- Latency — users expect fast responses; the retrieval path must be optimized for P95/P99 latency.
- Cost — compute (re-rankers, LLM tokens) and storage (indexes, embeddings) grow with scale.
- Trust — freshness, provenance, and cited answers increase user confidence.
- Wrong chunking: retrieving tangential fragments instead of the exact answer.
- Stale index: returning outdated information because the index wasn’t refreshed.
- ACL leaks: returning documents a user shouldn’t see.

- Ingest: split documents into chunks, create embeddings, and index them.
- Query: convert user query to keywords + vector, perform filtered searches, and re-rank candidates.
- Generation: pack and send the assembled context + query to the LLM to produce a grounded answer.
- Security: enforce who can see what (ACLs, filtering, query-time authorization).
- Caching: accelerate the fast path to reduce latency and cost.
- Observability: instrument ingest, retrieval, re-ranking, and generation for latency, error rates, and data correctness.
- Sparse search (keyword-based): precise for exact tokens, code snippets, error strings, and legal text.
- Dense retrieval (embeddings): finds semantic matches and paraphrases; good for natural-language questions and cross-lingual queries.
- Hybrid search: fuses sparse + dense signals (often via score fusion). A safe default because it captures both exact matches and paraphrases.
- Smaller chunks → higher precision, but can lose global context.
- Larger chunks → preserve context, but may decrease specificity and increase token costs.

- Fixed-size chunks (tokens or characters) with a small overlap (10–20%) to preserve continuity.
- Semantic chunks aligned to natural boundaries (sections, paragraphs).
- Structure-aware chunking that preserves headings, titles, and document hierarchy.

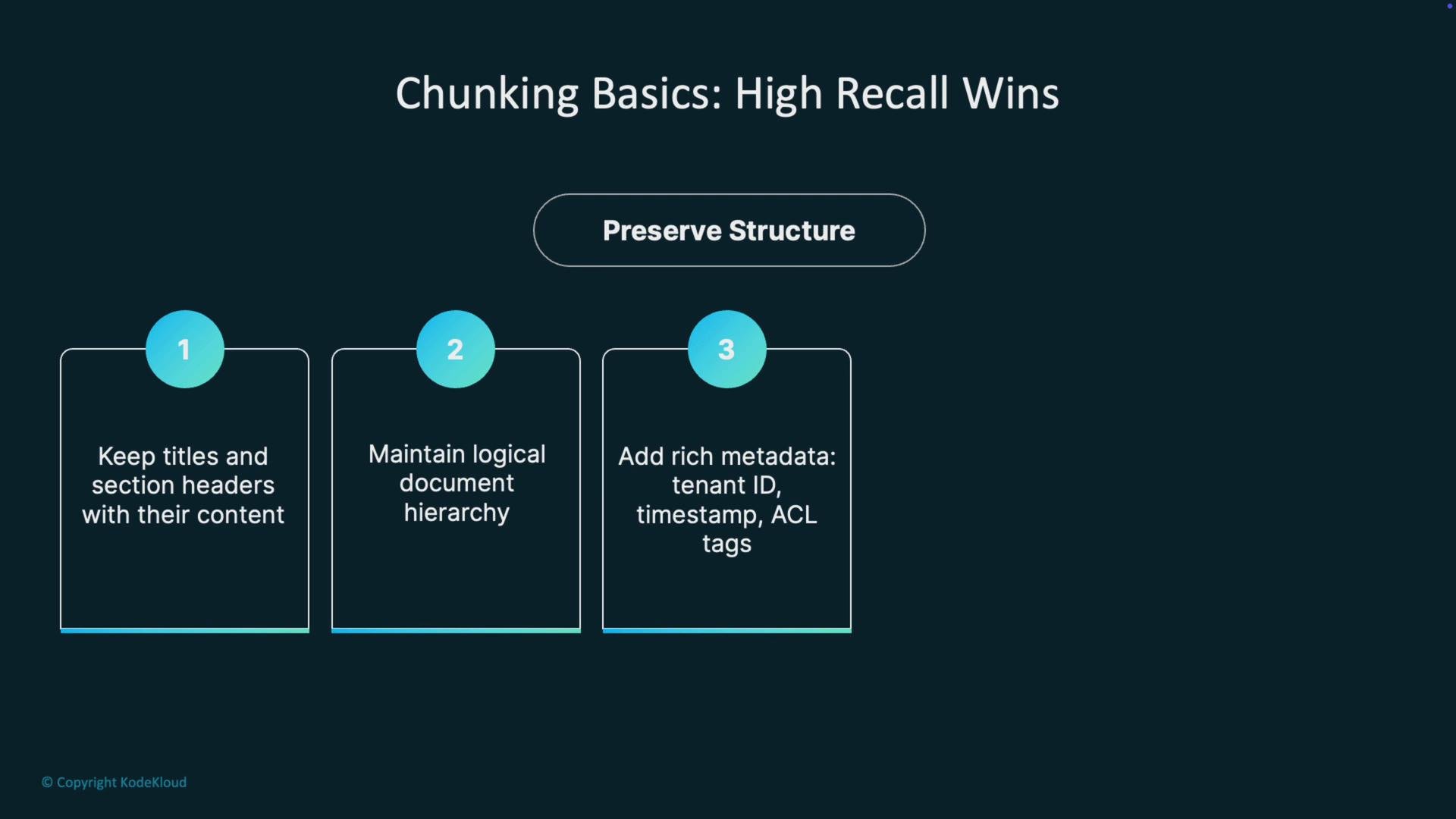
- Keep titles and section headers with their content.
- Maintain logical document hierarchy when chunking.
- Add metadata fields (source, section ID, published timestamp) to each chunk.
Important tuning knobs
K(candidates): number of nearest neighbors returned by the ANN search. Typical starting points:K=50for re-ranking pipelines,K=10for direct results.efSearch/nprobe: controls internal search breadth. Higher values increase recall at the cost of latency (efSearchfor HNSW;nprobefor IVF/IVF-PQ).
K and efSearch/nprobe against your SLAs.

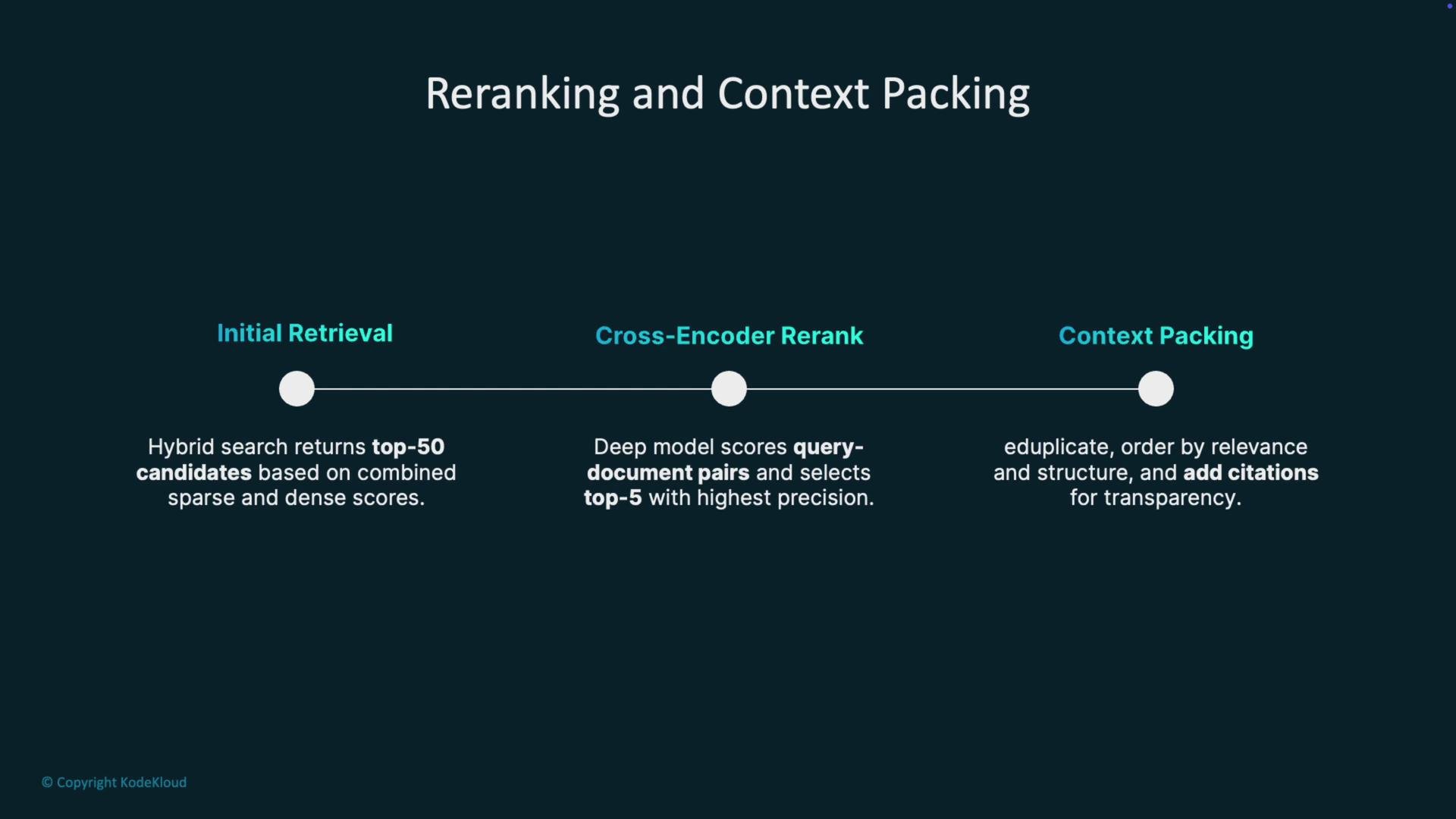
- Initial retrieval (hybrid) returns top N candidates (e.g., top 50).
- Cross-encoder re-ranker scores query-document pairs with a more expensive model and selects a smaller, high-precision set (e.g., top 5).
- Context packing: dedupe, order by relevance and document structure, and assemble the context with citations for transparency.
- Cross-encoder re-ranking often yields 15–30% better relevance for the final assembled context but increases compute cost.
- Always set timeouts: if re-ranking exceeds the budget, fallback to initial candidates. Users generally prefer a fast, approximate answer to a slow, perfect one.


- Hybrid weights (sparse vs dense).
- Retrieve depth (
Kcandidates). - ANN search parameters (
efSearch/nprobe). - Re-rank depth (how many candidates to re-score).
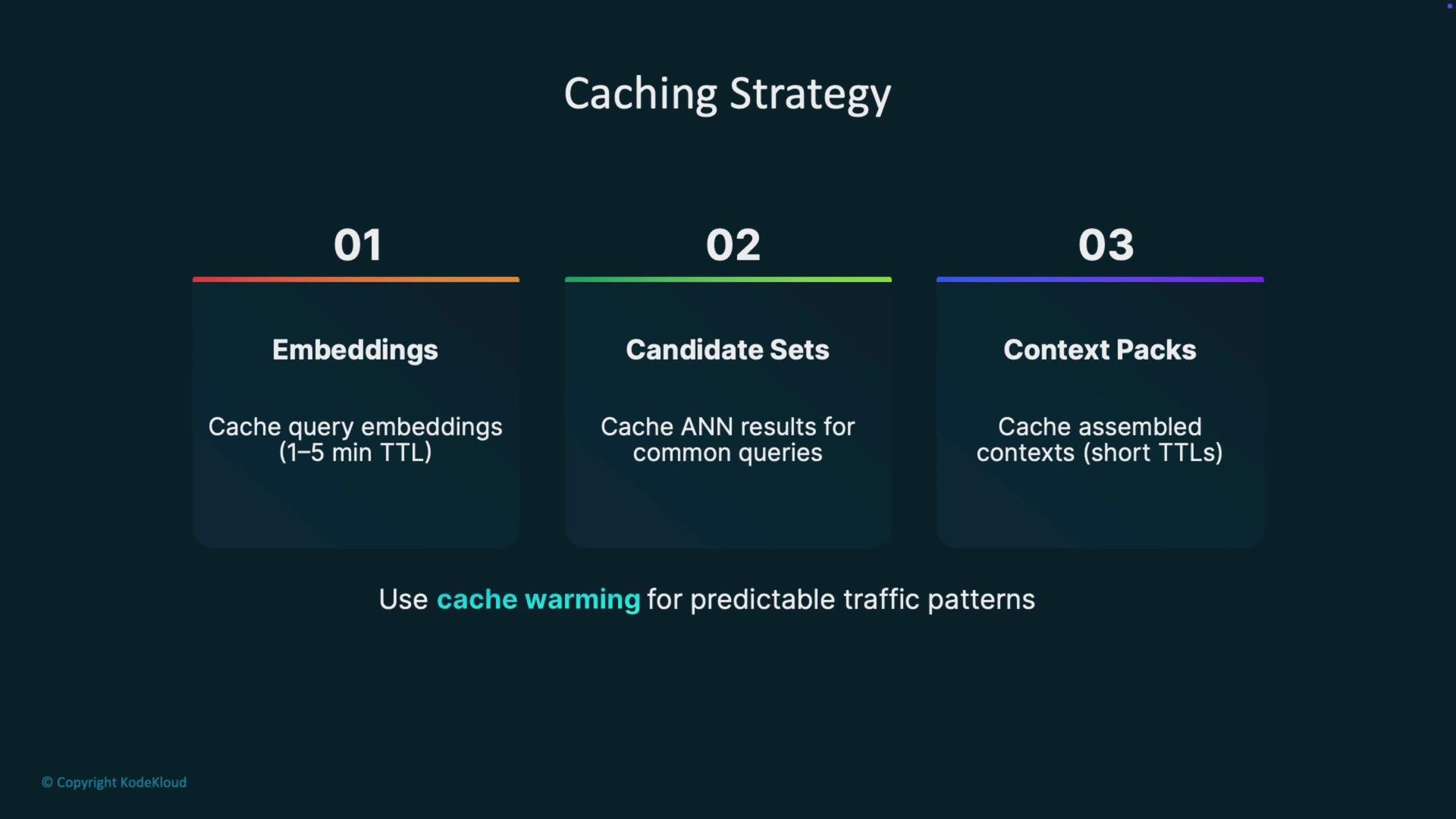
- Cache query embeddings for frequent queries.
- Cache ANN candidate sets and assembled context packs for hot queries.
- Use cache warming for predictable traffic (e.g., daily reports, scheduled queries).
Start conservative, measure real traffic, and iterate.
Takeaways
- Start with hybrid search as a safe default for production.
- Invest in chunking and metadata: preserve structure, include titles/headers/source IDs, and choose chunk sizes and overlaps based on use case.
- Instrument every stage (ingest, retrieval, re-ranking, context assembly) for latency, accuracy, and security metrics — you can’t optimize what you don’t measure.
- Use re-ranking selectively where it produces measurable precision gains; don’t re-rank everything by default.
- Implement timeouts and graceful degradation so the system remains responsive under load.
Begin with hybrid search, put effort into chunking and metadata, and instrument the pipeline. Optimize re-ranking and caching based on measured cost-benefit for your workload.
- HNSW: https://github.com/nmslib/hnswlib
- FAISS (IVF/PQ): https://github.com/facebookresearch/faiss
- Dense vs. sparse retrieval overview: https://arxiv.org/abs/2004.08266
- Best practices for RAG pipelines: search for “retrieval-augmented generation best practices”