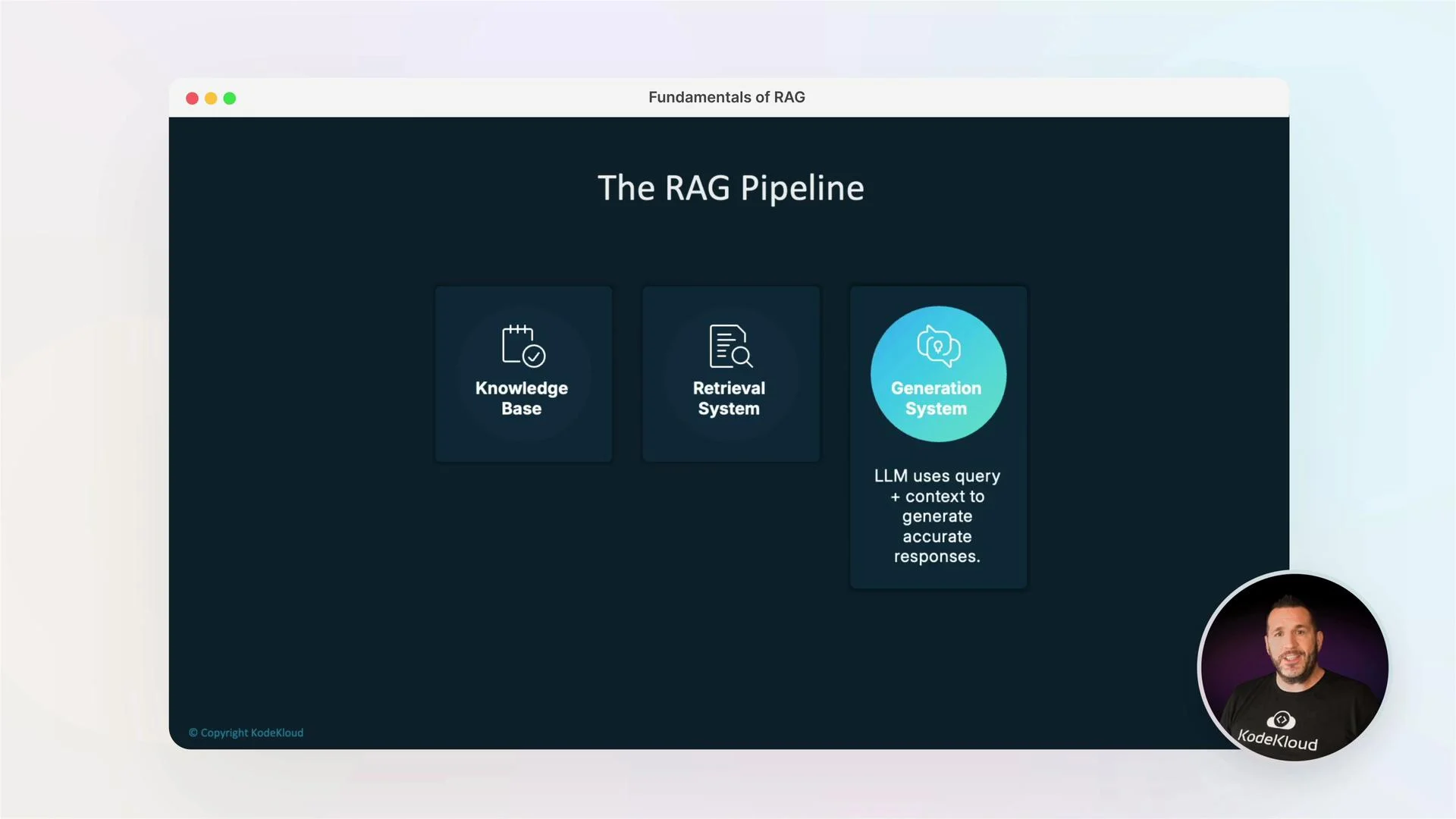
- When teams need fast, accurate answers from fragmented internal knowledge — runbooks, incident reports, Confluence pages, PDFs, email threads, and other silos — RAG retrieves the exact passages that matter and conditions an LLM on those snippets.
- Unlike traditional search that returns documents or links, RAG returns relevant context (snippets) and uses that context to generate concise, actionable answers. This makes RAG ideal for incident diagnosis, onboarding, routine troubleshooting automation, and compliance or policy queries where source fidelity is critical.
- Conceptual foundations of RAG and when it outperforms pure retrieval or pure generation.
- Hands-on architecture patterns and trade-offs for end-to-end RAG systems.
- A practical developer setup and project structure for production-ready RAG workflows.
- Document ingestion best practices for DOCX, PDF, CSV, and other common formats.
- Chunking strategies (fixed-size, overlap-aware, semantic chunking) to preserve context and improve retrieval.
- Retrieval techniques: keyword methods (TF-IDF, BM25), re-ranking, and semantic search with embeddings.
- An introduction to vector databases, evaluation criteria, and a practical implementation example using ChromaDB.
- A guided build of an end-to-end RAG pipeline with deployment and integration examples.
Who should take this course: engineers, machine learning practitioners, and technical product managers who want to build reliable, explainable assistants over internal knowledge. Basic familiarity with LLM concepts, embeddings, and REST APIs is helpful but not required.
Key terms and concepts (quick reference)
- Retrieval-Augmented Generation (RAG): Combining retrieved context with an LLM to generate grounded, source-backed answers.
- Embeddings: Vector representations that capture semantic similarity of text fragments.
- Vector database / vector store: Specialized storage for embeddings enabling efficient similarity search.
- Chunking: Splitting documents into retrievable segments while preserving necessary context.
- Re-ranking: Secondary scoring or ordering of candidate passages after initial retrieval.
- ChromaDB — Vector Database
- Semantic Search and Embeddings Tutorials (examples and background)
- Retrieval-Augmented Generation overview (research context)