- Run models locally for lower latency and data privacy.
- Use CLI or GUI workflows to pull, run, and manage models.
- Integrate local models into apps via a local API (default:
127.0.0.1:11434).
Install (Linux / WSL)
On Linux or Windows Subsystem for Linux, install with the curl installer:The installer will prompt for
sudo when needed and installs Ollama under /usr/local by default. Running this command inside WSL is the fastest way to get set up on Windows using the Windows Subsystem for Linux environment.ollama to view the top-level help and available subcommands.
Command-line overview
Running theollama command with no arguments prints the high-level help and available commands:
Windows / GUI installer
The macOS and Windows installers include an optional GUI. The GUI lets you browse models, view metadata, and download models with a few clicks. The installer keeps your models if you upgrade an existing install.
Model selection (GUI)
If you prefer a graphical workflow, the GUI lets you preview model descriptions, inspect sizes and parameters, and download models directly.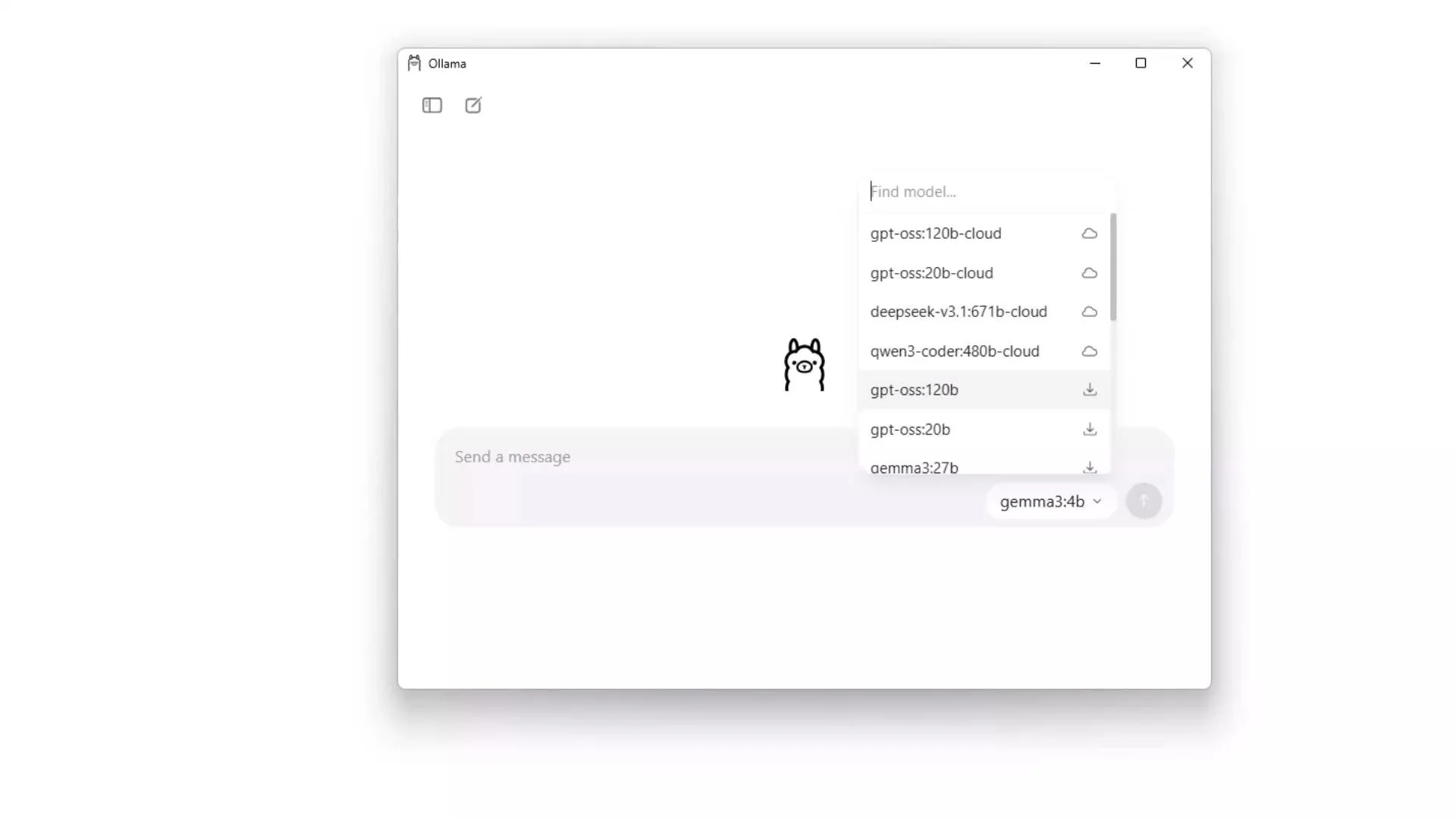
Common commands
Use the table below as a quick reference for common Ollama commands and their use cases.Listing installed models
From the CLI,ollama list shows models you have already downloaded:
Inspecting a model
Useollama show <model> to view architecture, parameter counts, context length, quantization, and default runtime parameters. Note: some models include special stop tokens that look like angle-bracket tokens — always display or reference those tokens inside code formatting to avoid MDX parsing issues.
Downloading and running models
You can eitherpull a model to download it only, or run a model to download (if necessary) and start an interactive session:
run command finishes downloading, you’ll be dropped into the model prompt and can start sending input (for example, “Tell me a funny joke about Python”).
Model catalog (web)
Browse available models, sizes, and suggested CLI commands at ollama.com/models. The web catalog is a good place to discover model details and recommended usage examples.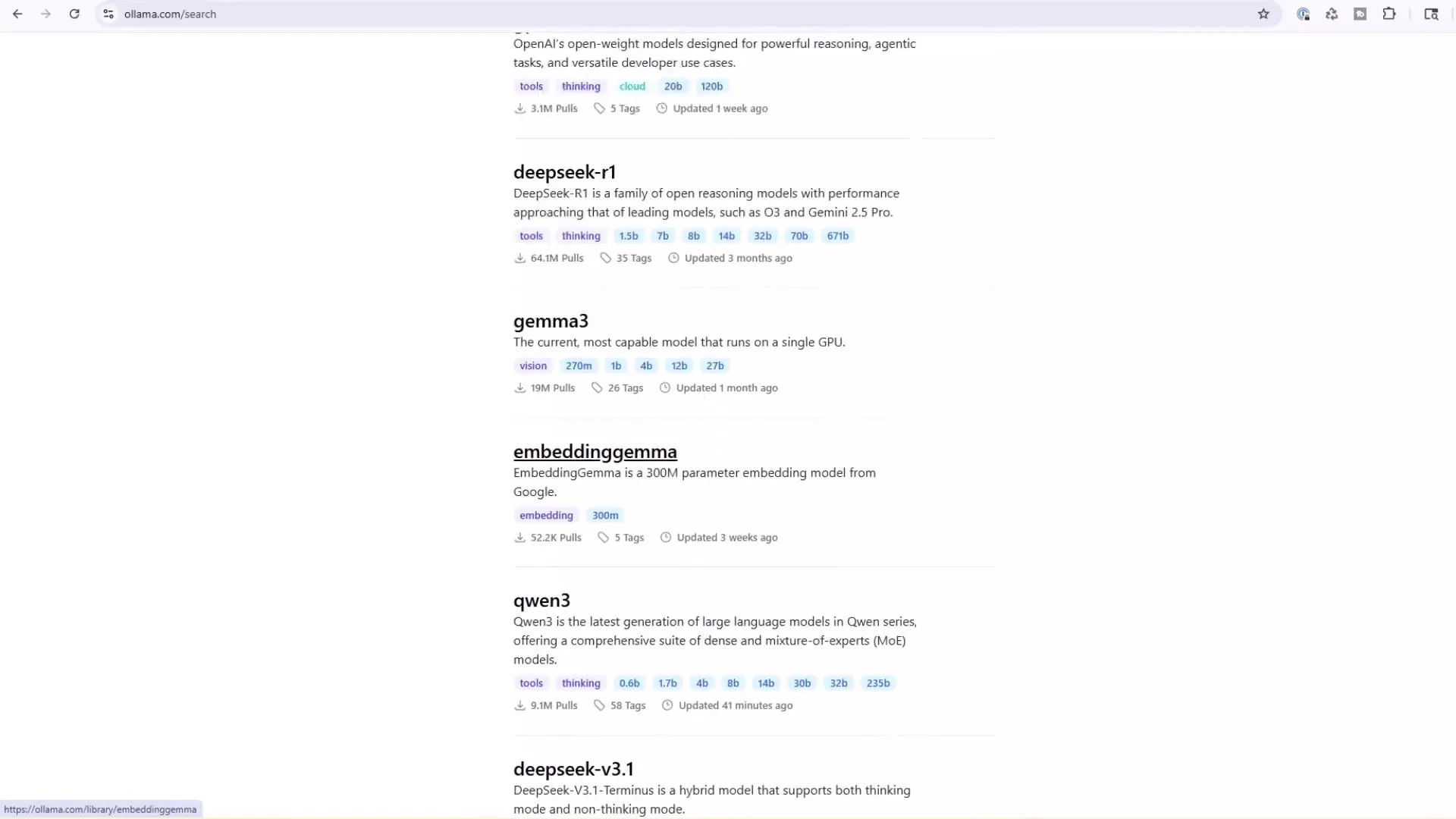
Example model detail page (qwen3:0.6b)
Model detail pages show specifications and provide a copyable “Run” or “Pull” command for convenience.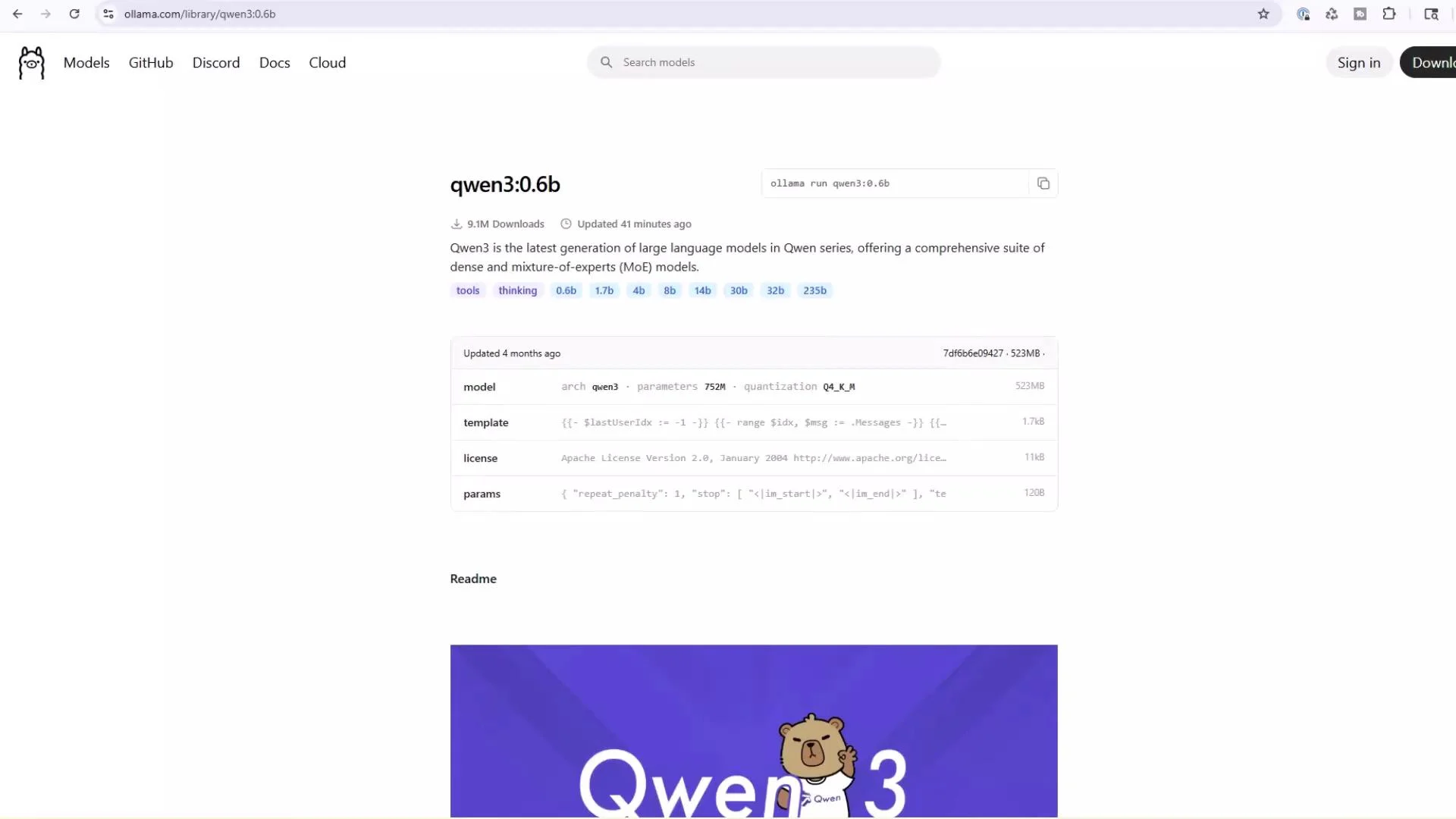
Monitoring and stopping models
ollama list— models downloaded to your machine.ollama ps— currently running models and resource usage.ollama stop <name>— stop a running model.
Locally running models can be resource intensive. If a model uses GPU resources, ensure your drivers and CUDA runtime are compatible. Also note the Ollama API defaults to
127.0.0.1:11434 (local only) — exposing this port to untrusted networks can be a security risk.Notes on model behavior and tuning
- Repetitive or very long outputs can usually be controlled by adjusting
temperature,top_p, and stop tokens. - Use clear prompts and explicit stop tokens to avoid unbounded generation.
- For deterministic or concise replies, lower
temperature(e.g.,0.0–0.3) and specify stop tokens. - For more creative output, raise
temperatureand increasetop_p.
Next steps
- Programmatic usage: call the local Ollama HTTP API at
127.0.0.1:11434from your application. - Integrations: embed local models in microservices, chat UIs, or data pipelines.
- Explore the model catalog: https://ollama.com/models for more models, sizes, and recommended CLI commands.
- Ollama website: https://ollama.com/
- Model catalog: https://ollama.com/models