- What artificial intelligence enables for agents
- The role of machine learning and its learning paradigms
- Core agent capabilities: perception, reasoning/planning, and action
- Feedback loops and continuous improvement for deployed agents

What is Artificial Intelligence for Agents?
Artificial intelligence (AI) describes systems that perform tasks requiring human-like cognitive functions — learning, reasoning, problem-solving, and decision-making. For agents, AI provides the mechanisms to:- Sense the environment (user input, telemetry, logs, sensor streams)
- Process and interpret information (models, heuristics, LLMs)
- Decide and plan actions (policies, workflows)
- Act using available effectors (APIs, UI automation, actuators)

Machine Learning: The Engine of Adaptive Agents
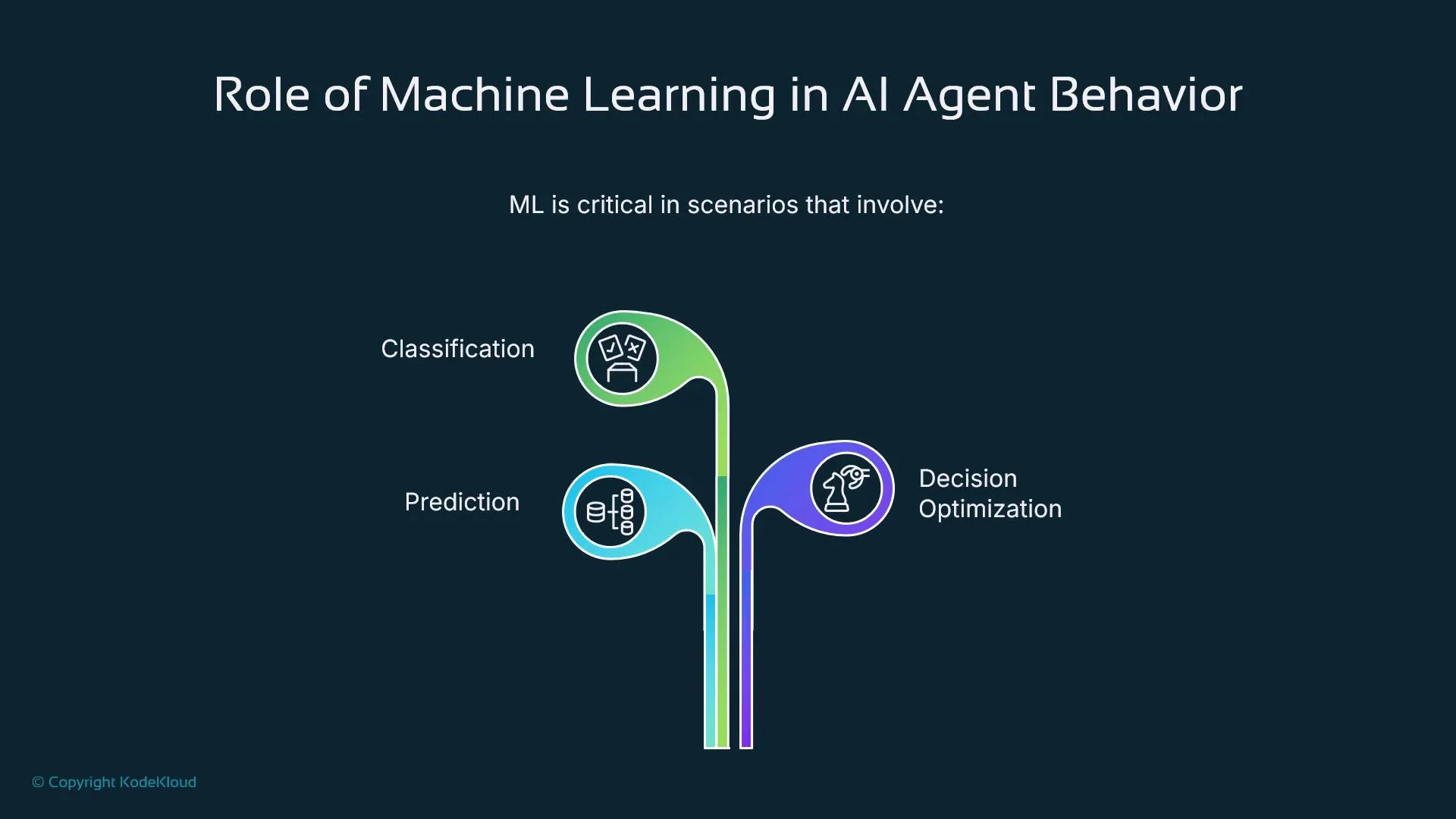
Machine learning (ML) is the subset of AI that enables systems to improve from data and experience rather than explicit reprogramming. In agents, ML shifts behavior from fixed rules to adaptive policies: agents observe outcomes, update internal models, and refine actions over time. Key ML applications for agents:- Prediction (forecasting outcomes or next best actions)
- Classification (intent detection, anomaly detection)
- Optimization (policy tuning, resource allocation)
- Personalization (tailoring responses or recommendations based on user behavior)
Learning Paradigms for Agents
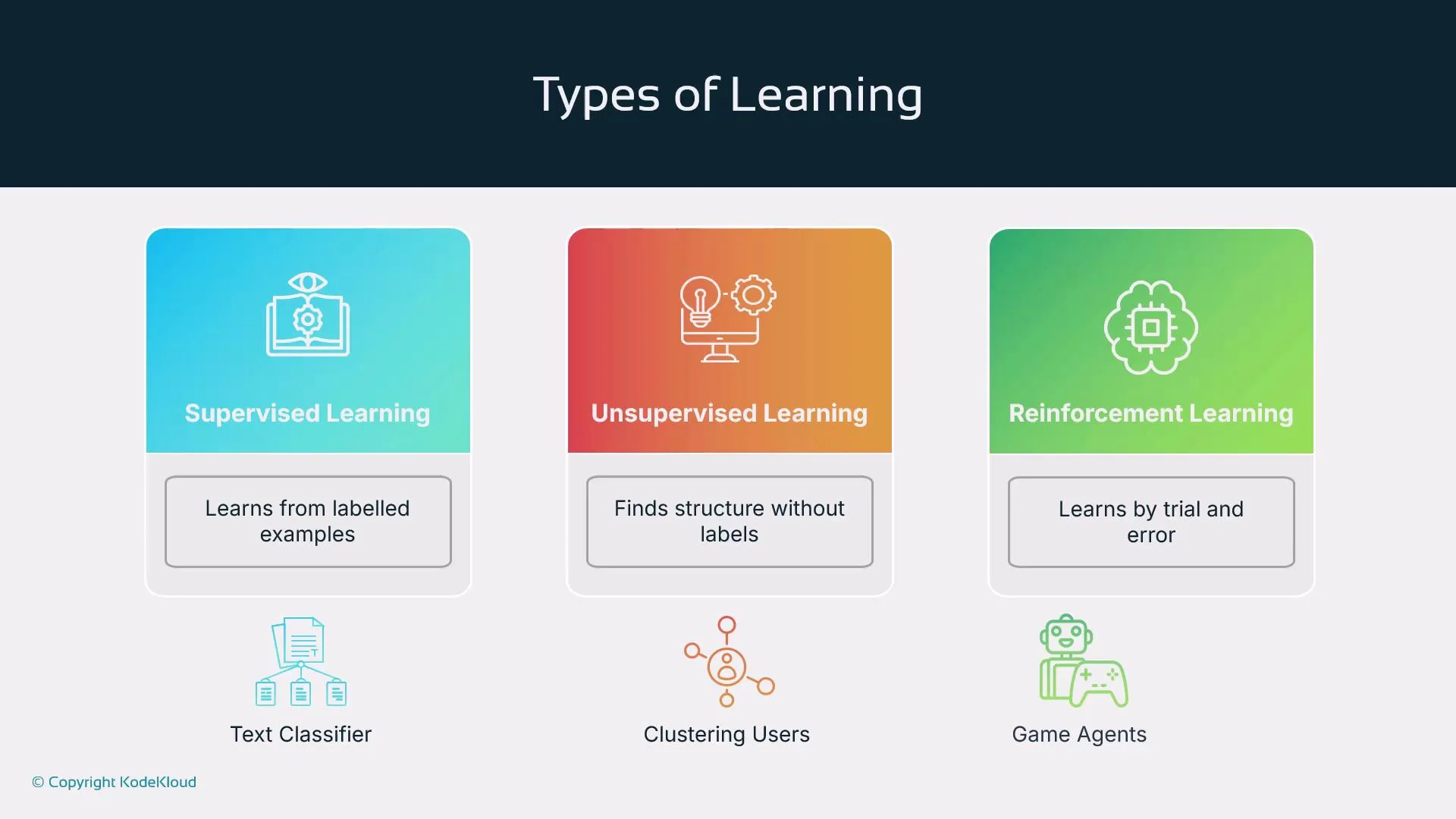
Agents typically rely on one or more of these learning paradigms. The choice depends on available data, the problem structure, and performance objectives.
Each paradigm enables different capabilities: supervised models are effective when labeled examples exist; unsupervised methods help discover latent structure; RL is suitable for goal-directed, sequential tasks where feedback can be expressed as reward.
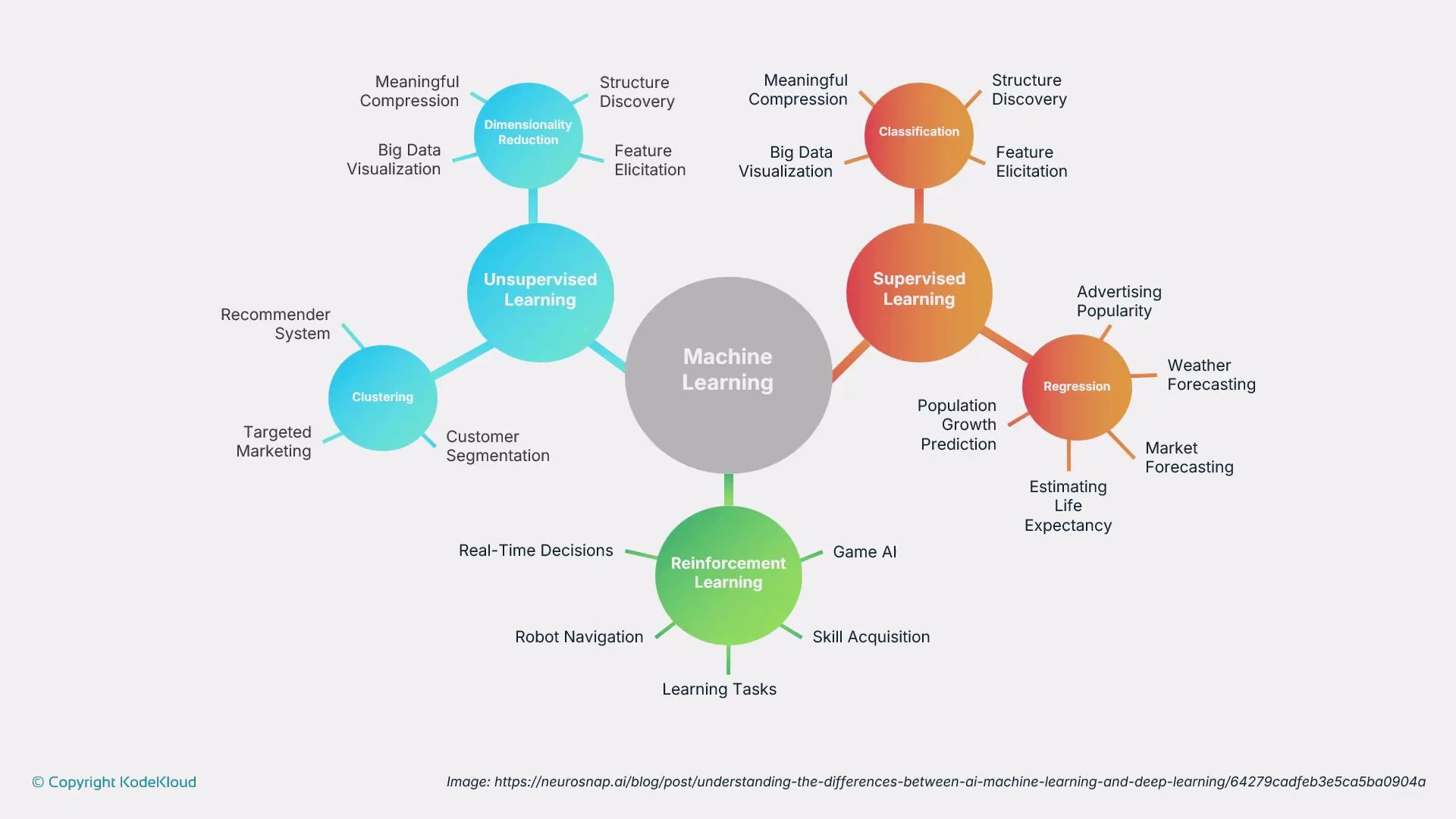
More detail on each paradigm
-
Supervised learning
- Classification: diagnostics, fraud detection, image recognition.
- Regression: sales forecasting, price/risk estimation.
-
Unsupervised learning
- Clustering: customer segmentation, exploratory analysis for recommender systems.
- Dimensionality reduction: visualization, noise reduction, feature engineering.
-
Reinforcement learning
- Goal-oriented, sequential decision making: trading algorithms, robot navigation, skill acquisition through interaction and reward signals.
Core Agent Capabilities: Sense, Think, Act
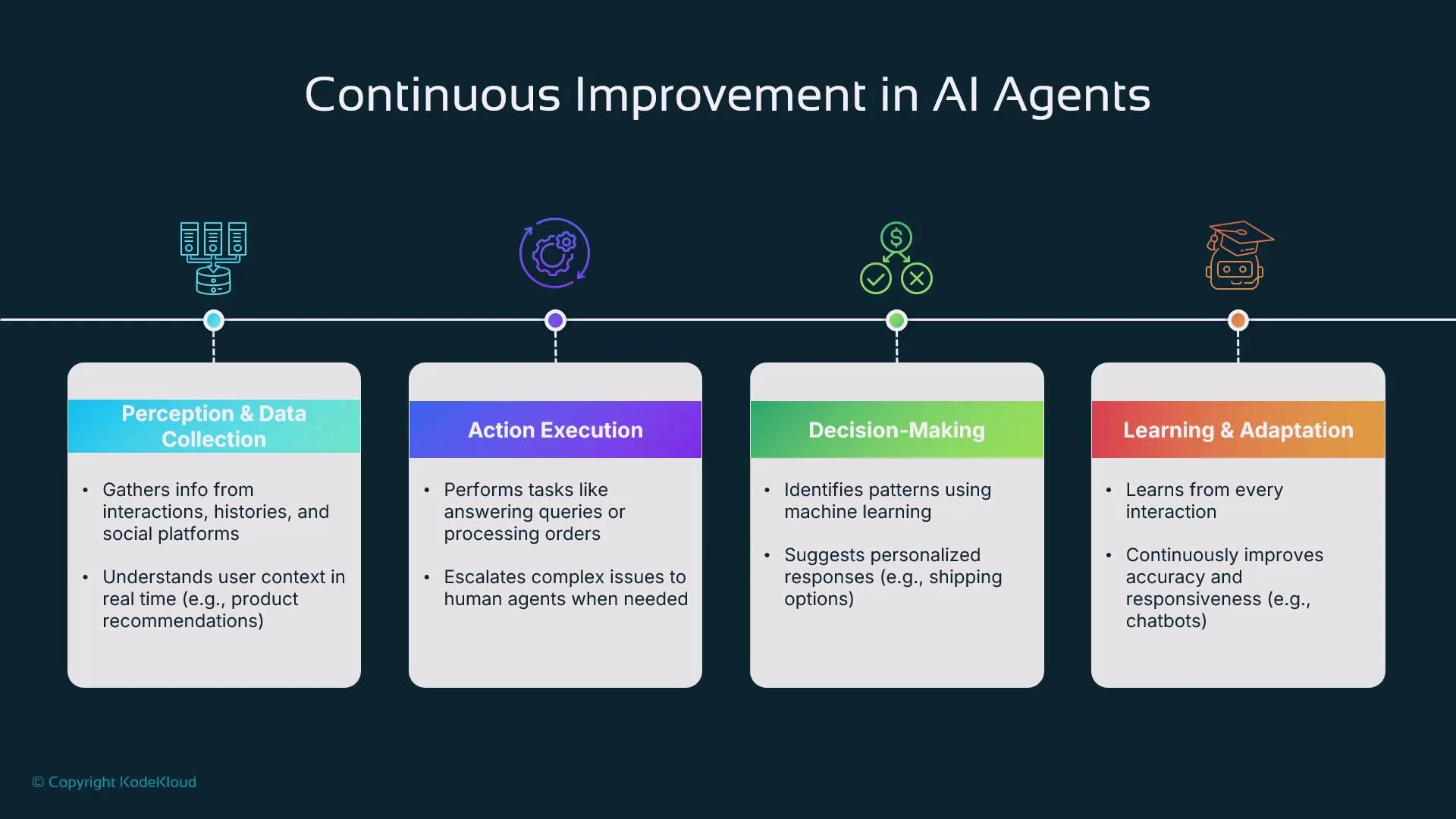
A practical way to reason about agents is the Sense–Think–Act loop:- Perception (Sense): Ingest and interpret signals — text, images, sensor telemetry, or structured logs. Techniques include NLP pipelines, vision models, and signal processing.
- Reasoning & Planning (Think): Decide what to do using internal state, learned models, or planning algorithms (e.g., search, LLM planning, RL policies).
- Action (Act): Execute tasks through APIs, automation scripts, UIs, or physical actuators. Actions change the environment and produce new percepts.
Remember: perception supplies context, reasoning selects the best action given that context, and action changes the environment — which then produces new percepts for the next cycle.

Feedback Loops and Continuous Improvement
Learning from feedback is what enables agents to improve. Feedback can be immediate (error responses, failed API calls) or long-term (user satisfaction metrics, conversion rates). Agents that log outcomes and use those observations to update models become increasingly effective. A typical continuous-improvement cycle:- Define a measurable goal (e.g., reduce mean time to resolution).
- Observe current state and collect contextual data (logs, metrics, user signals).
- Decide on an action or policy change.
- Execute the action in production or a test environment.
- Observe outcomes and compute feedback signals.
- Update models, rules, or policies; repeat.
Putting the Concepts Together
In production, agents typically:- Collect data from users, system logs, sensors, and operational telemetry.
- Use ML models and heuristics to detect patterns and make decisions.
- Execute actions (resolve tickets, recommend products, trigger workflows).
- Capture feedback to refine models, adjust thresholds, or revise policies.
- Machine Learning overview (Wikipedia)
- Reinforcement Learning (overview)
- Designing agent architectures and feedback loops — best practices