
What successful ingestion produces
The ingestion pipeline’s output should be consistent, searchable, and enriched with metadata so chunking and indexing produce semantically meaningful embeddings. Effective ingestion typically:- Extracts readable text with preserved sections and paragraphs.
- Preserves logical structure: headings, sections, lists, and hierarchy.
- Captures relationships: table columns and figure-caption pairings.
- Records document metadata: source, page numbers, authors, timestamps, document type.
Design ingestion to produce clean textual units plus metadata. Chunking and indexing rely as much on structure and metadata as on raw text.
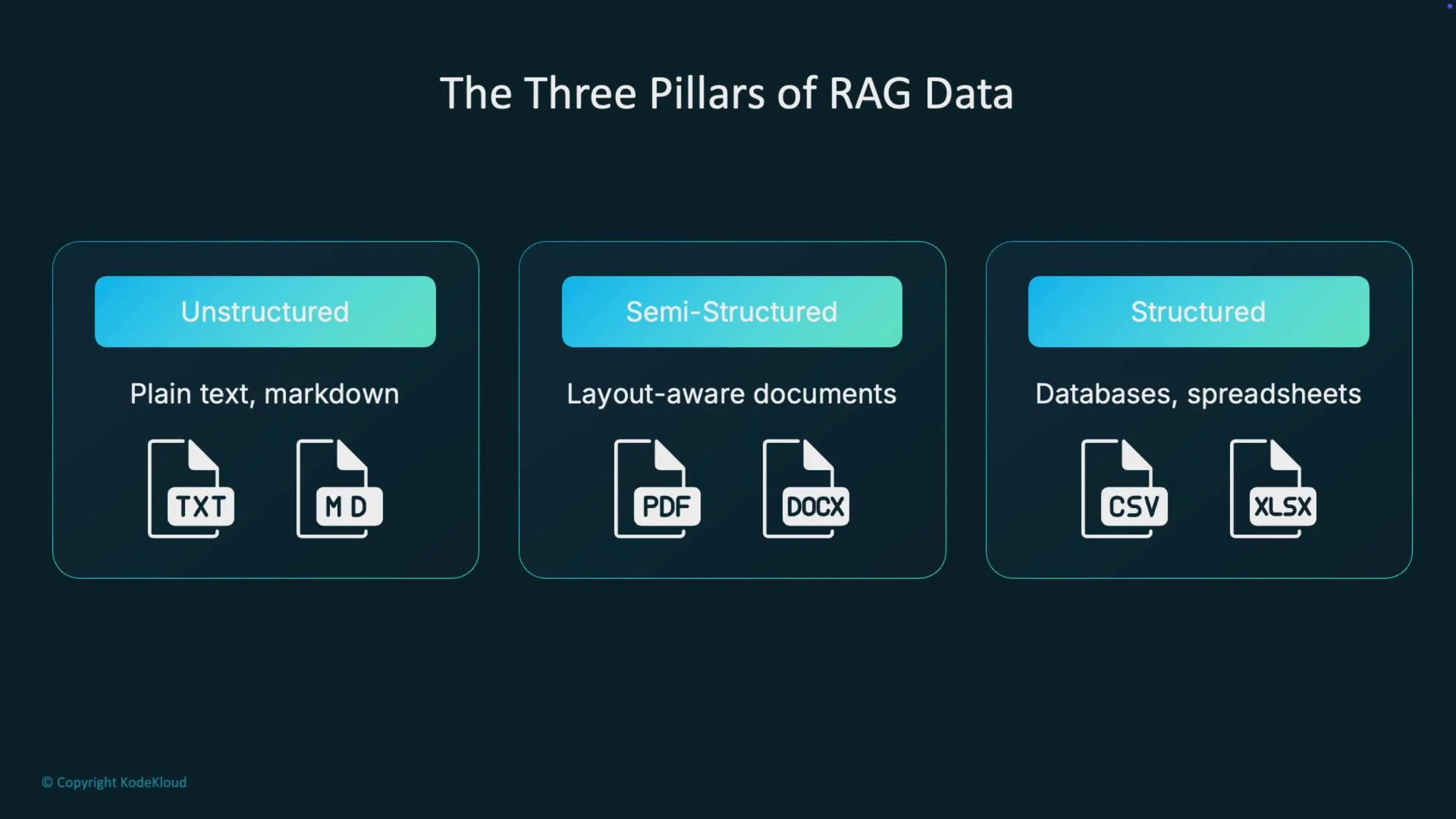
Three pillars of RAG data and ingestion implications
Understanding the data category helps select the right parsing strategy and chunking approach.- Unstructured: plain text, Markdown, simple logs. Minimal parsing required—text is ready for chunking.
- Semi-structured: PDFs, DOCX, HTML, and other layout-aware documents. Require layout-aware parsing to recover reading order, headings, and tables.
- Structured: databases, CSVs, spreadsheets (XLSX). Focus is on preserving relationships—columns, keys, and row semantics—so query-time reasoning remains accurate.
Quick reference: formats, common issues, and recommended tools
Note: wrap any example objects or placeholders as code (e.g.,
[{ "object": "person" }]) to avoid MDX parsing issues.
Why PDFs are often the hardest case
PDFs are presentation formats: content is placed by coordinates instead of logical sequence. Naive text extraction can produce:- Column-order collisions (left column mixed with right column).
- Flattened or scrambled tables (cell order lost).
- Headers, footers, and page numbers mixed into body text.
- Captions or figure labels detached from visuals.

Beware of naive PDF text extraction—without layout-aware parsing you’ll get noisy text that degrades embeddings and retrieval quality.
Typical ingestion pipeline pattern
A resilient ingestion pipeline usually mixes multiple specialized parsers and a normalization stage:- Raw extraction: choose a parser appropriate for the file type (e.g.,
pdfplumberfor PDFs,python-docxfor DOCX,pandasfor CSVs). - Layout and structure recovery: use layout parsers or heuristics to reconstruct sections, columns, tables, and captions.
- Chunking: split content into semantically coherent chunks (by paragraph, heading, or table row), keeping chunk size aligned to your embedding model’s context window.
- Metadata enrichment: attach source, page range, section heading, and other helpful attributes to every chunk.
- Indexing: calculate embeddings and store in a vector store with metadata for filtering and retrieval.
Tools and libraries
- DOCX and rich text:
python-docx— preserves paragraphs and headings. - PDFs:
pdfplumber,PyMuPDF(fitz),pdfminer.six— combine withlayout-parseror Apache Tika for layout analysis. - Tables & spreadsheets:
pandas,tabula-py,openpyxl— preserve columns and data types. - RAG and loader frameworks: LangChain, LlamaIndex, Haystack — provide document loaders, chunkers, and connectors for common storage backends.
- pdfplumber
- PyMuPDF / fitz
- pdfminer.six
- layout-parser
- python-docx
- pandas
- openpyxl
- RAG frameworks: LangChain, LlamaIndex, Haystack
Practical tips for robust ingestion
- Always retain source metadata. It enables filtering and provenance in retrieval.
- Chunk semantically (by heading/section) rather than blindly by token count whenever possible.
- Normalize repeated headers/footers and remove page artifacts early in the pipeline.
- Treat tables as first-class objects: keep columns and types instead of flattening to plain text.
- Validate with small end-to-end tests: ingest a representative sample, compute embeddings, and run retrieval queries to check quality.