Welcome to this lesson on Kubernetes Event-Driven Autoscaling (KEDA). In modern cloud-native environments, workloads often experience unpredictable spikes. Traditional autoscalers like HPA, VPA, and CPA address CPU, memory, or infrastructure scaling, but they fall short when you need real-time, event-driven reactions or scale-to-zero capabilities. Here, we’ll explore how KEDA bridges that gap and empowers your Kubernetes clusters for true event-driven scaling.
Before diving into KEDA, let’s quickly recap the built-in Kubernetes autoscaling options.
Kubernetes Autoscaling Options Recap Autoscaler Scale Type Metrics Scale to Zero HPA Horizontal Pods CPU, memory, custom, external metrics No VPA Vertical Pods Adjusts CPU/memory requests per pod N/A CPA Cluster Services Node count or CPU cores (proportional) No
Horizontal Pod Autoscaler (HPA) HPA automatically adjusts the number of pod replicas in a Deployment or ReplicaSet based on observed metrics:
Metrics supported : CPU, memory, custom, externalPolling interval : ~15 s by default
Advantages:
Built into Kubernetes, minimal setup for CPU/memory
Automatically adjusts replica count under load
Extensible via custom or external metric adapters
Disadvantages:
Cannot scale down to zero (at least one replica always exists)
Limited to predefined thresholds and polling intervals
Custom metrics require additional adapters
Event-driven triggers can be complex to integrate
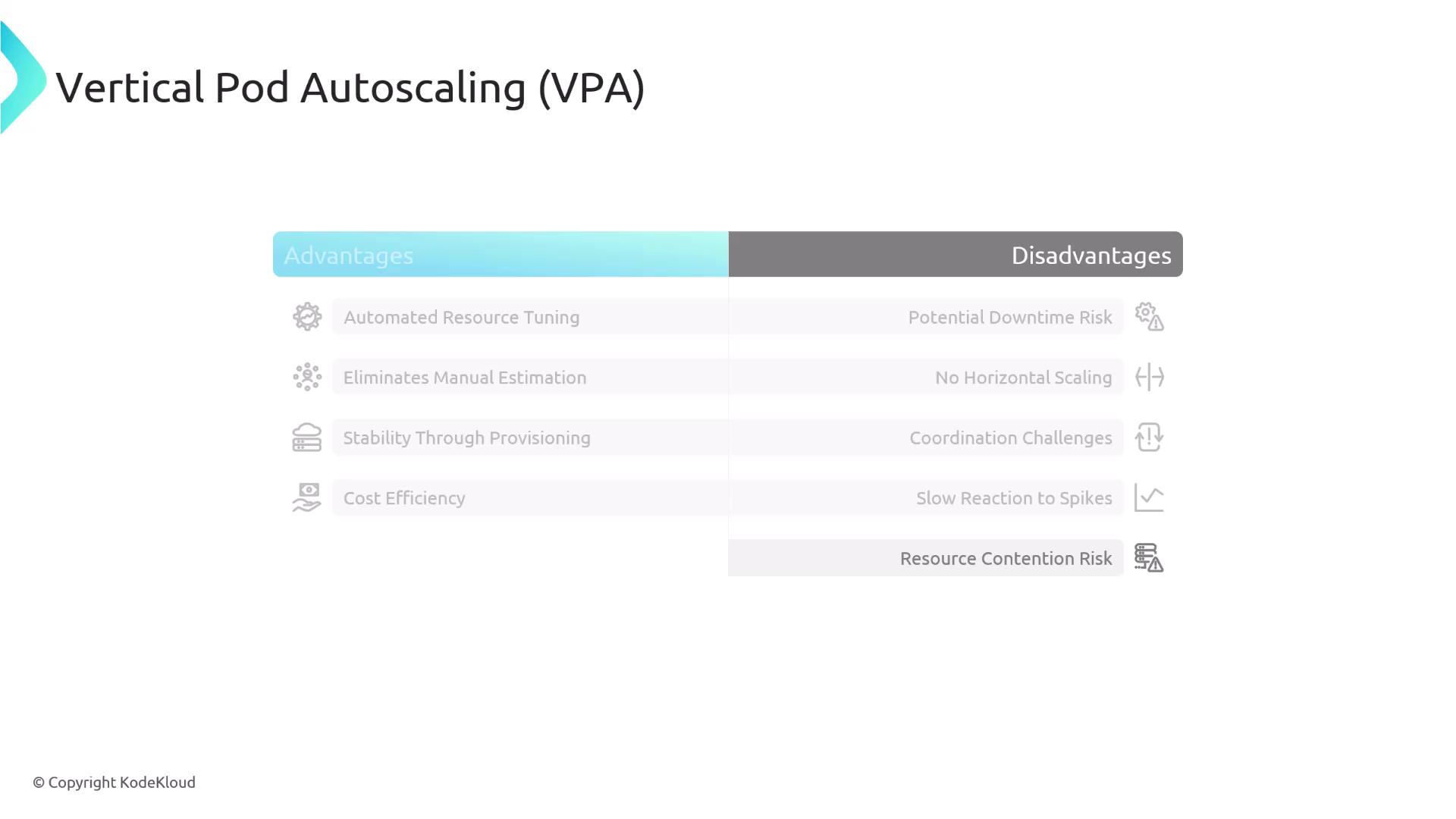
Vertical Pod Autoscaler (VPA) Instead of scaling out, VPA tunes the CPU and memory requests of individual pods:
Advantages:
Automates resource estimation per pod
Reduces manual tuning and resource waste
Ideal for steady workloads
Disadvantages:
Triggers pod restarts, which can cause downtime
Does not adjust replica count (use alongside HPA)
Slow reaction to sudden workload spikes
Over-provisioning may lead to unschedulable pods unless mitigated
Cluster Proportional Autoscaler (CPA) CPA ensures critical cluster services scale in proportion to the cluster size:
Advantages:
Automatically scales system pods (CoreDNS, kube-proxy, etc.)
Prevents infrastructure bottlenecks
Simple proportional configuration
Disadvantages:
Not workload-aware (ignores application load)
Linear scaling only; lacks precision
Interval-based adjustments may lag
Advantage Disadvantage Infrastructure pods scaling Not application-load aware Prevents system bottlenecks Linear/proportional only Minimal setup Polling intervals can delay scaling
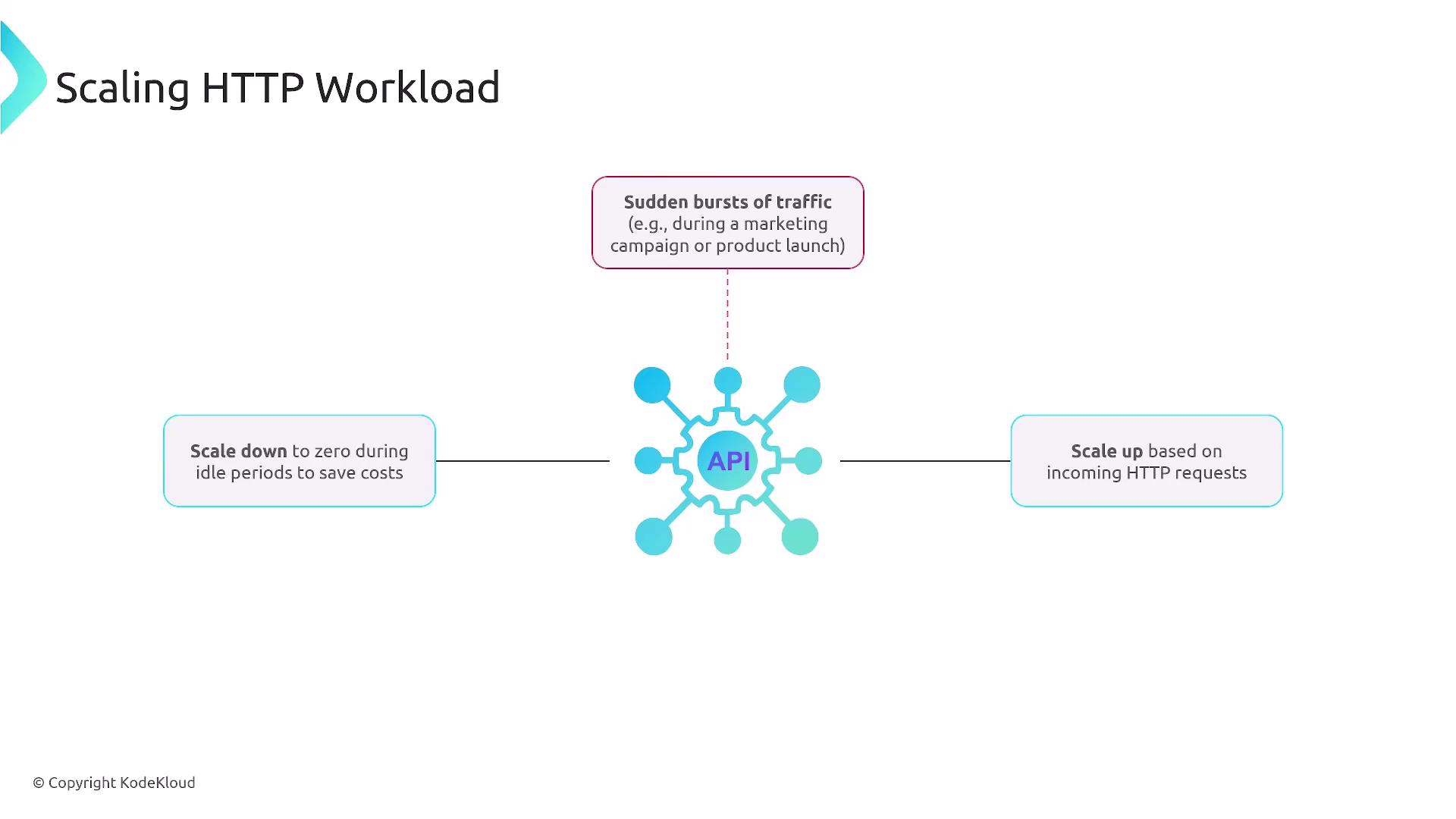
Event-Driven Scaling Scenario Consider a public HTTP API with highly variable traffic:
Sudden traffic spikes require rapid scale-up.Long idle periods demand scale-to-zero to save costs.No complex custom adapters for metrics.
Neither HPA, VPA, nor CPA fully satisfy this scenario:
HPA
Scales on CPU/memory only
Polling delay can overload pods
Cannot scale to zero
VPA
Adjusts resource requests per pod
Causes pod restarts and potential downtime
Not optimized for request-driven scaling
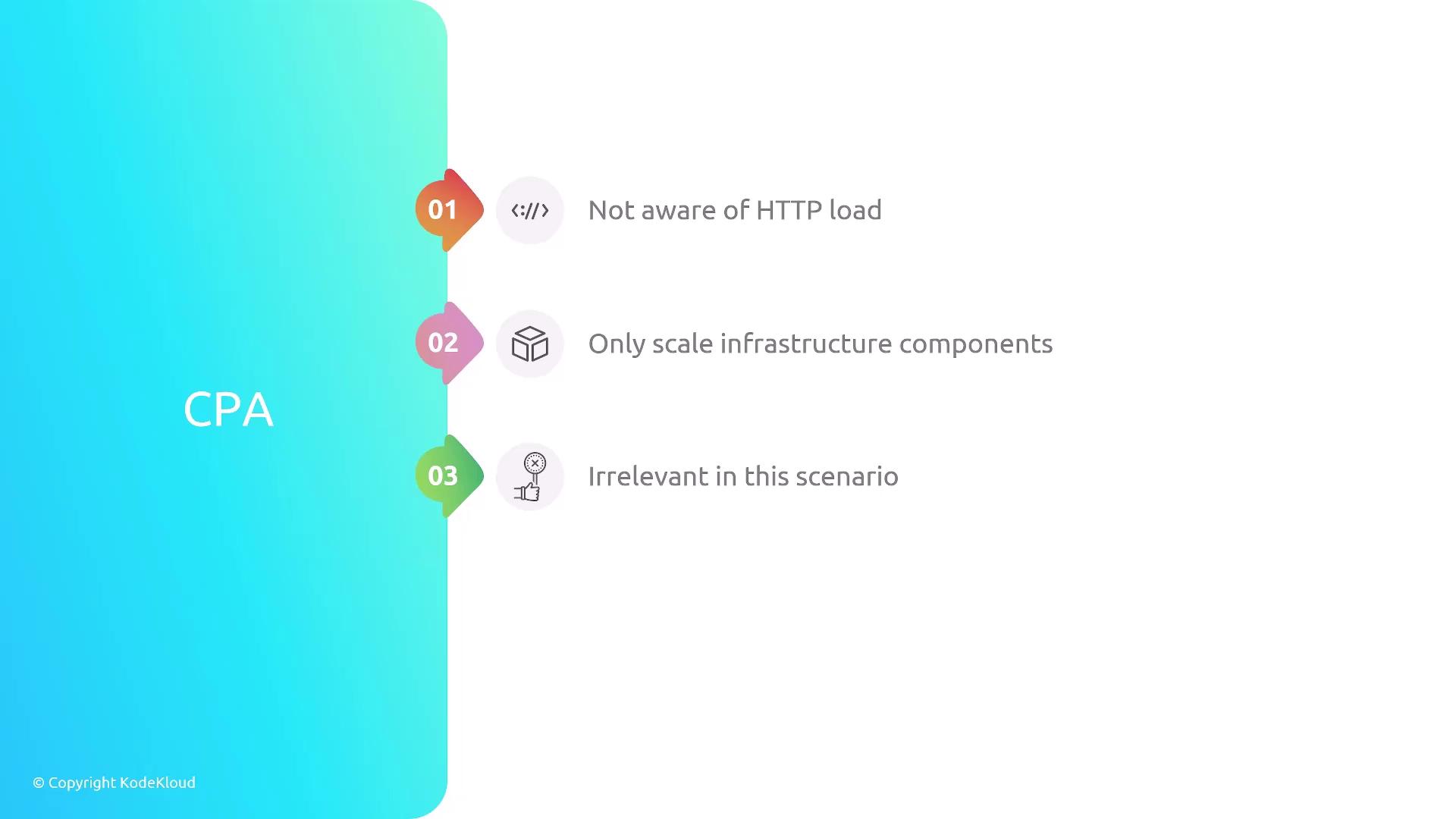
CPA
Only scales system components
Ignores HTTP request load
Relying solely on traditional autoscalers can lead to resource waste or unhandled traffic spikes.
Why KEDA? KEDA (Kubernetes Event-Driven Autoscaling) extends Kubernetes with event-based scaling. Key features:
Scale on any external event: message queue depth, HTTP requests, Prometheus alerts, and more.
Instant reaction to events and scale down to zero when idle.
Native Kubernetes integration, no heavy adapters required.
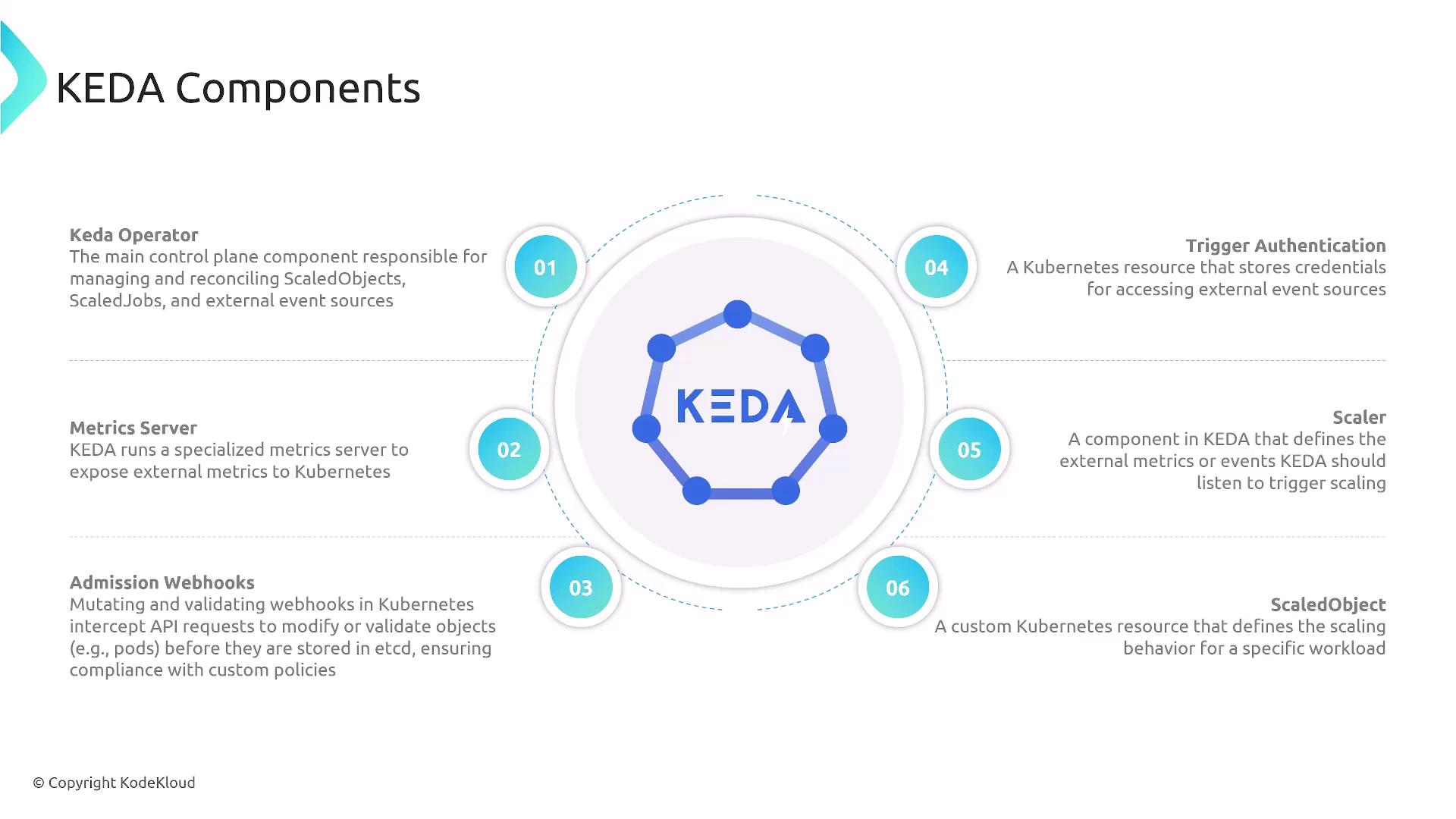
Introducing KEDA Components KEDA’s architecture consists of:
KEDA Operator ScaledObject and ScaledJob CRDs, reconciling external triggers with Kubernetes scaling.
Metrics Server
Admission Webhook
Trigger Authentication
Scaler
ScaledObject
Conclusion With KEDA, you achieve true event-driven autoscaling in Kubernetes—reacting instantly to external events, scaling to zero, and simplifying your infrastructure. You’ve now seen how KEDA complements HPA, VPA, and CPA to deliver flexible, cost-effective scaling for modern workloads.
Thanks for reading! For more details, visit the KEDA Documentation and the Kubernetes Autoscaling Guide .