- “The cat sat on the mat.”
- “A feline rested on the rug.”


- A single fixed-length vector represents an entire sentence or passage (not one vector per token).
- They build on contextual transformer encoders (BERT, RoBERTa, etc.) and add pooling plus a siamese/bi-encoder setup so pairs of texts can be compared efficiently.
- Because inputs are encoded independently, document embeddings can be precomputed and stored for fast retrieval at scale.
Precompute and index document embeddings when possible. That greatly reduces latency at query time: encode the query on the fly and perform a fast nearest-neighbor lookup against the precomputed vectors.
- Query encoder: encodes a user query into a semantic embedding at request time.
- Document encoder: converts documents into embeddings that can be precomputed and indexed.
- Similarity metric: usually cosine similarity (or inner product) is used to find nearest neighbors.
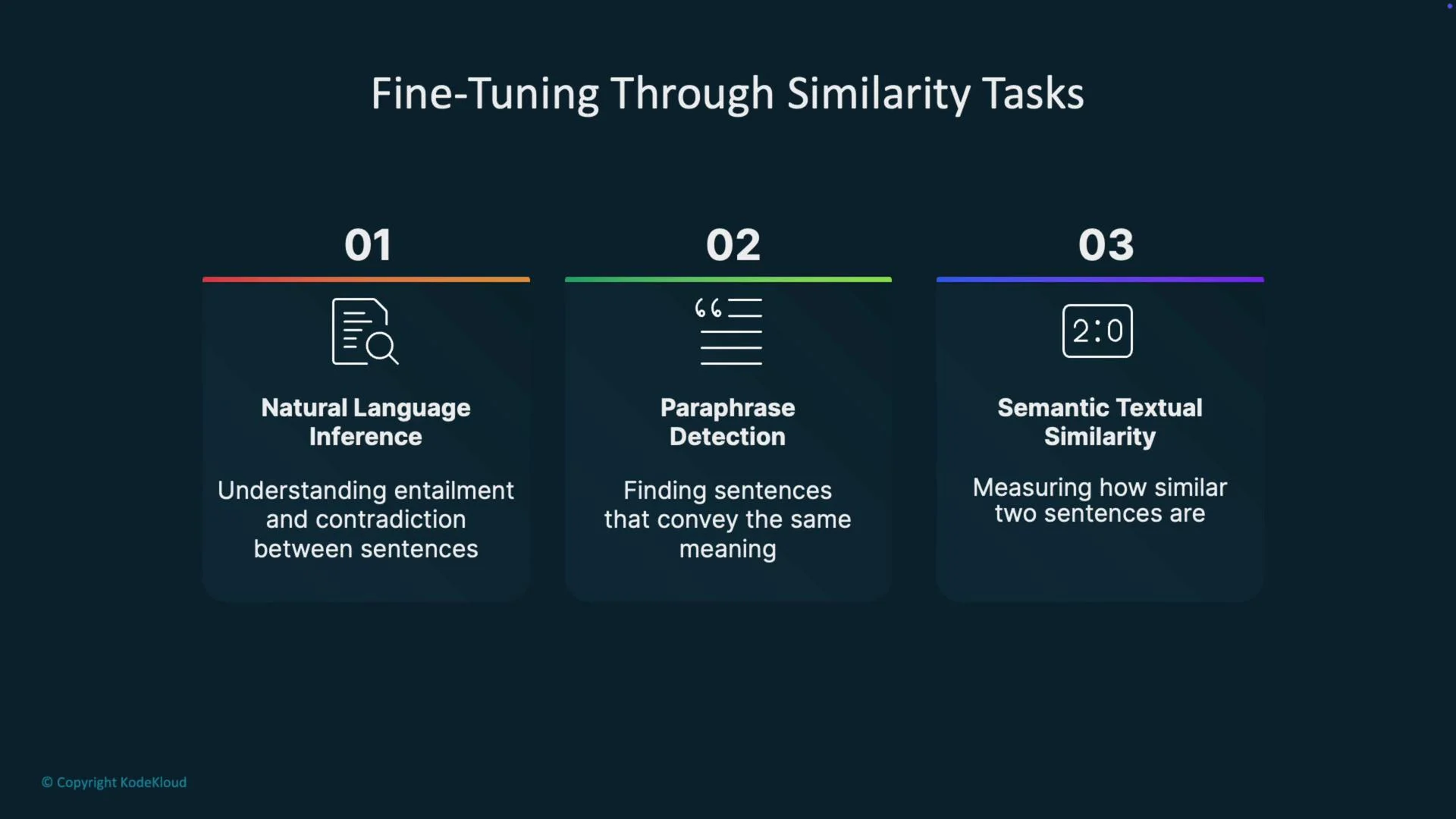
- Natural Language Inference (NLI): label pairs as entailment, contradiction, or neutral so the model learns entailment/contradiction relationships.
- Paraphrase detection: determine whether two sentences convey the same meaning with different wording.
- Semantic Textual Similarity (STS): predict a continuous similarity score for sentence pairs.

- Encode user query: the query encoder produces a query embedding.
- Vector search: perform nearest-neighbor search against precomputed document embeddings stored in a vector database or ANN index.
- Return top-k documents: optionally re-rank results and pass them to a large language model for final response generation.

- “Engine misfires and rough idle causes” → 0.89 (highly related)
- “Common ignition system problems” → 0.81 (related)
- “How to change oil filter” → 0.32 (unrelated)
- Precompute embeddings for static corpora to minimize query latency.
- Use approximate nearest neighbor (ANN) indices (HNSW, Faiss, Milvus, Pinecone, etc.) for fast retrieval at scale.
- Balance vector dimensionality and model size against query throughput and memory cost.
Be mindful of compute and storage: larger models produce higher-quality embeddings but require more memory and slower inference. For large document collections, ANN indices and shard/replica strategies are essential to meet latency and throughput targets.
- They capture semantic meaning beyond token overlap, handling synonyms and paraphrases automatically.
- Multilingual models enable cross-language retrieval.
- Precomputable document embeddings plus fast ANN indices enable large-scale, low-latency semantic search.
- They integrate easily into retrieval pipelines and pair effectively with LLMs for retrieval-augmented generation (RAG).


- Hugging Face — Sentence Transformers models and docs
- Faiss — Facebook AI Similarity Search
- Vector search overview — Pinecone
- KNN and ANN basics — Milvus documentation