The Five Key Steps
- Collect Metrics
Establish baseline measurements that represent your system’s normal (steady state) behavior.

-
Form a Hypothesis
Predict how the system will react when a specific fault is introduced, based on your steady state. -
Design the Experiment
Define the smallest, most targeted test that can validate or refute your hypothesis. -
Inject Failure
Execute the experiment by introducing the planned disruption.
Always run chaos experiments in a safe, isolated environment and ensure you have monitoring and rollback plans in place.
- Measure Impact
Compare post-failure metrics against your baseline to determine whether the hypothesis holds. Use findings to enhance system robustness.
Analogy: States of Water
To make these concepts concrete, consider how water changes state with temperature:- Given: Water exists as vapor, liquid, or solid depending on temperature.
- Hypothesis: Placing liquid water in a freezer for 10 minutes will cause it to freeze.


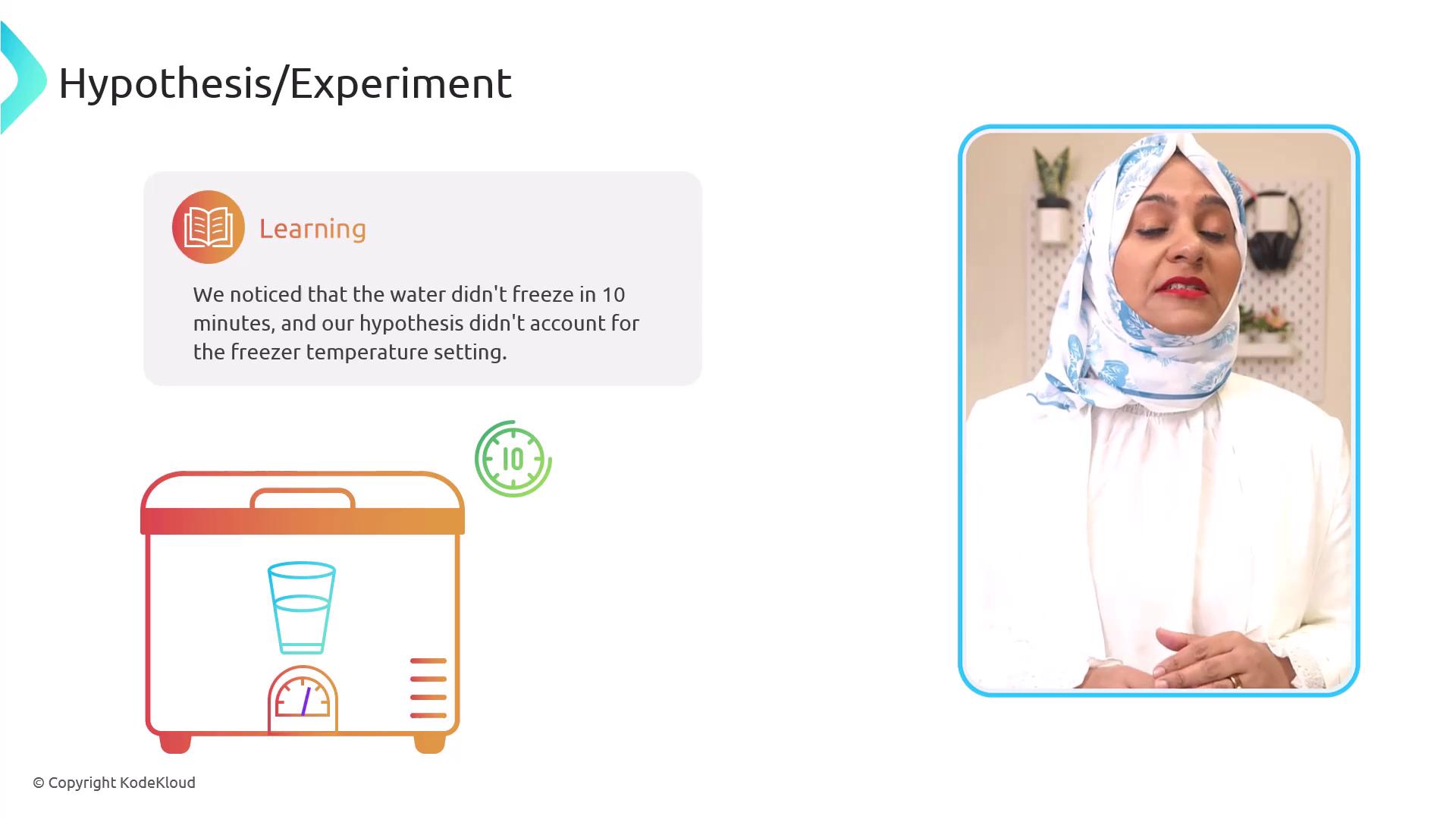

Refining your experiment parameters is key to isolating root causes and achieving reliable results.
Technical Example: Auto Scaling Group
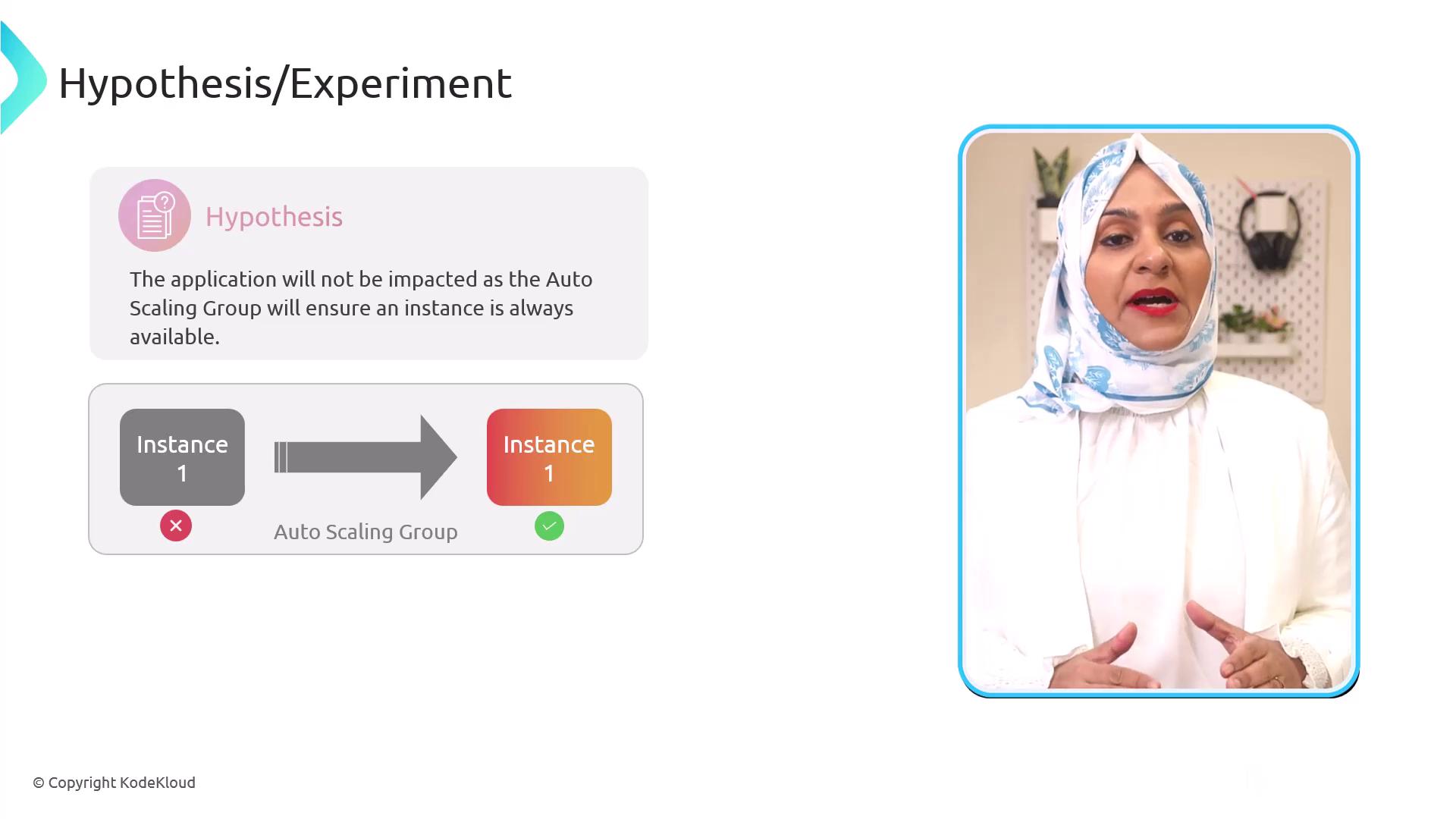
Next, let’s apply the five steps to a cloud infrastructure scenario:- Given: An application runs on a single EC2 instance within an Auto Scaling group (ASG), which maintains a minimum of one instance.
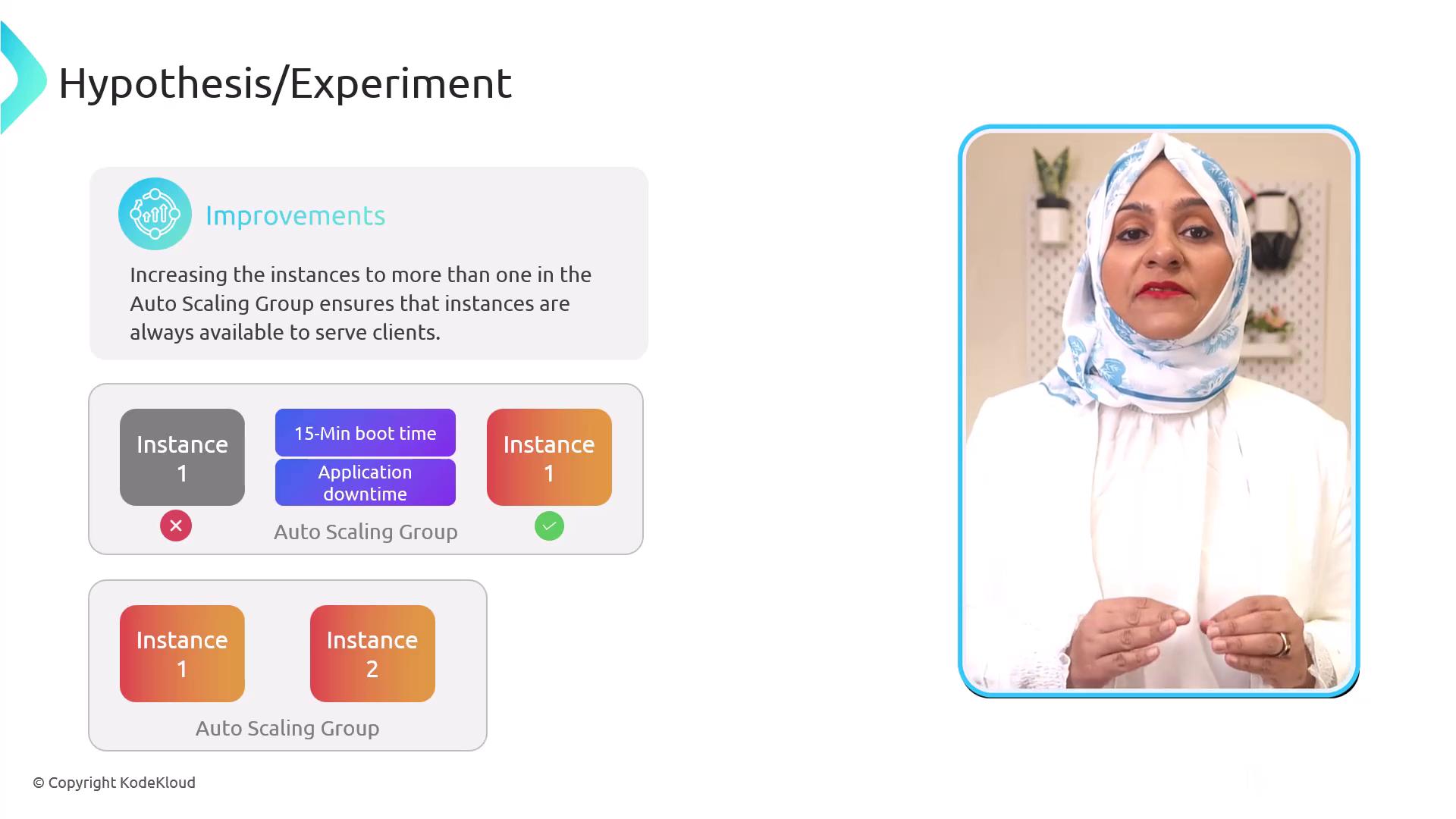
- Hypothesis: Terminating the instance won’t affect availability because the ASG will launch a replacement immediately.
Observation: The ASG replaces the instance, but boot time takes 15 minutes—resulting in unexpected downtime.