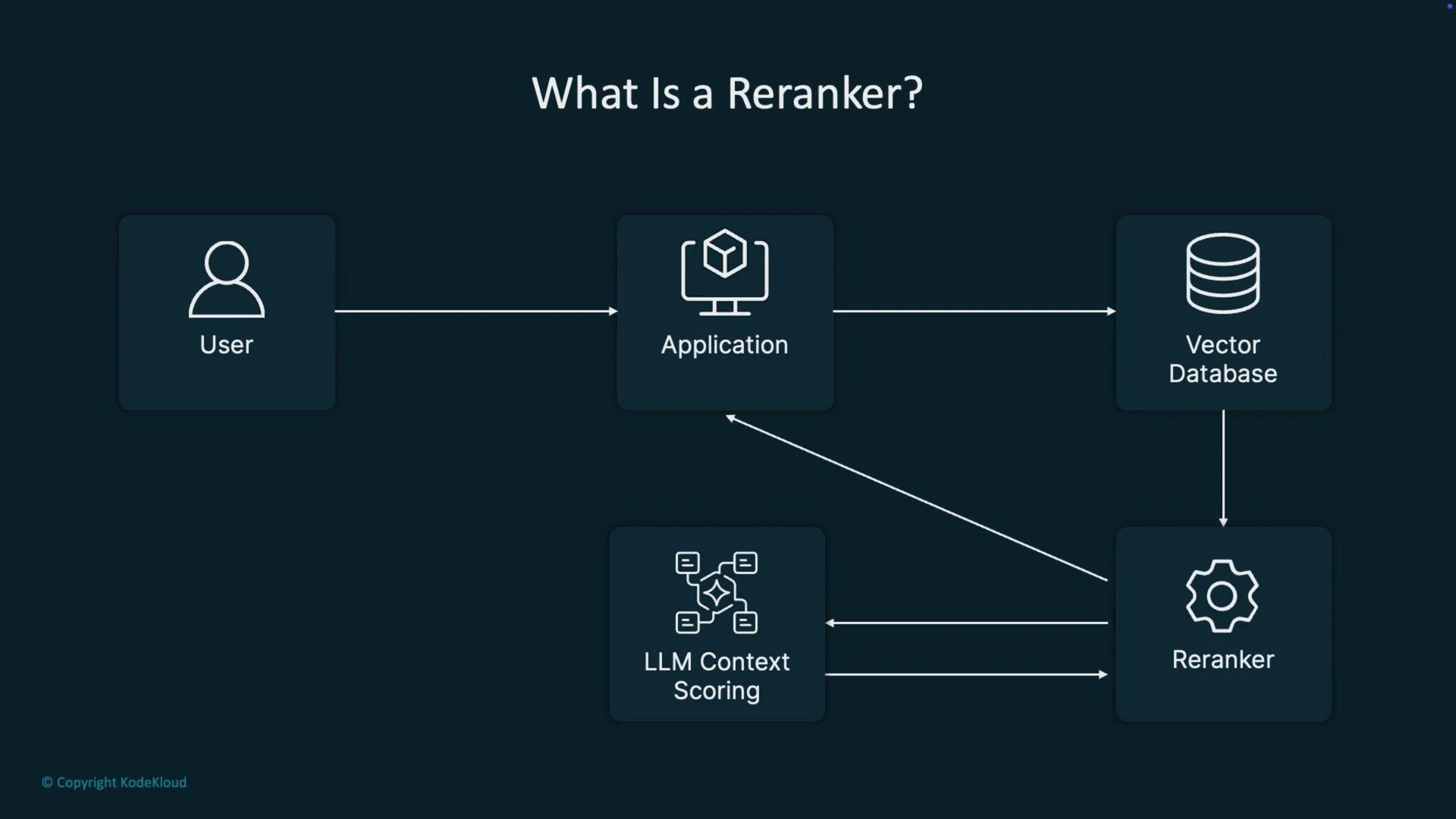
- A user submits a query to an application.
- The application encodes the query and queries a vector database or first-stage retriever.
- The retriever returns the top K candidate documents or passages (fast, high-recall).
- A reranker evaluates the top K candidates using richer contextual information and assigns relevance scores.
- The pipeline selects the top N reranked items (N ≤ K) for final answer generation or display.
Rerankers are most effective when the initial retrieval stage achieves good recall but struggles with precision or contextual disambiguation. They trade a small amount of latency for noticeably higher final-answer quality.
- Vector similarity (e.g., bi-encoders) surfaces semantically similar items but can return items that match on keywords, entities, or topics without capturing full contextual intent.
- A reranker uses joint query-document context (via a cross-encoder or LLM) to reason over subtle signals and reorder candidates by true relevance.
- This reduces noise and ensures the final LLM or application consumes higher-quality evidence for generation or decisioning.
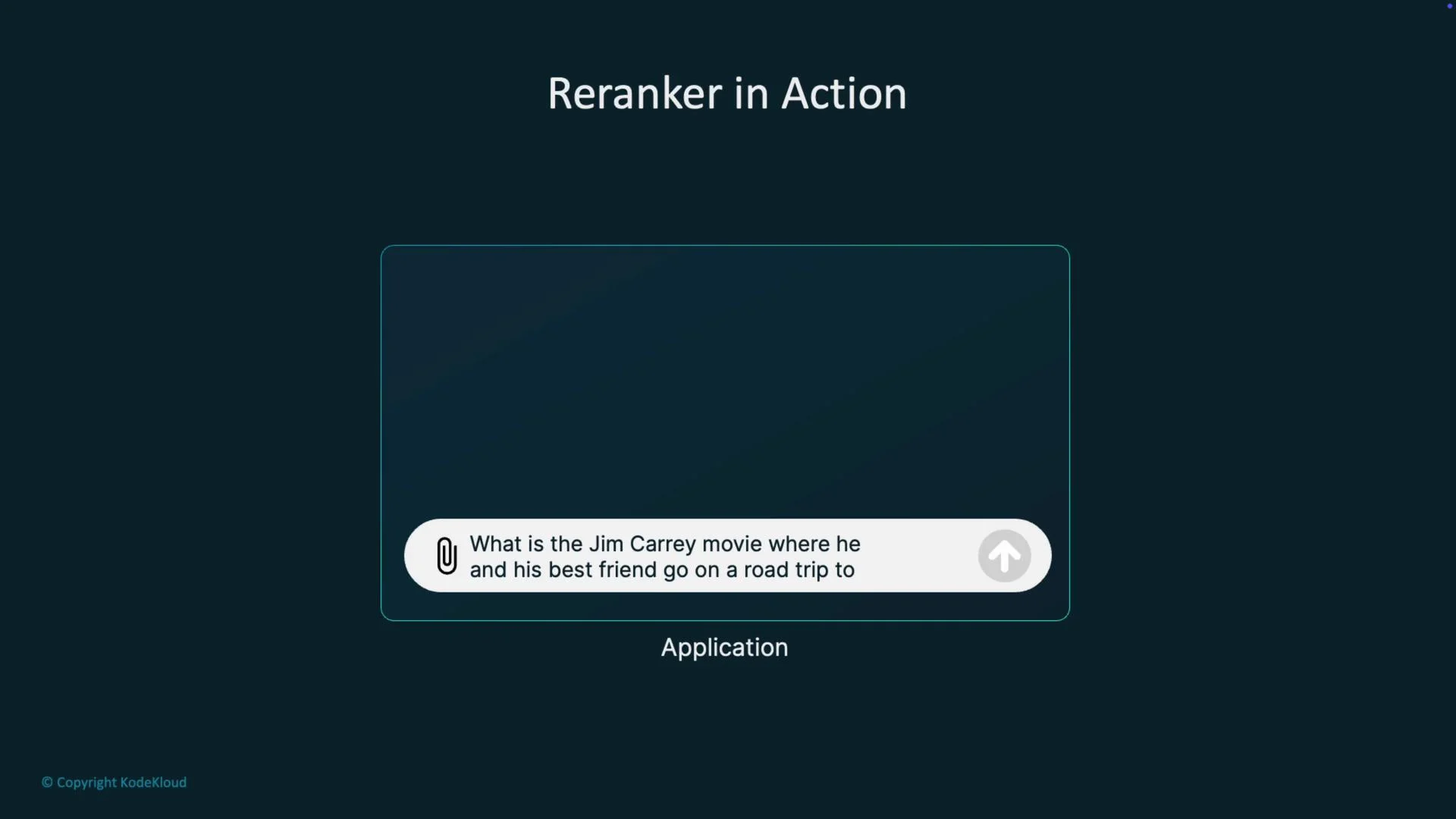
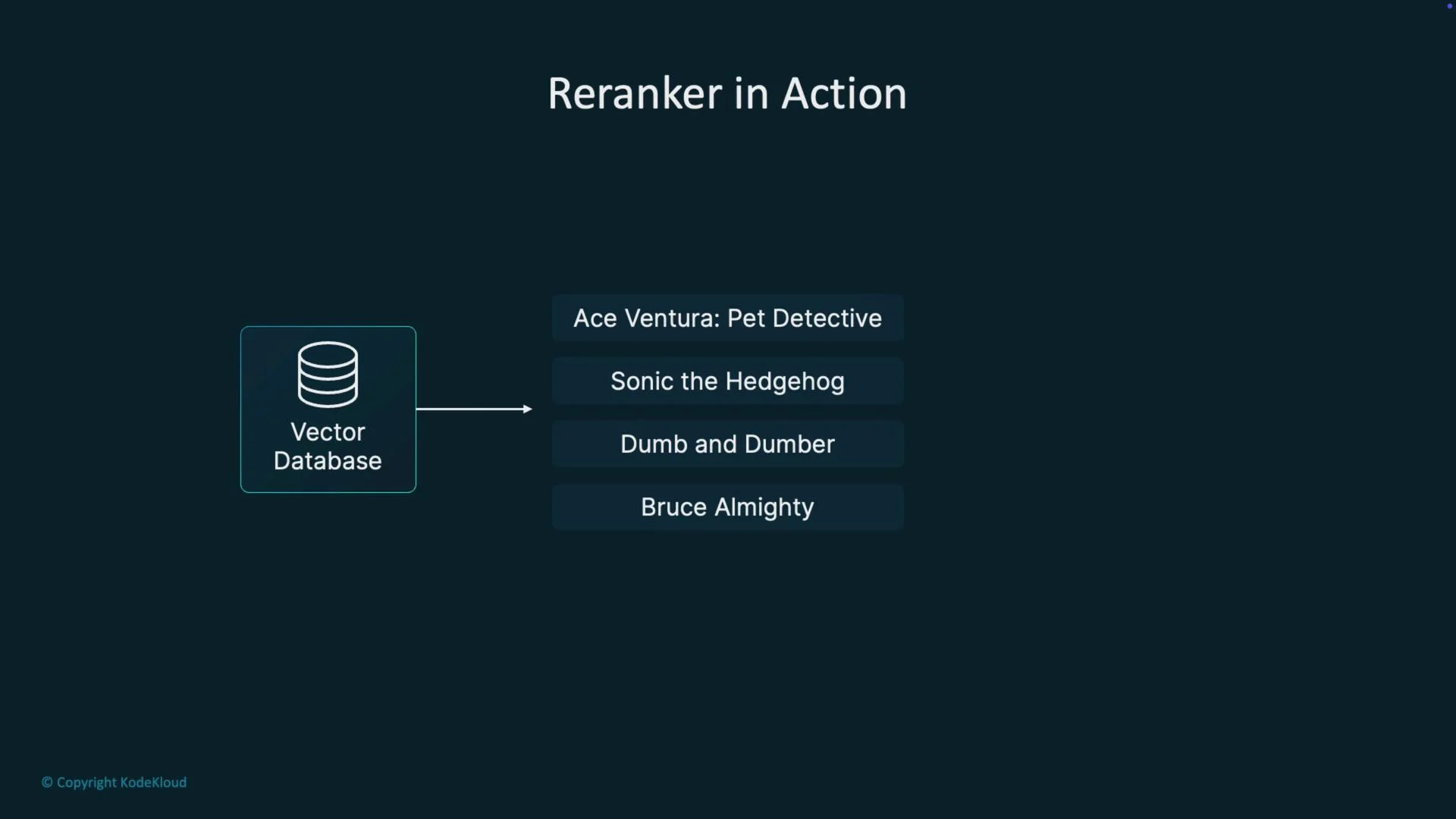

- User query → Initial retrieval (Top K)
- Reranker scores top K with a cross-encoder or LLM (joint scoring)
- Select top N reranked candidates → Final LLM or downstream use
- Scalar scores (e.g., 0.0–1.0)
- Likelihood labels (e.g., unlikely / likely / very likely) These signals are used to sort candidates before final generation or presentation.

- Improves specificity and precision of the final results
- Increases robustness to noisy or semantically similar but irrelevant candidates
- Prioritizes contextually correct documents for LLM generation, reducing hallucinations and improving factuality
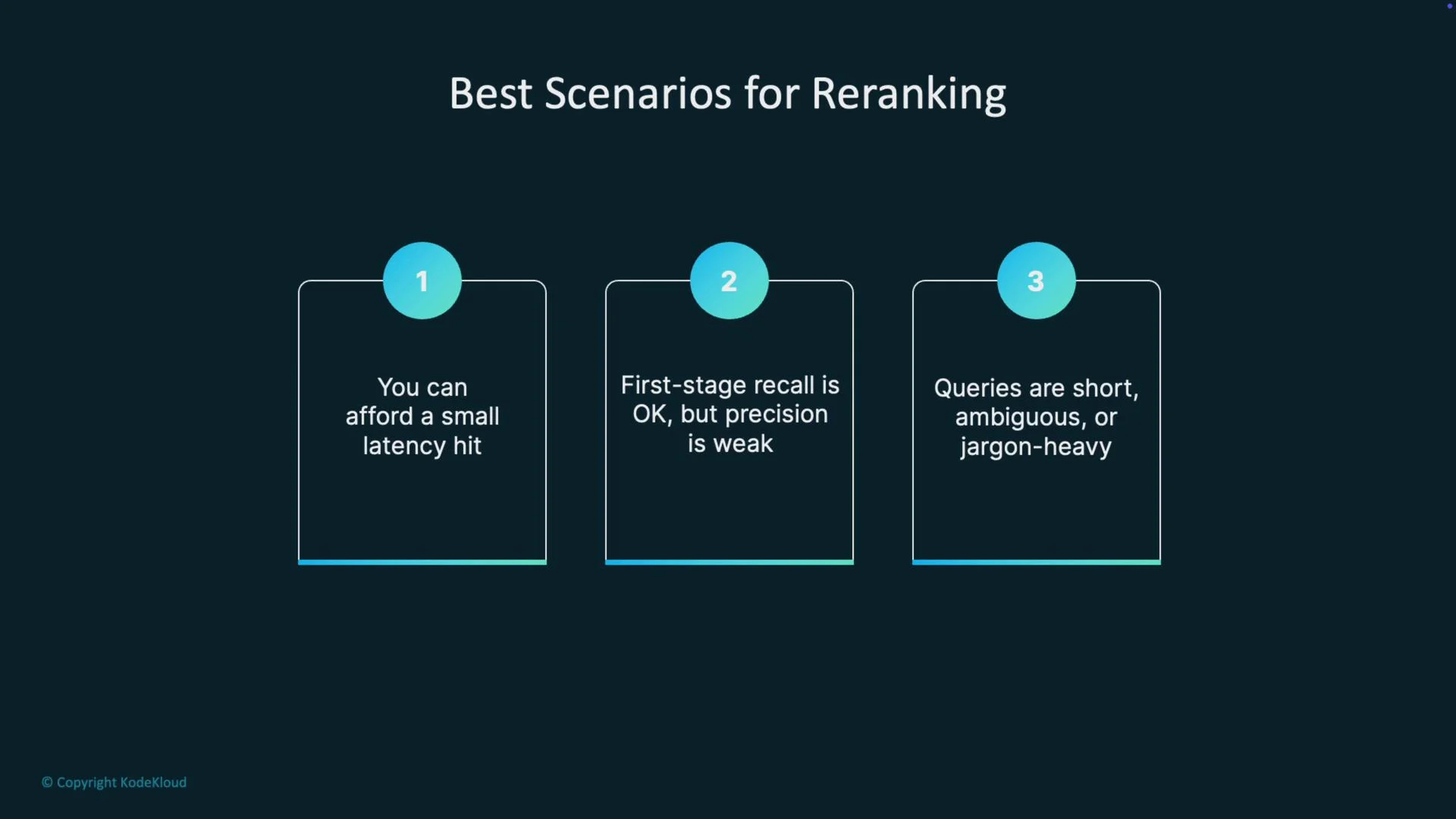
- You can tolerate a small extra latency in exchange for higher precision
- The first-stage retriever returns many semi-relevant chunks (high recall, low precision)
- Queries are short or ambiguous and require contextual disambiguation
- The domain contains heavy jargon or domain-specific phrasing that needs deeper matching
Use reranking when the improvement in final-answer precision justifies additional compute and latency. For latency-sensitive applications, consider hybrid configurations such as smaller reranker models or reducing K / N values.
Common architectural pattern
Practical considerations
- Cost & latency: Rerankers add compute; choose model size and K carefully.
- Candidate sizes: Typical flows use K (retriever) large enough for recall, then N (reranker output) small enough for efficient downstream generation.
- Model choices: Cross-encoders are efficient for pairwise scoring; LLM-based rerankers provide flexible reasoning but often at higher cost.
- Retrieval-Augmented Generation (RAG) concepts and best practices: https://www.retrieval-augmented-generation.example (replace with your internal docs)
- Cross-encoders and pairwise ranking models: https://huggingface.co/docs
- Vector databases and ANN indices (Pinecone, Milvus, Faiss) for first-stage retrieval