.g., 50 for 50% usage) |
| AverageValue | Absolute CPU value in millicores (e.g., 250m) |
If your pods include sidecar containers (e.g., logging, service mesh), set
containerName to your main application container to avoid scaling based on sidecar CPU usage.Creating the ScaledObject
AScaledObject ties your Deployment to KEDA’s scaling logic. Below is a sample manifest that scales cpu-app between 1 and 5 replicas when CPU utilization exceeds 50%:
Summary of Key Resources
| Resource | Purpose |
|---|---|
| Metrics Server | Exposes CPU/memory metrics to the Metrics API |
| Deployment | Defines pod spec with CPU requests & limits |
| ScaledObject | Configures KEDA triggers and HPA parameters |
| HPA | Executes the scaling logic based on CPU metrics |