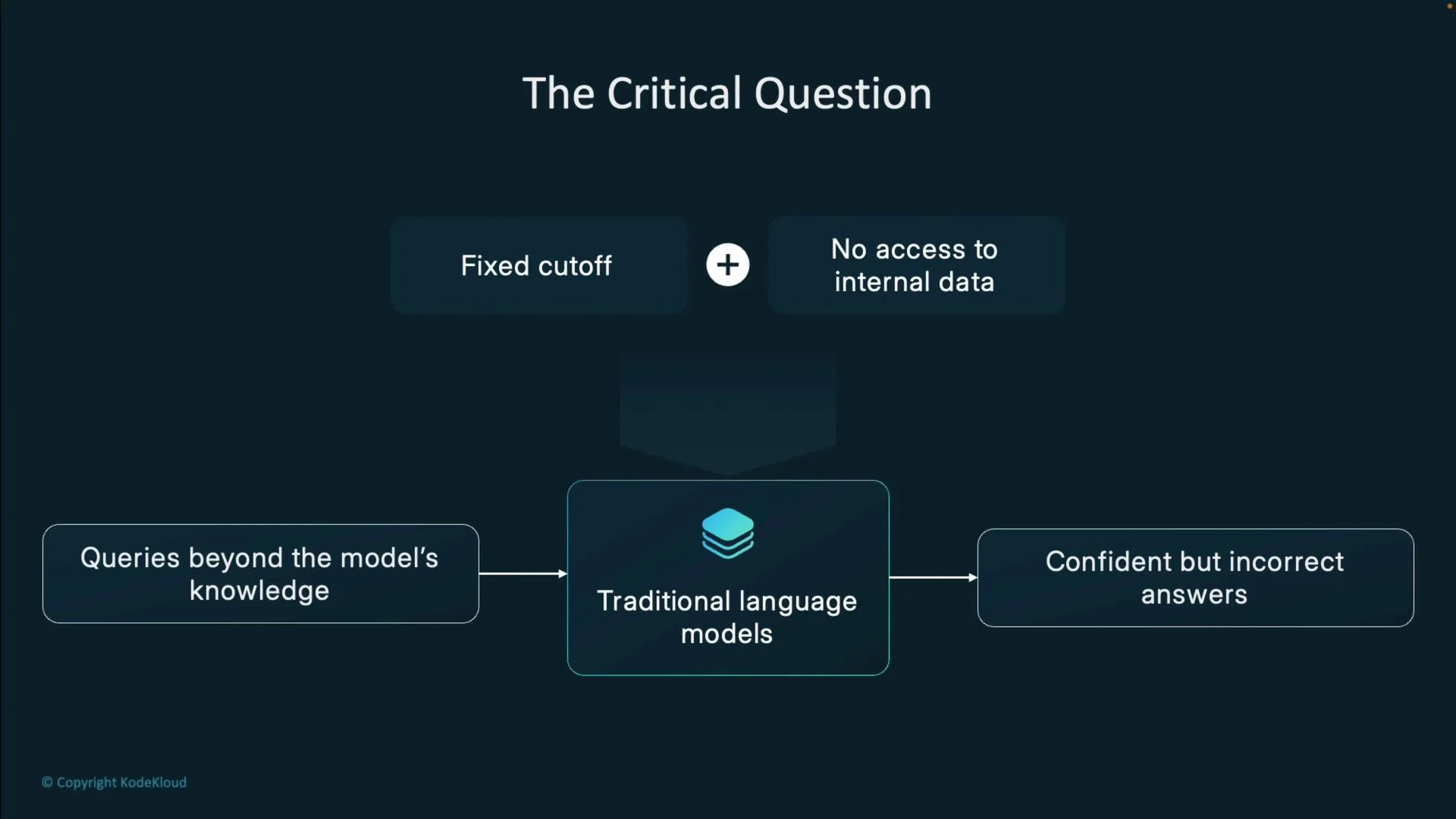
Why RAG?
RAG solves key limitations of standalone large language models (LLMs) and conventional search:- Knowledge cutoff: LLMs are trained on data up to a fixed date and can’t natively access newer information.
- Hallucination risk: Without grounding, LLMs may produce fluent but incorrect answers.
- No private data access: Public LLMs don’t access internal documents unless those documents are ingested.
- Static knowledge base: LLMs can’t incorporate real-time updates or dynamic data without an external retrieval step.

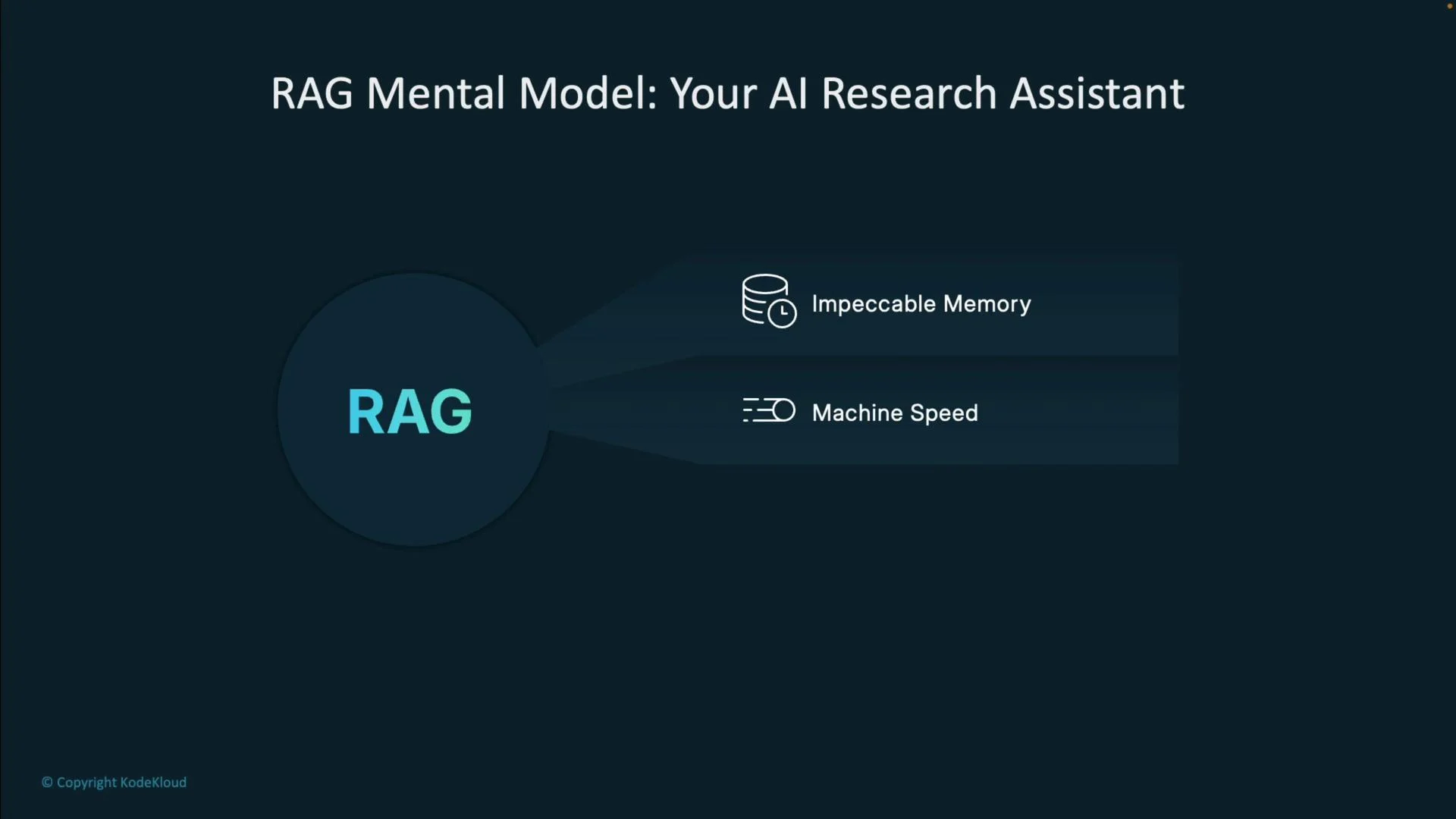
RAG mental model
Think of RAG as a research assistant that:- Finds the most relevant source material.
- Extracts the most useful excerpts.
- Writes an answer that is explicitly grounded in that evidence.
- Retrieval: Search your knowledge base using semantic similarity (often in combination with keywords).
- Augmentation: Select, rank, and assemble the most relevant document chunks.
- Generation: The LLM composes answers conditioned on the retrieved evidence.
RAG pipeline — high level
At a high level, RAG is composed of three systems that work together: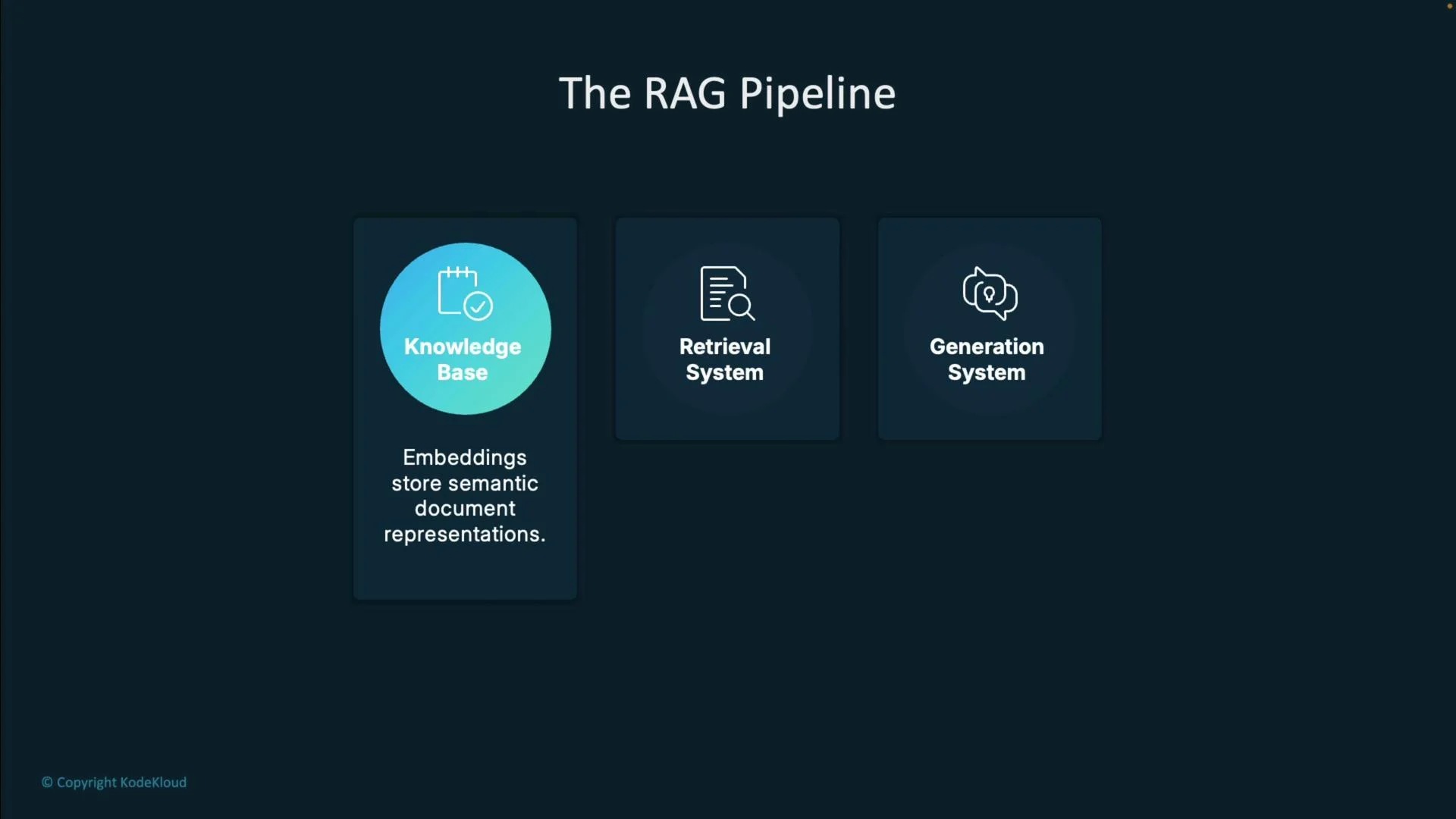
Document ingestion and vector storage
Ingestion steps (practical):- Chunk documents into smaller passages (chunking).
- Convert each chunk to an embedding vector that captures semantic meaning.
- Store embeddings and metadata in a vector database for fast similarity search.
- Smaller chunks: higher retrieval precision, less surrounding context.
- Larger chunks: more context, but retrieval may be less focused if only a piece is relevant.
Balance chunk size to suit your use case. For conversational QA, a few paragraphs per chunk often work; for step-by-step procedures, preserve steps with slightly larger chunks.
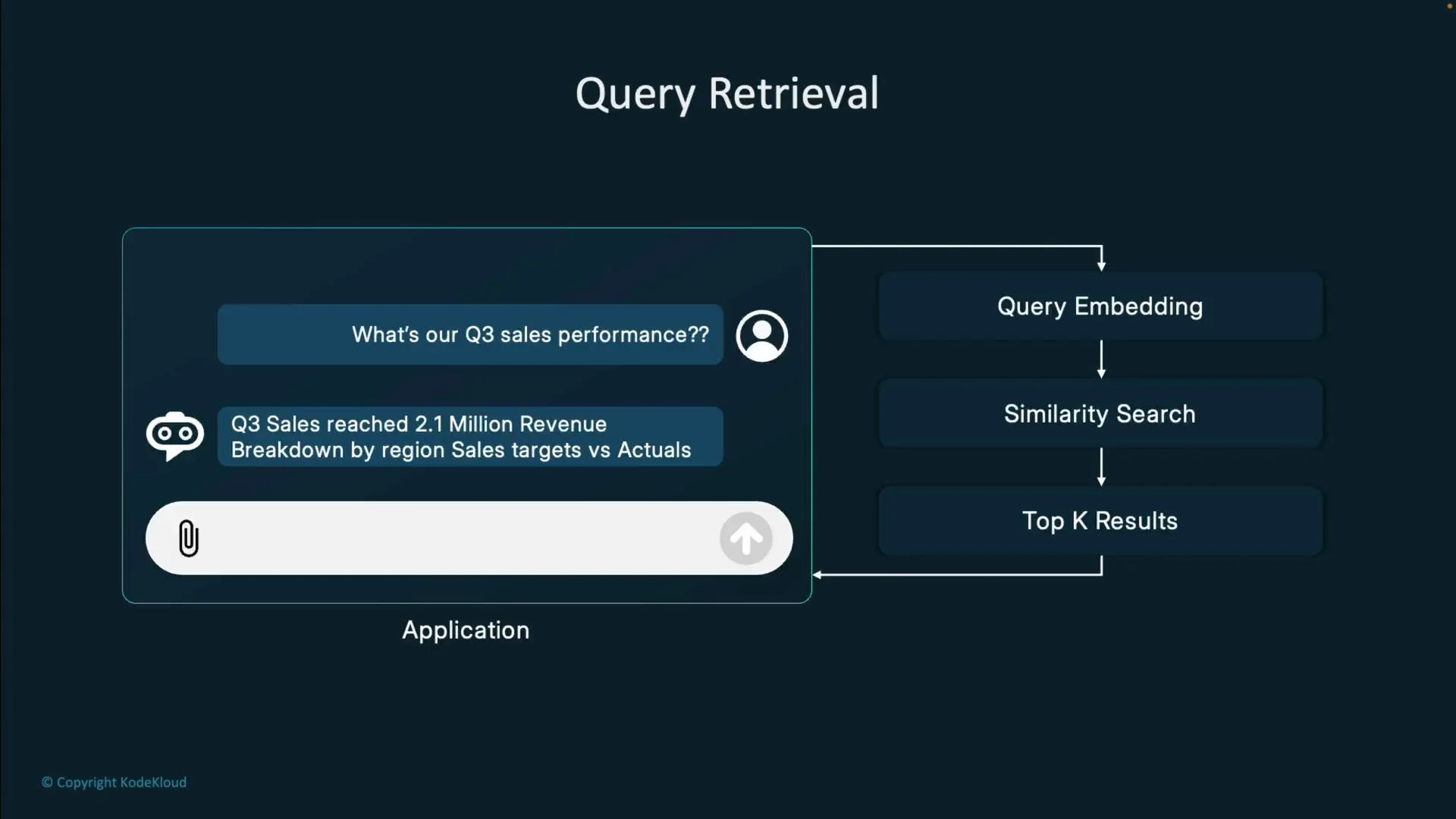
Query processing and similarity search
Basic flow:- Convert user query into a query embedding.
- Perform similarity search between query embedding and stored embeddings (commonly cosine similarity).
- Return the top-K most similar chunks as candidate context.
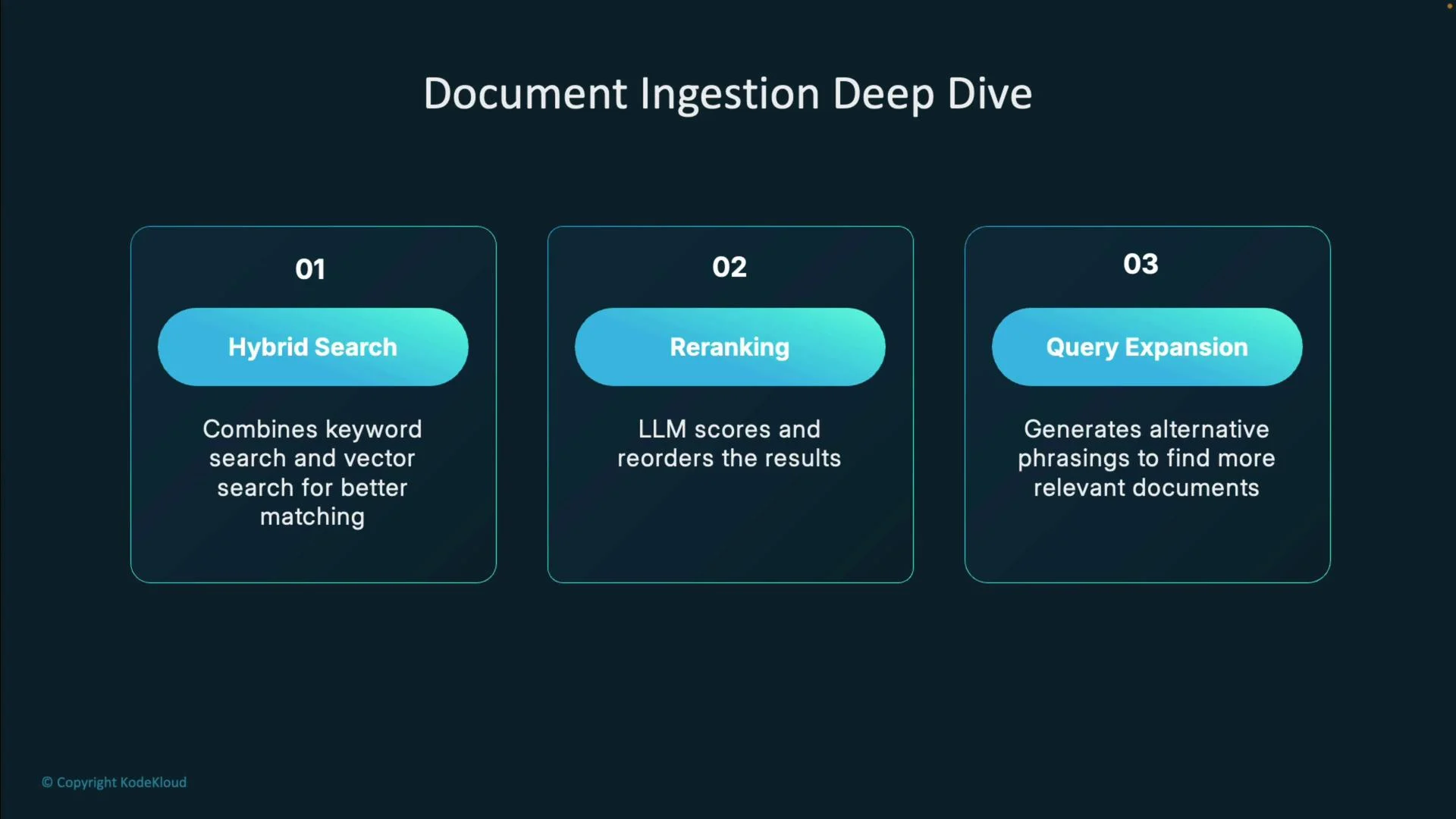
Improving retrieval quality
After initial retrieval, use these techniques to improve precision and recall:- Hybrid search: combine keyword (BM25) with vector search for exact term matching plus semantic coverage.
- Reranking: use an LLM or a learned relevance model to reorder candidates.
- Query expansion: generate alternate phrasings, synonyms, or augmented queries (e.g., doctor ↔ physician).
Generation with context
When generating, the system constructs a prompt that includes:- The original user query.
- Selected retrieved chunks (trimmed or prioritized as needed).
- Instructional prompt engineering to require grounding and citation.

Primary challenges in production RAG systems
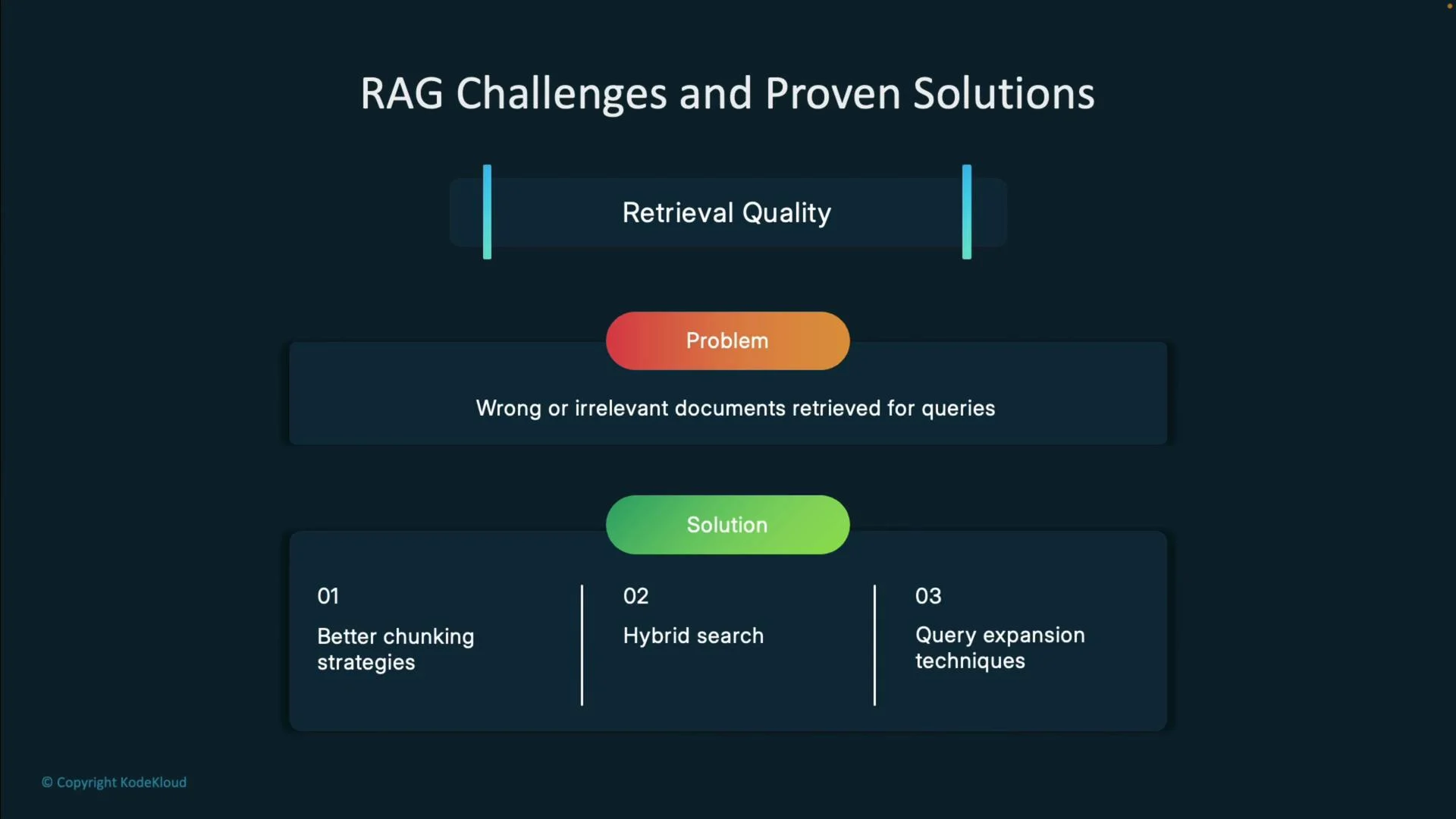
Common production issues and mitigations:- Retrieval quality — wrong or irrelevant documents returned
- Causes: poor chunking, weak embeddings, narrow search.
- Solutions: tune chunking, use hybrid search, reranking, domain-specific embeddings.
-
Context length management — too much or too little context
- Causes: feeding the LLM too many tokens or omitting key context.
- Solutions: dynamic context windowing, relevance scoring, summarize/condense retrieved chunks.
-
Hallucination — the LLM invents facts that aren’t in the sources
- Mitigations: explicit grounding instructions, confidence scoring, model fine-tuning (when available), corroboration checks against evidence.
-
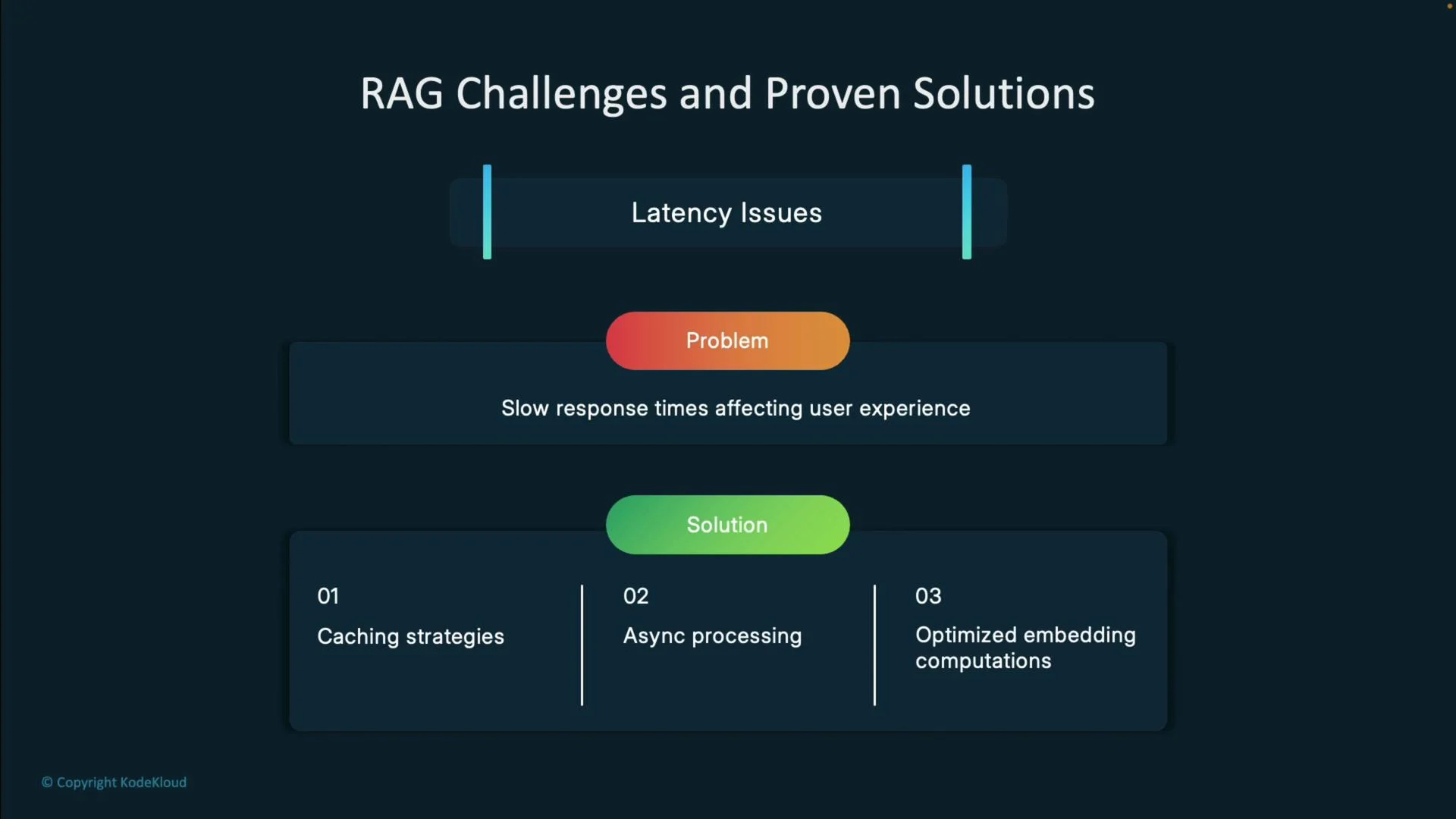
Latency — slow responses in query → embed → search → generate loops
- Causes: repeated embeddings, synchronous pipelines, heavy reranking.
- Solutions: cache embeddings and frequent queries, async workflows, batch embedding, GPU acceleration, index partitioning.
Be careful when ingesting sensitive data. Enforce access controls, data masking, and compliance reviews before storing private or regulated information in vector stores.
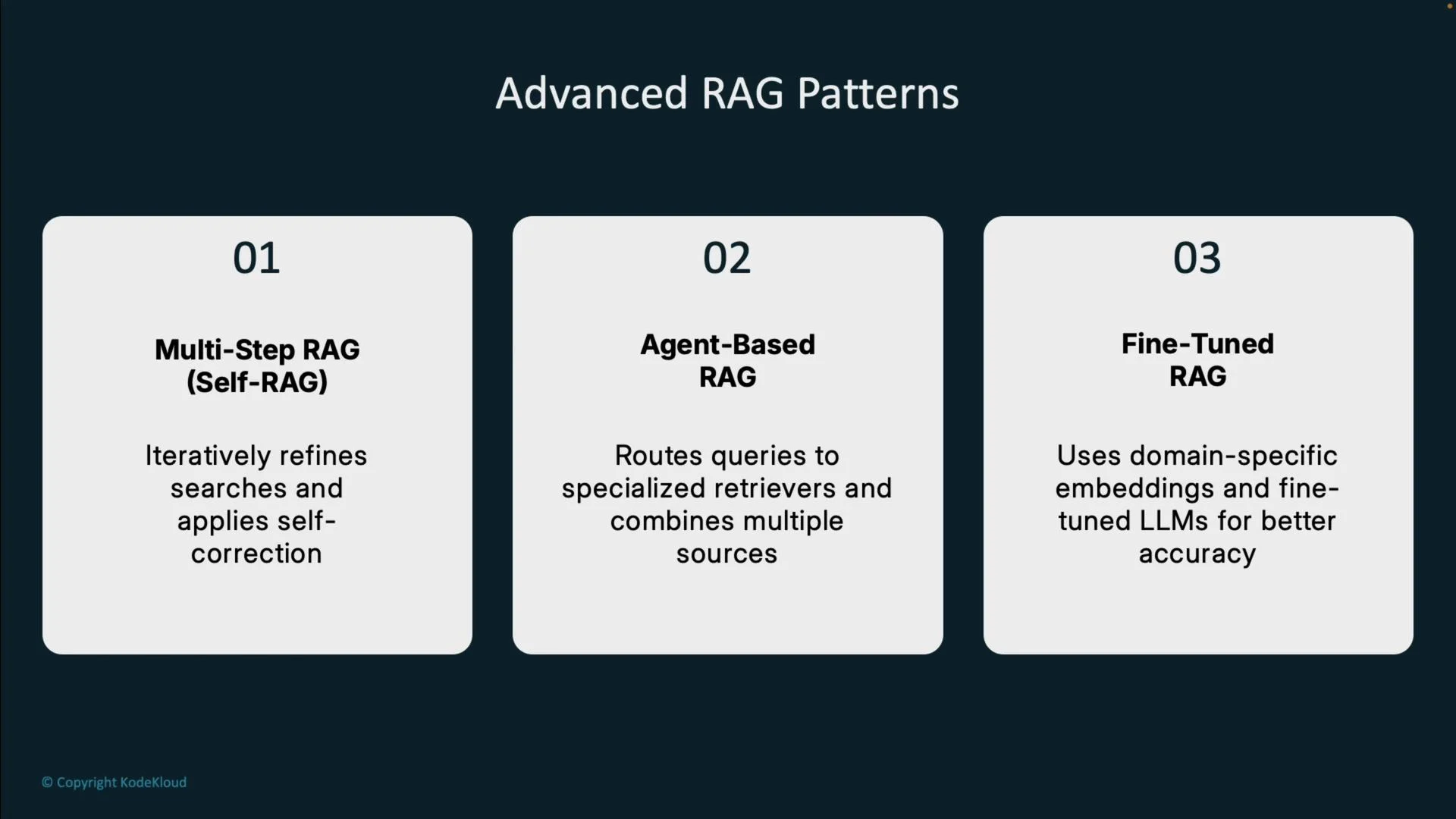
Advanced RAG patterns
Beyond the basic retrieve-and-generate loop:- Multi-step RAG: iteratively refines queries, inspects intermediate results, and performs verification loops to self-correct.
- Agent-based RAG: routes queries to specialized retrievers (agents) or external APIs/databases depending on query type.
- Fine-tuned RAG: uses domain-specific embeddings and fine-tuned LLMs to boost relevance and factuality for particular verticals.
Implementation checklist
Use this checklist when planning a RAG system:- Ingestion: define supported document types and chunking strategy.
- Embeddings: choose model(s) suitable for your domain.
- Vector DB: confirm latency, scale, and replication needs.
- Search strategy: decide on pure vector, hybrid, or multi-stage search.
- Reranking & filtering: implement LLM-based or learned rerankers if needed.
- Prompt design: require grounding and citations.
- Monitoring: track retrieval relevance, hallucination rates, latency.
- Security & compliance: protect sensitive embeddings and data access.
Summary
RAG couples semantic retrieval with LLM generation to produce more current, domain-aware, and evidence-grounded responses than an LLM alone. Successful RAG deployments focus on thoughtful ingestion and chunking, robust similarity search and reranking, careful prompt design, and production considerations (latency, hallucination, security). Further reading and references:- OpenAI on Retrieval-Augmented Generation: https://platform.openai.com/docs/guides/retrieval
- Vector databases: Pinecone (https://www.pinecone.io/), FAISS (https://github.com/facebookresearch/faiss), Weaviate (https://weaviate.io/)
- Hybrid search concepts: BM25 + vector search overviews and best practices