Install Playwright and its browser binaries once per environment. In Jupyter notebooks, prefix shell commands with
!.Installation and imports
Run these commands in a Jupyter notebook cell to install Playwright, its browser binaries, and python-dotenv:
Now import the modules you will use and load environment variables:
OPENAI_API_KEY). Set the key for the openai library as shown below.
Never commit API keys to source control. Use environment variables or a secrets manager, and avoid printing your key in logs.
The browsing-and-summarizing function
Below is a complete asynchronous function you can place in a single Jupyter cell. It:- launches a headless Chromium browser with Playwright,
- sets a custom user-agent and viewport,
- navigates to a URL and waits for DOMContentLoaded,
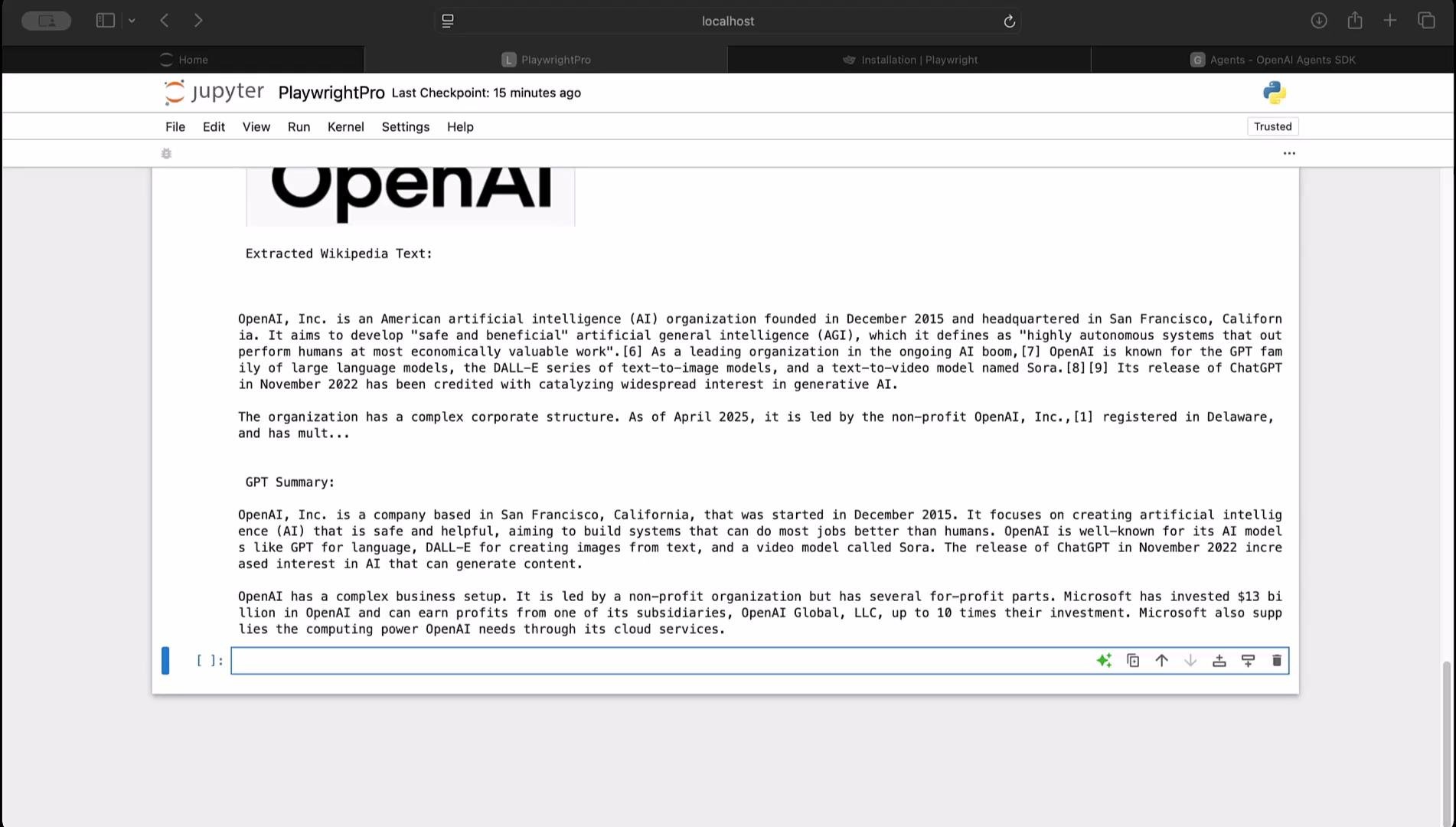
- captures and displays a full-page screenshot in the notebook,
- scrapes the first three paragraph elements from the Wikipedia content block (
#mw-content-text p), - sends the scraped text to GPT-4 for summarization,
- prints the extracted snippet and the GPT-4 summary.
Example: user agent, viewport, and running the agent
Create a user-agent string that simulates an iPhone-like browser and a viewport dictionary that mimics an iPhone 12 resolution. Then run the asynchronous function withasyncio.run.
- scrape and aggregate content from multiple pages,
- index or store extracted highlights,
- generate study aids, flashcards, or quizzes automatically,
- add navigation logic to follow links, handle pagination, or respect robots.txt.
Links and references
- Playwright Documentation: https://playwright.dev/
- OpenAI API Keys guide: https://platform.openai.com/docs/guides/api-keys
- Python dotenv: https://pypi.org/project/python-dotenv/