Keyword search remains useful and widely used — this lesson explains where it excels and where semantic retrieval is necessary.
How keyword search works
At a high level, keyword search answers questions like “Which documents mention ‘engine’?” or “Which documents contain both ‘engine’ and ‘piston’?” Naively scanning every document at query time is slow, so search engines precompute a data structure called an inverted index. An inverted index maps each token (term) to the list of documents that contain it. At query time the engine looks up each query term and intersects those document lists to produce matches quickly — this precomputation is the performance secret behind keyword search.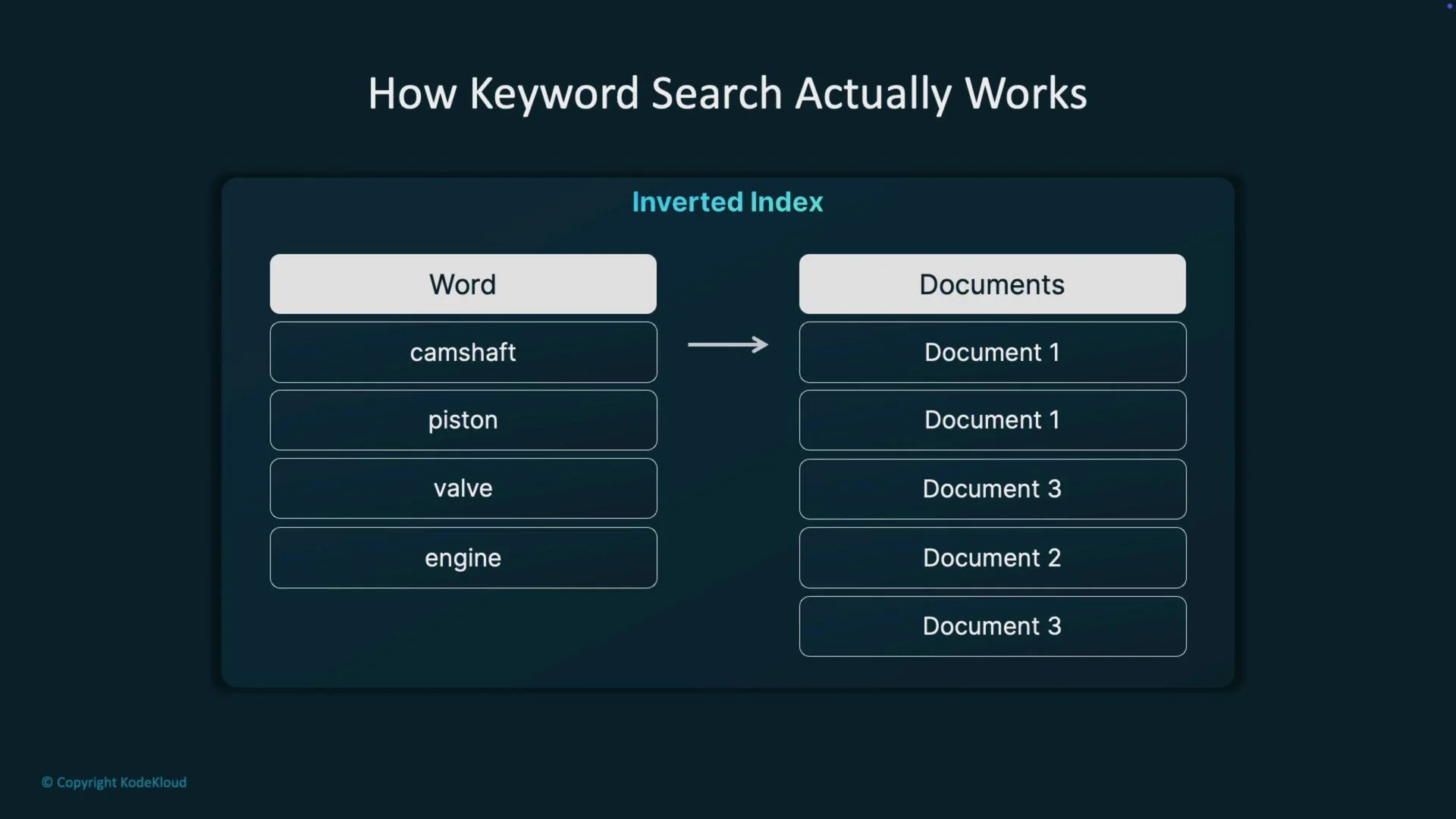

Ranking: which matches should appear first?
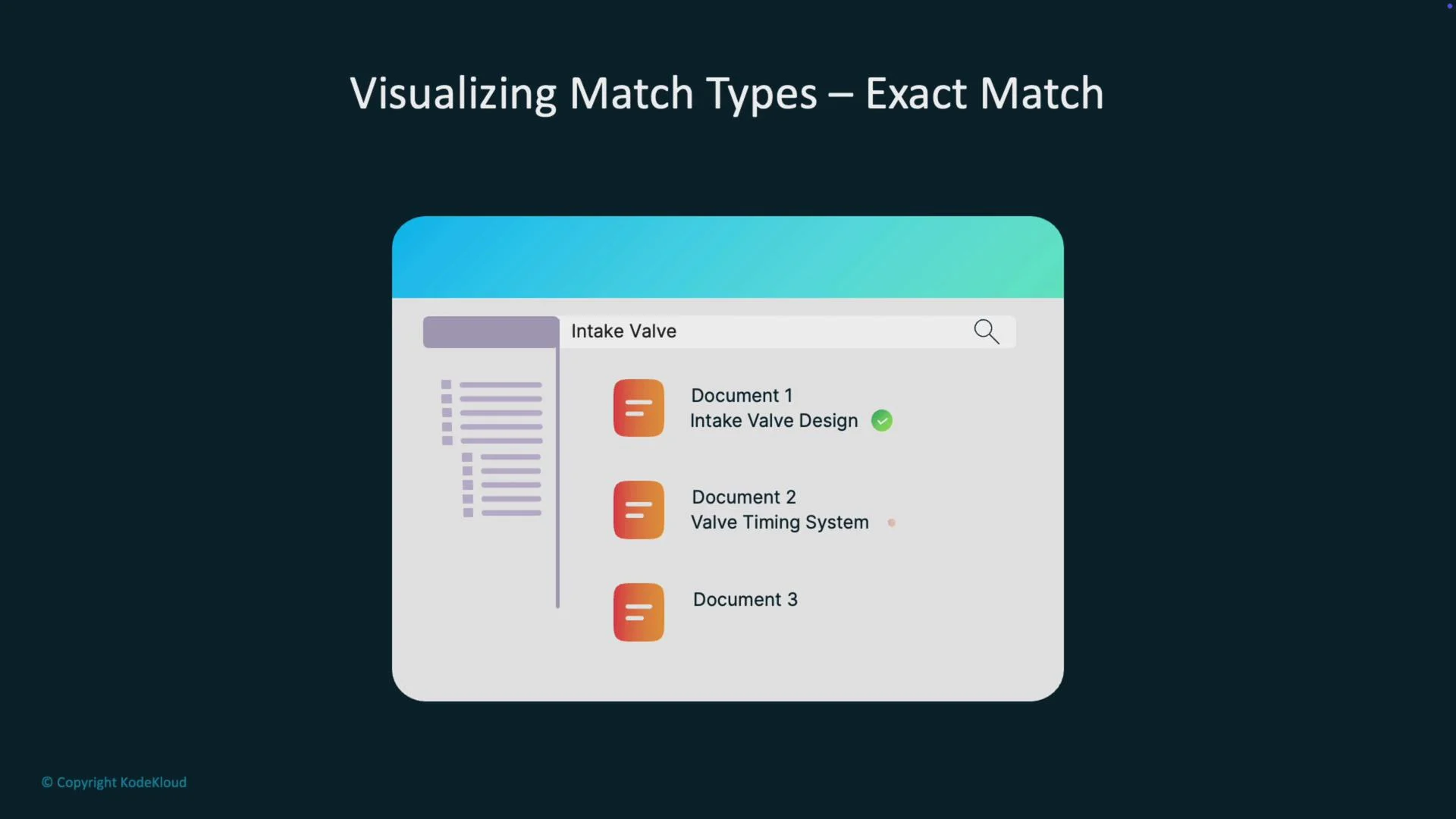
When many documents match a query (e.g., “piston valve timing”), ranking determines the order. Ranking combines signals like exact matches, near-exact matches, term frequency, and document frequency.- Exact match: query tokens appear verbatim (high weight).
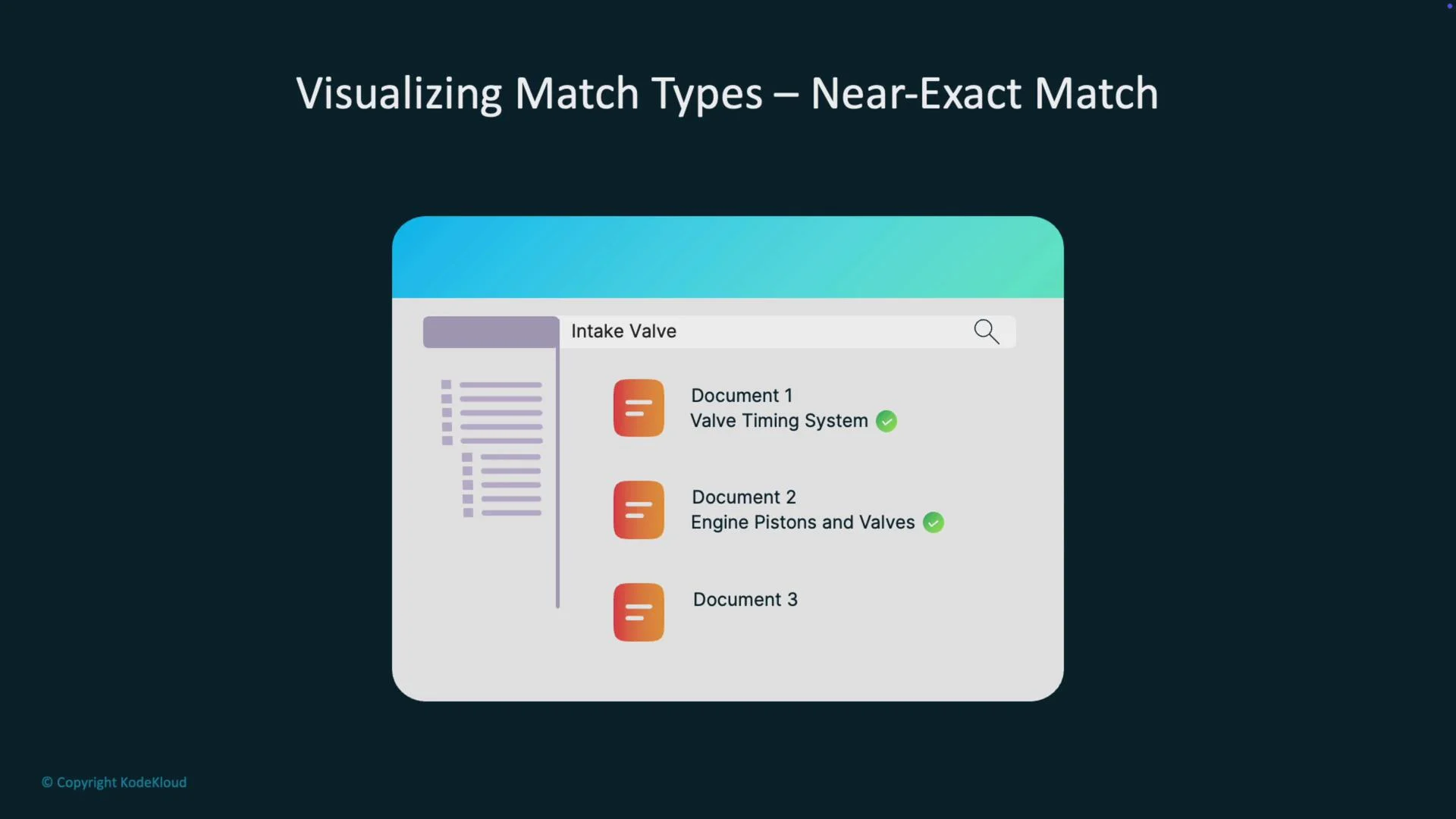
- Near-exact match: variations produced by stemming, pluralization, or synonym expansion.
- Partial match: documents containing only a subset of query terms (lower weight).
Scoring: TF, IDF, TF‑IDF, and BM25
Common lexical scoring components:- Term Frequency (TF): how often a term appears in a document.
- Inverse Document Frequency (IDF): downweights terms that appear in many documents.
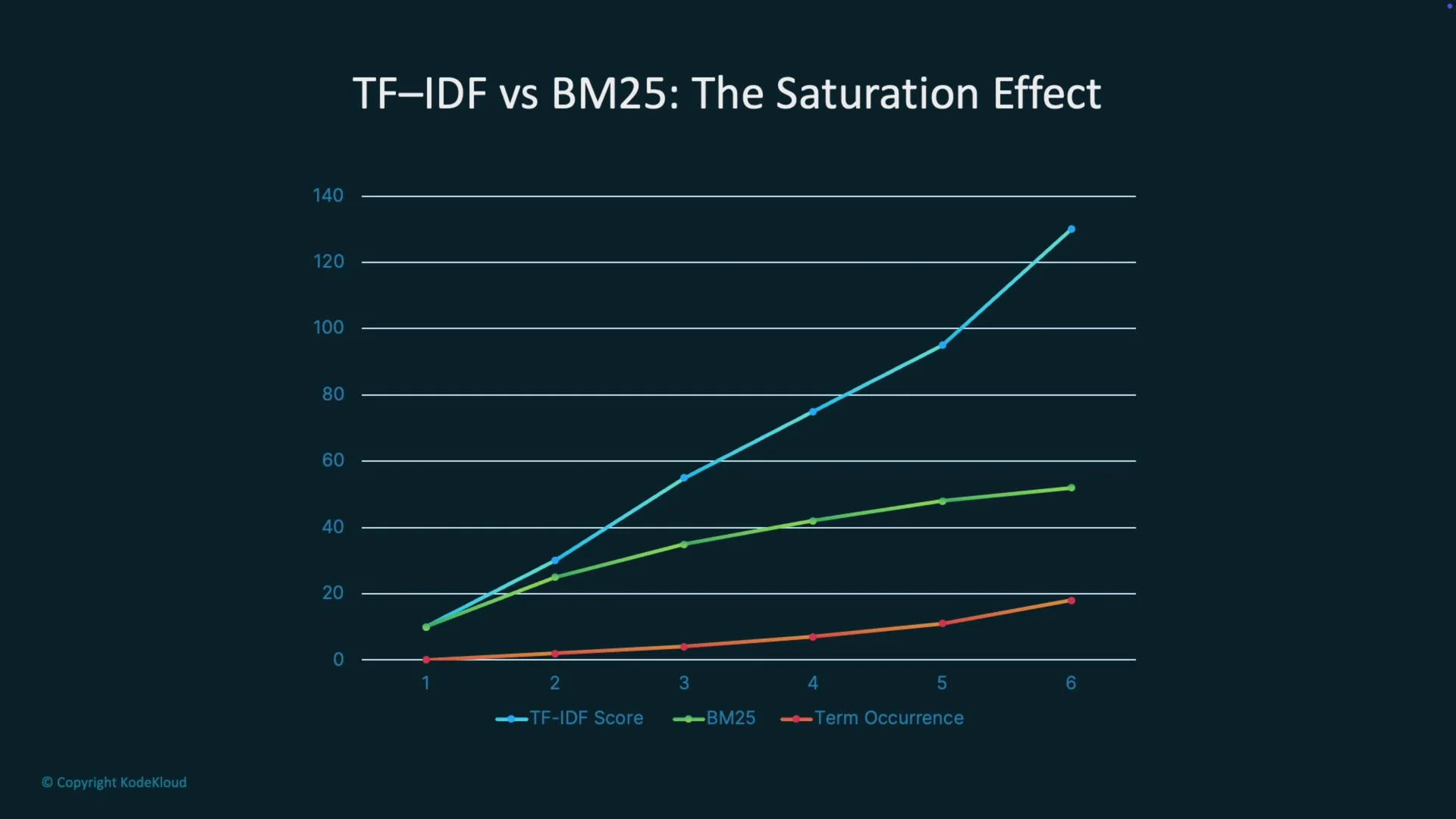
- TF‑IDF: multiplies TF by IDF to favor documents where a term is frequent but not ubiquitous.
- BM25: improves TF‑IDF by applying a saturation function to TF and normalizing for document length, reducing reward for keyword stuffing.



Four failure modes of keyword search
Even with BM25 and query expansion, keyword search fails in predictable ways. Below are four common failure modes and how semantic retrieval (dense embeddings + re-ranking) addresses them.- Lexical mismatch (synonyms, acronyms)
- Example:
2FA,two-factor authentication, andMFAare lexically different but equivalent. Keyword search needs synonym maps or query expansion to achieve good recall. - Query expansion can help, but it requires manual curation or domain rules.
- Example:

- Polysemy and context blindness
- Example: “Jaguar speed” could refer to the animal or the car; “Java memory model” could mean the programming language or the island. Bag‑of‑words lacks context to disambiguate.
- Mitigations: phrase queries, field boosts, or manual disambiguation. RAG uses contextual embeddings that encode neighboring words, improving disambiguation and enabling semantic matches (e.g., mapping
2FAtotwo-factor authenticationwithin context).

Note: very short or ambiguous queries remain challenging even for semantic systems — adding context, session history, or query expansion often helps.
-
Long documents and passage granularity
- The relevant answer may be a short passage inside a long document. Document-level indexing treats the whole file as one item and can bury the passage.
- Best practice: chunk documents into passages and index passages as first-class retrieval units. RAG systems commonly use passage-level embeddings so the LLM receives concise, relevant content.
-
Noisy language (typos, variants, cross-language)
- Typos (e.g., “ingress” vs “inrgess”), spelling variants (licence vs license), or a query in a different language create tokenization and OOV problems.
- Use multilingual or fuzzily tolerant embeddings, improve tokenization, and normalize text to reduce noise impact.

Implementation checklist for RAG
When combining keyword and semantic retrieval, follow this practical checklist:- Use hybrid retrieval (BM25 + dense vectors) to combine precise keyword matching with semantic recall.
- Optimize chunking: common chunk sizes are 300–600 tokens with 10–20% overlap; tune based on document type.
- Select embeddings that match your domain and language requirements (domain‑specific or multilingual models).
- Apply cross‑encoder re‑ranking: re-rank the top‑K hits from BM25 + dense retrieval with a cross‑encoder for higher precision.
- Use query expansion techniques such as hypothetical document embeddings or curated synonym maps for very short or ambiguous queries.
- Maintain data hygiene: dedupe, strip boilerplate/navigation, normalize text, and correct common spelling errors.
- Maintain synonym/acronym maps for known domain equivalences (e.g.,
2FA↔two-factor authentication). - Evaluate with realistic test sets and metrics: recall@K, MRR, and “answer found in top K.”
Hybrid search preserves the speed and precision of keyword methods while extending recall and semantic matching through embeddings.
When to keep using keyword search
Keyword search is still the right tool for many cases:- Exact lookups: IDs, SKUs, and log lines.
- Compliance and audit workflows where deterministic operator semantics (AND/OR/NOT) matter.
- Power users familiar with precise query syntax and domain jargon.
- Very large-scale, low-latency lookups that depend on inverted indexes for performance.
This lesson summarized how keyword search works, common limitations that motivate semantic retrieval, and practical steps to combine lexical and dense retrieval effectively in RAG systems.
Links and references
- TF‑IDF — Wikipedia
- BM25 — Information Retrieval Background
- Retrieval‑Augmented Generation (RAG) — Paper / Overview
- Kubernetes Basics (example external reference)