- SentenceTransformers: https://www.sbert.net/
- rank_bm25: https://github.com/dorianbrown/rank_bm25
Installation
Install the required Python packages (Jupyter-friendly):Overview: how the demo works
- Prepare a small document corpus and example queries.
- Tokenize documents for BM25 and initialize the BM25 index.
- Encode documents with a sentence-transformer to produce normalized embeddings.
- For each query:
- Get BM25 scores (token overlap / importance).
- Get semantic scores (cosine similarity with embeddings).
- Normalize both score vectors to [0,1] and combine them with a weighted linear blend: hybrid = alpha * semantic + (1-alpha) * bm25.
- Compare the top-k results for BM25, semantic, and hybrid.
Corpus, queries, and imports
Prepare BM25 and SentenceTransformer embeddings
Helper: show results for a query (BM25, semantic, and weighted hybrid)
Run the demo for all queries (default semantic weight alpha=0.8)
Discussion and example behavior
- BM25 relies on token overlap and term importance. It may favor documents that share surface words with the query (even if the meaning differs).
- SentenceTransformer returns semantically similar results by embedding meaning, so it better handles synonyms and paraphrases (e.g., mapping “2FA” to “two-factor authentication”).
- The hybrid approach blends both signals using
alpha. Values:alpha > 0.5favors semantic matching.alpha < 0.5favors BM25.
- Normalizing both score arrays to [0,1] before combining allows a simple weighted linear blend that is robust to differing score scales. The small epsilon (
1e-9) prevents division-by-zero for degenerate score distributions.
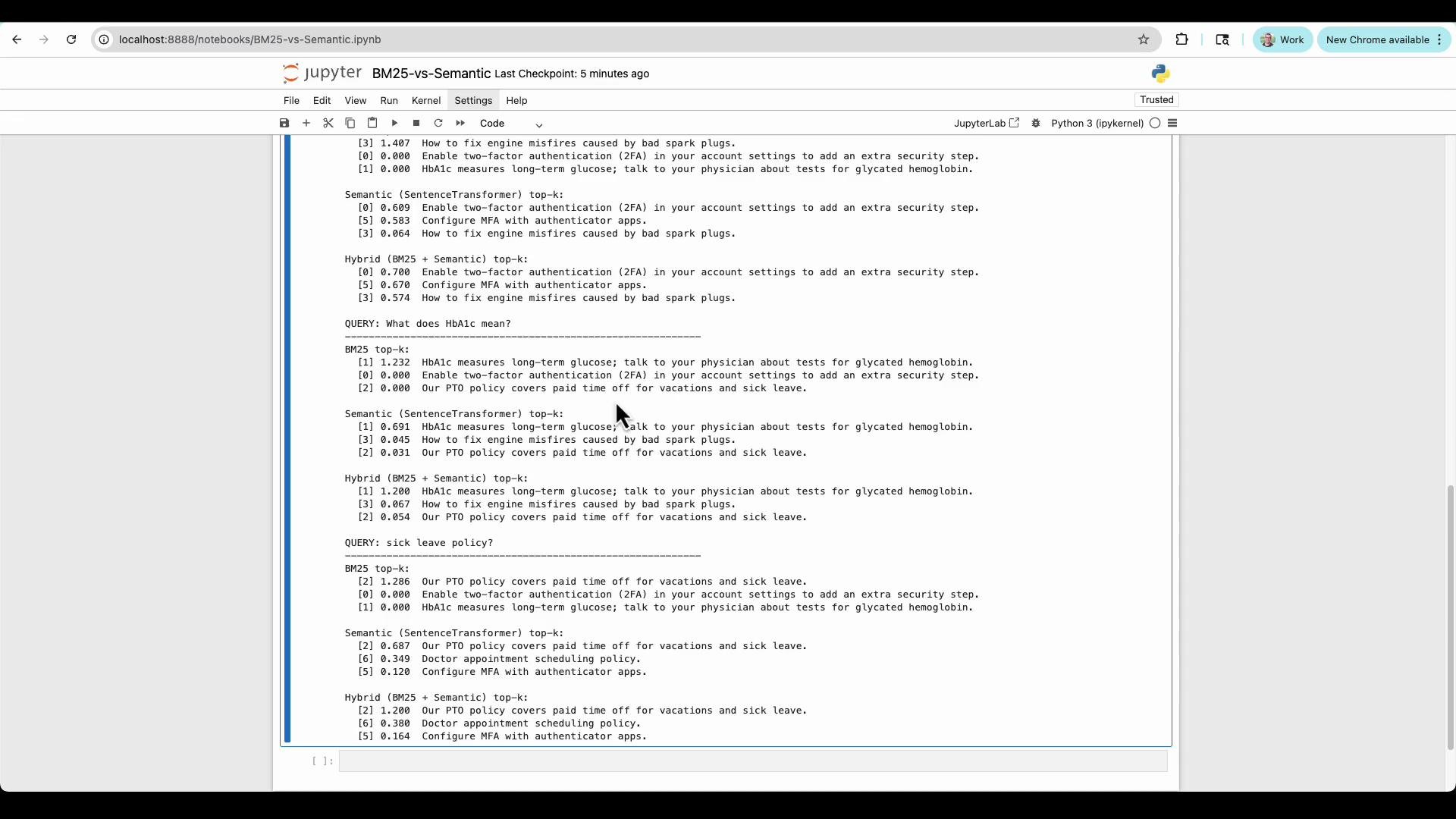
Sample (cleaned) output for illustration
Tuning guidance
Tune
alpha and experiment with different sentence-transformer models (for example, all-MiniLM-L6-v2 for speed or multi-qa-MiniLM-L6-cos-v1 for QA-style retrieval). Use a labeled validation set (queries with known correct docs) to measure precision/recall and choose alpha and model for your dataset. If BM25 returns many identical scores (common in small corpora), the semantic signal typically helps; if semantic matching over-generalizes in your domain, increase BM25 weight.Switching the embedding model (example)
Quick comparison
Final notes
- This demo uses a very small toy corpus for illustration. On larger corpora you’ll get more stable BM25 distributions and richer semantic matches.
- Keep the retrieval pipeline configurable:
alpha,k, andmodelselection should be part of your evaluation loop. - Validate hybrid weighting with representative queries and metrics (e.g., recall@k, MRR) before deploying to production.