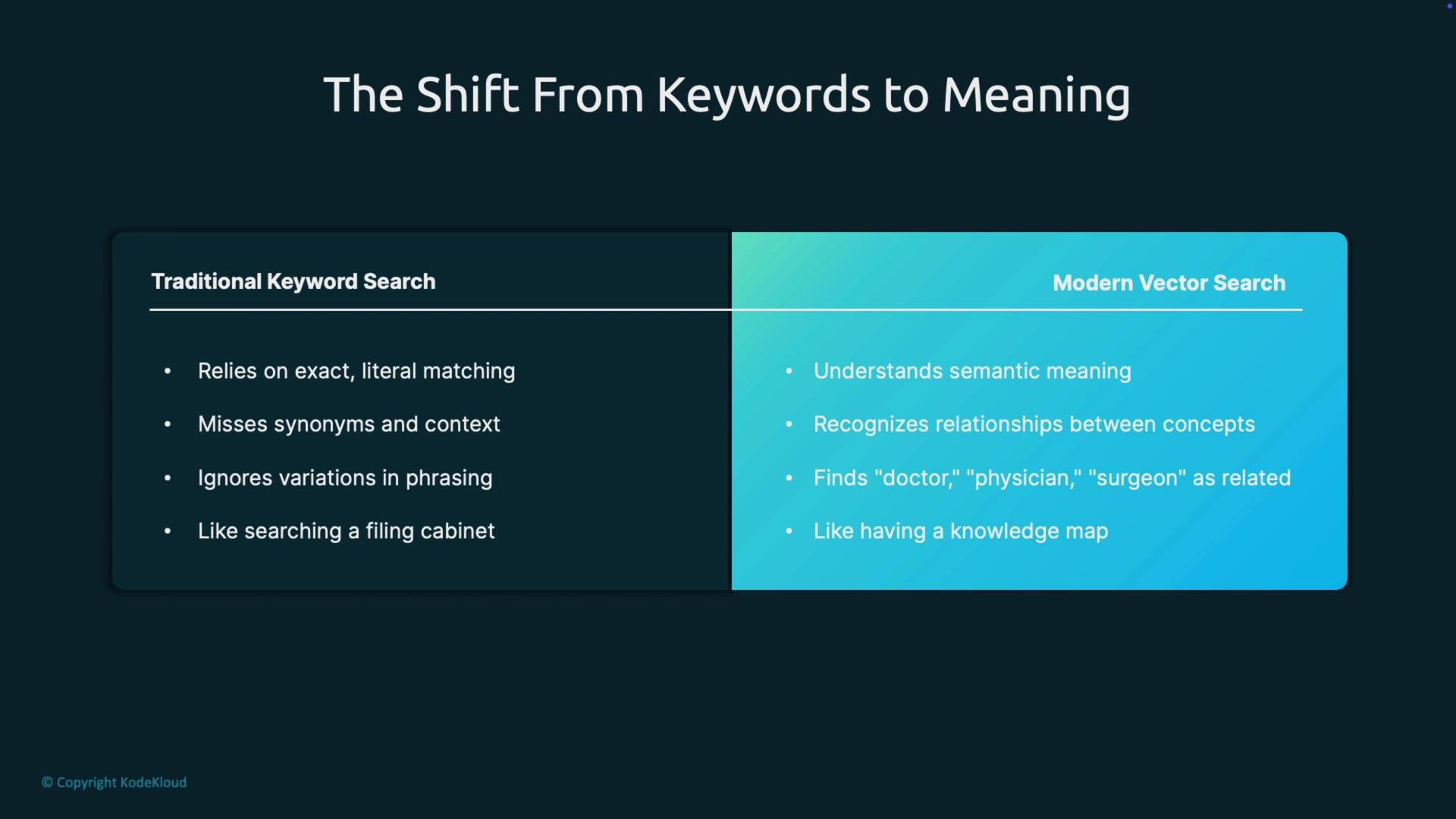
- Specialized storage for embeddings and vector indexes.
- Rich connections: each vector links to the original document or content and includes searchable metadata.
- Optimized search: engineered for efficient nearest-neighbor retrieval at scale.
- Corpus: collect your raw data — documents, images, video, audio, log snippets, etc.
- Encoding: transform each item into an embedding vector using an embedding model or encoder.
- Storage: store embeddings alongside metadata (document IDs, timestamps, authors) in the vector database.
- Query: encode a user’s textual query into a query vector.
- Similarity search: compare the query vector to stored vectors (typically cosine similarity or Euclidean distance) and retrieve the top-k most relevant items.
These indexes provide “shortcuts” through vector space so searches are practical at scale.

- Speed (query latency)
- Recall / accuracy (how complete the returned results are)
- Memory (storage and operational cost)
- Semantic retrieval: find contextually relevant passages based on meaning rather than keyword overlap.
- Hallucination reduction: grounding LLM outputs in retrieved source documents reduces false or invented statements.
- Effortless scaling: support millions of document chunks with low-latency retrieval.
- Intelligent filtering: combine vector similarity with metadata filters (date ranges, user IDs, topics) to constrain results to the most relevant slices of your corpus.

- Optimize chunk size: aim for roughly 200–400 tokens per chunk, with 10–20% overlap between adjacent chunks when context continuity is important. Too small loses context; too large dilutes semantic focus.
- Choose domain-tuned embeddings: prefer embedding models trained or fine-tuned on domain-relevant data (medical, legal, technical) to capture domain-specific semantics.
- Leverage metadata filters: store searchable attributes (dates, authors, categories, document type) and apply them before or after vector search to narrow candidates.
- Refresh embeddings: re-embed documents when their content changes — stale embeddings degrade retrieval relevance and can mislead downstream LLMs.
- Monitor and iterate: track retrieval metrics (precision@k, recall@k) and user feedback to refine chunking, indexing, and retriever settings.

- You have large, unstructured corpora (documents, transcripts, images, video) and need semantic search.
- You require nuanced, meaning-based retrieval across millions of items.
- You are building RAG or AI-powered search where retrieval quality materially affects LLM outputs.
- Your dataset is small and static — simple keyword indices or SQL may be sufficient and less complex.
- Exact keyword matching is a strict correctness requirement.
- Budget, operational complexity, or latency requirements make additional infrastructure impractical.
- Full-text indexing already provides acceptable utility for the application.
Choose vector databases when semantic retrieval and scale justify the added complexity and cost. For small or strictly keyword-driven systems, stick with simpler search solutions.
- Introduction to Vector Search — Practical Guide
- ANN Algorithms: HNSW, IVF, PQ — Research Papers and Summaries
- Retrieval-Augmented Generation (RAG) — Overview and Patterns
- Vector Database Options — Comparison and Benchmarks