- Why testing and evaluation matter for agents
- Key performance dimensions and metrics
- Behavioral testing, success criteria, and goal completion
- Tool use, memory, and reasoning validation
- Human feedback and UX testing
- Cost evaluation and optimization techniques
- Scaling agents across users, workloads, and environments
- Metrics, logs, and continuous monitoring strategies
- An evaluation pipeline and vendor/industry recommendations
- AI agents applied to software testing


Testing agents is not a one-time QA step. Design evaluation as an ongoing feedback loop that includes automated checks, human review, and monitoring in production.
Each metric reveals a different behavioral facet. Measure these both offline (benchmarks, unit tests) and in live deployment (A/B tests, canary releases).
Behavioral testing and edge cases
Behavioral testing assigns explicit goals and evaluates whether the agent achieves them across diverse conditions. Example: for the goal “summarize the top three articles about climate policy,” a robust agent must (1) find relevant articles, (2) synthesize content accurately, and (3) format the summary according to spec.
Edge-case and robustness tests are essential:
- Simulate missing or malformed inputs.
- Inject API errors and timeouts.
- Test ambiguous or conflicting instructions.
- Check permission and access-control failures.

- Wrong tool selection for subtasks
- Incorrect memory reads/writes that violate context boundaries
- Incoherent or non-deterministic reasoning chains
- Tool orchestration: Was the correct tool called with the right arguments?
- Memory correctness: Were relevant memories retrieved and updated consistently?
- Plan coherence: Do intermediate reasoning steps align with the final output?
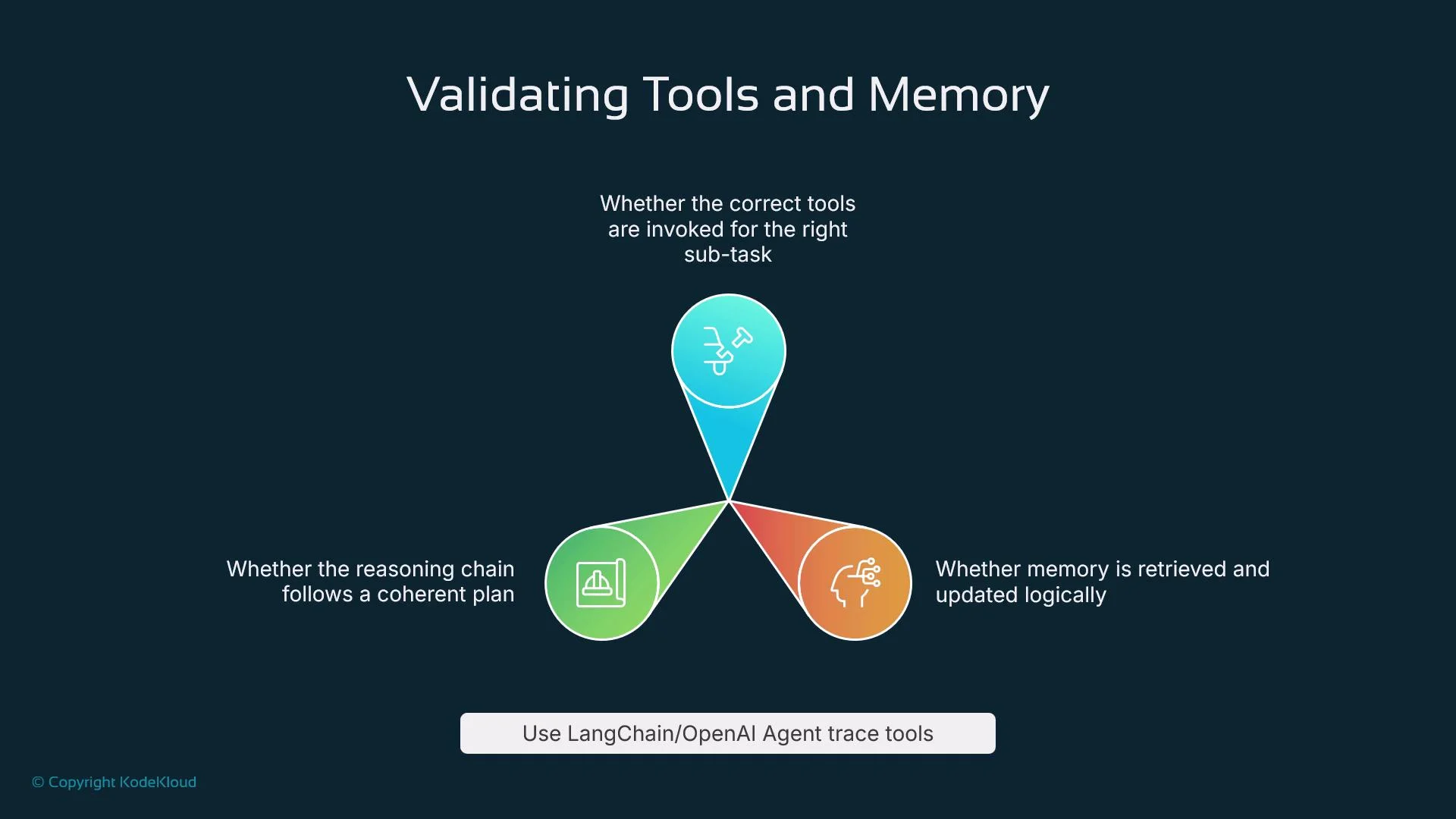
Be cautious with memory and tool integrations: improperly isolated memory or unchecked tool outputs can leak sensitive information across sessions. Include privacy and access-control tests in your pipeline.
- Guided rating workflows where human raters score outputs on clarity, relevance, and reliability.
- UX sessions that record confidence, perceived helpfulness, and qualitative comments.
- A/B testing of prompts, personalities, and response formats to measure user preference.

- Tokens consumed
- API/tool call count per request
- External service and compute costs per completion
- Wall-clock time per completion
- Route deterministic or trivial logic to rules-based code, not a model.
- Use tiered models:
GPT-3.5(or similar) for simpler steps, larger models for complex reasoning. - Cache frequent query results and tool outputs.
- Batch tool calls and memory accesses where safe.
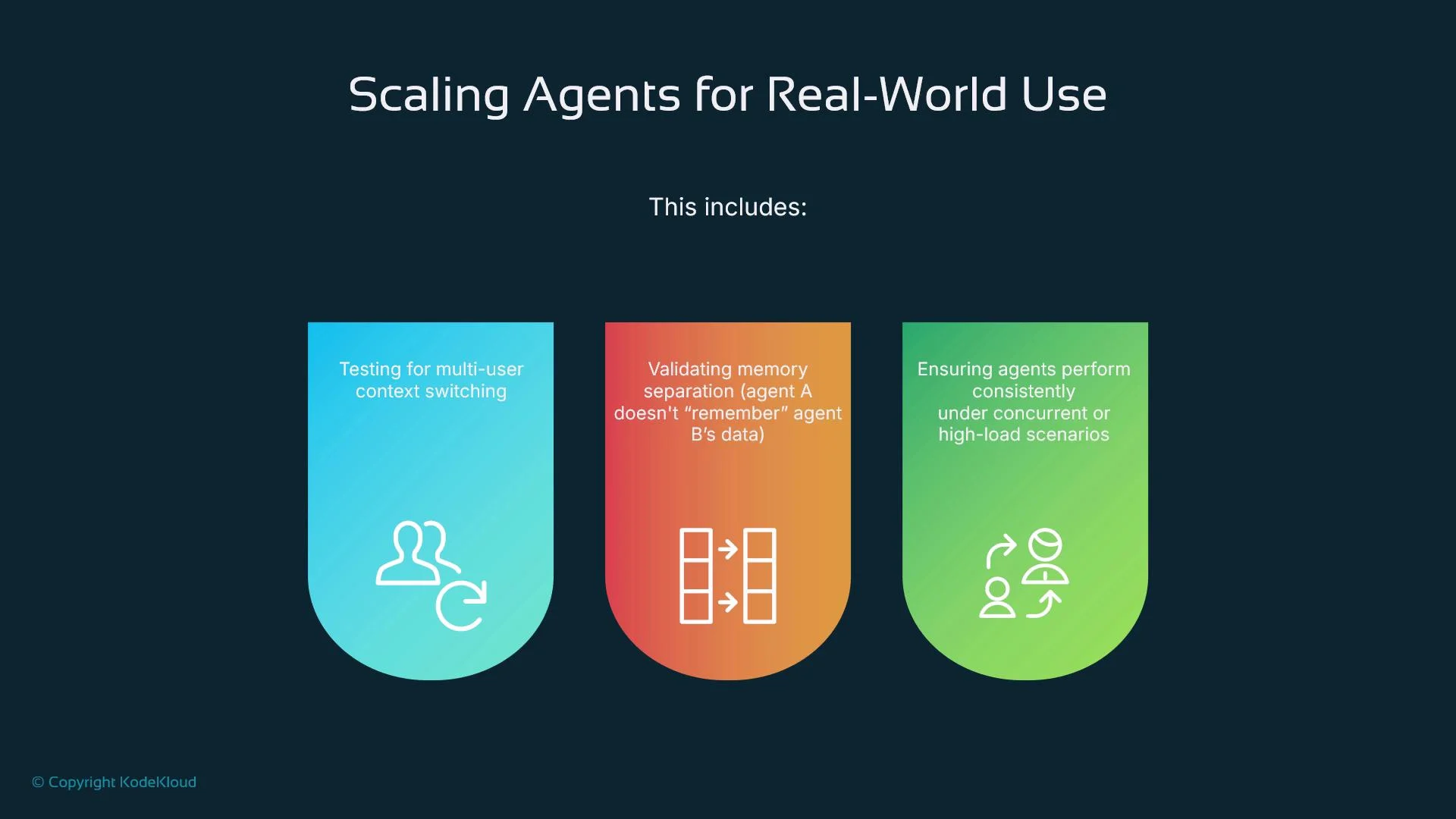
- Memory separation: ensure Agent A cannot access Agent B’s private data.
- Context switching: save and restore user contexts correctly under load.
- Throughput testing: validate performance with many parallel requests.
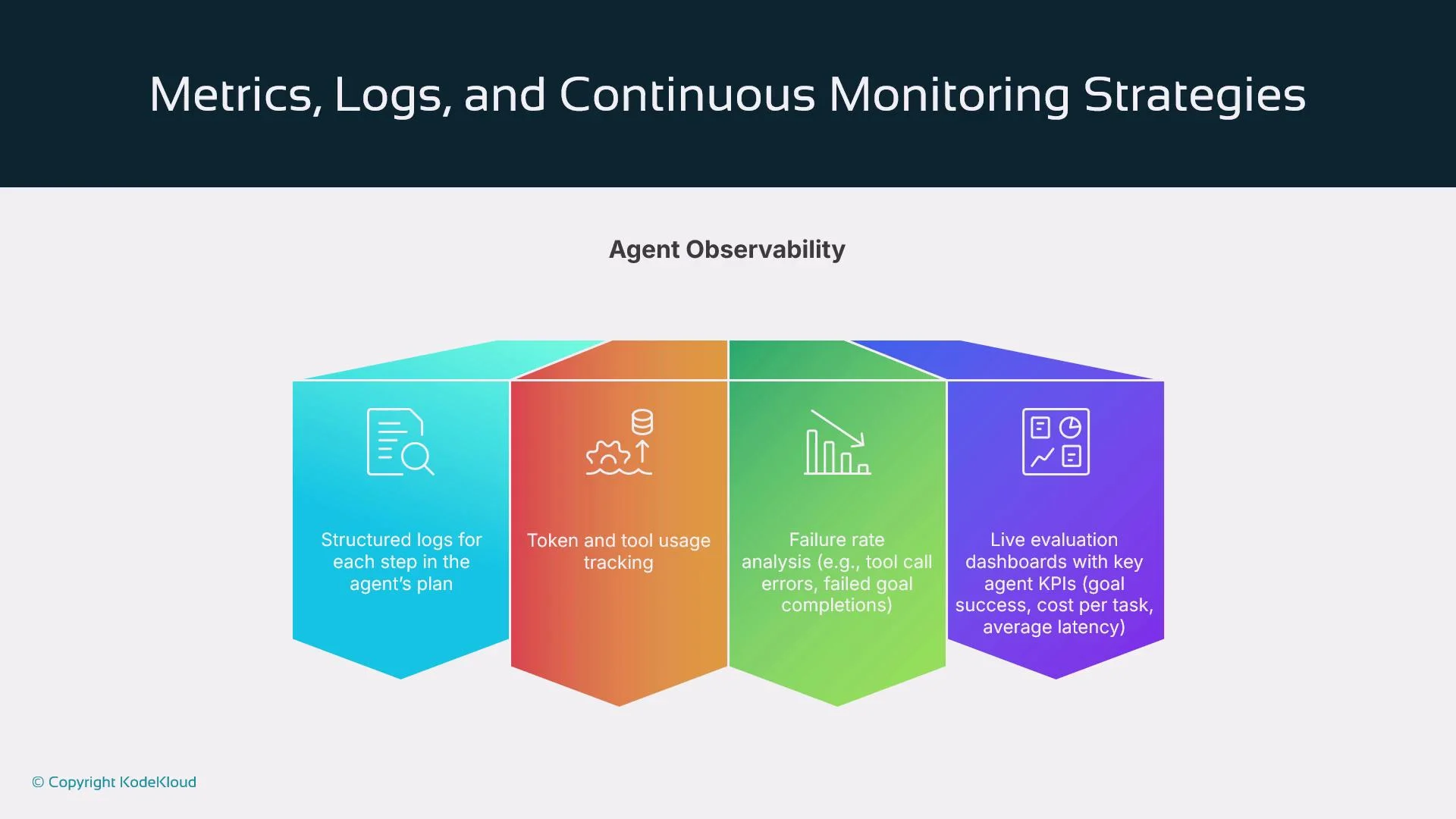
- Structured logs per planning and execution step
- Token, tool, and latency tracking per run
- Failure-rate and error-pattern analytics
- Dashboards with KPIs: goal success, cost per task, average latency
- Define test prompts or goals (e.g., “schedule a meeting and send a confirmation email”).
- Run the agent runtime, triggering planning, memory access, and tool usage.
- Log every step: planning decisions, tool calls and responses, memory reads/writes, and intermediate outputs.
- Score the run with automated checks (expected tool called, format matched) and/or human ratings (clarity, usefulness, accuracy).
- Feed results into an optimization loop: refine prompts, fix orchestration bugs, reconfigure tools, or retrain/fine-tune models.
- Evaluate agents multidimensionally — measure correctness, tool usage, reasoning quality, and user trust, not just raw accuracy.
- Use human-in-the-loop testing during early staging to reveal unclear responses and subtle biases.
- Tie evaluation to cost and UX outcomes — prioritize solutions that balance effectiveness and efficiency.
- Treat agents as dynamic ecosystems — implement continuous testing, observability, traceability, and drift detection.
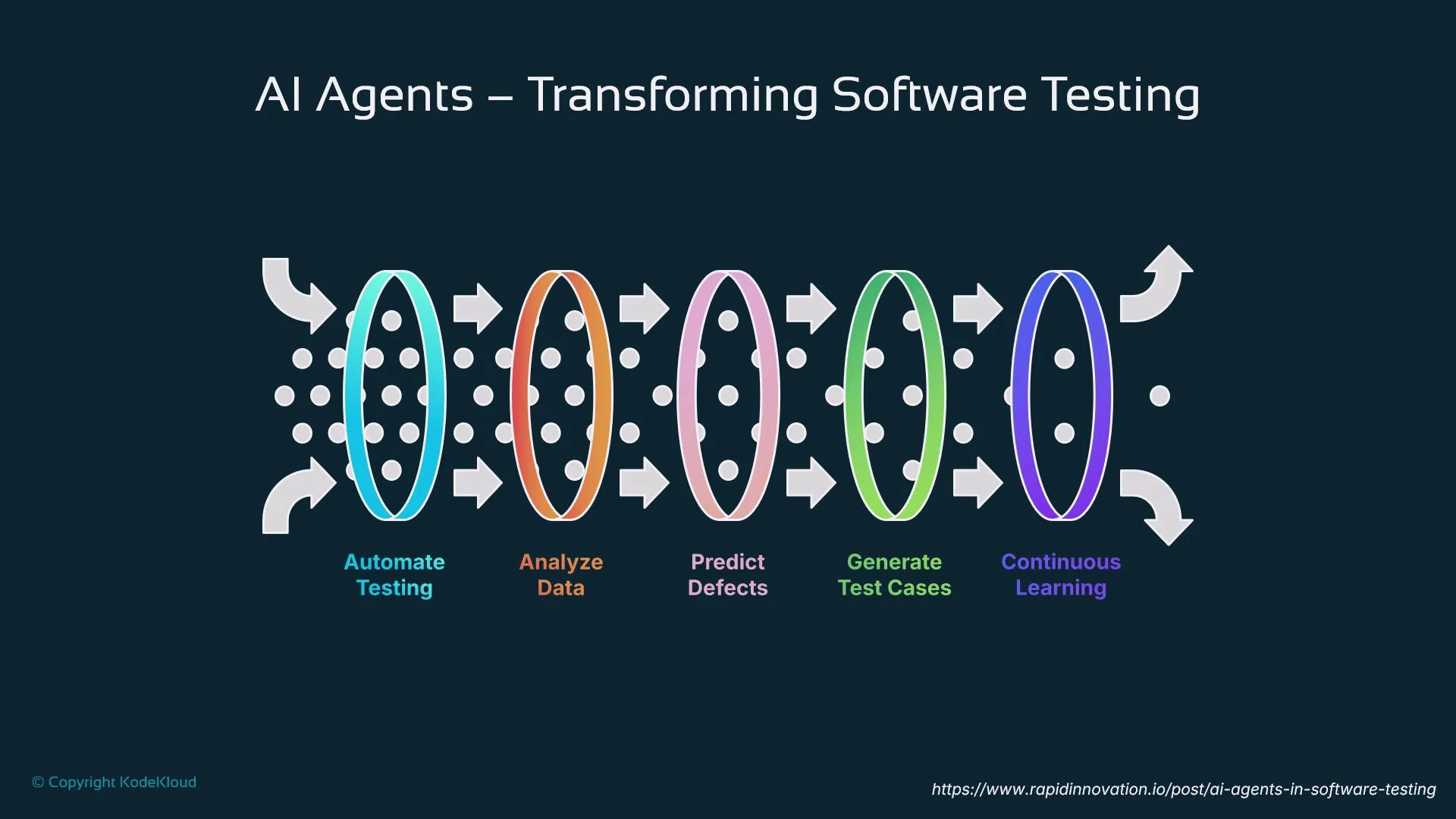
- Automate testing: agents run and manage test cases with less manual work.
- Analyze data: aggregate test outcomes to find patterns.
- Predict defects: prioritize high-risk components for testing.
- Generate test cases: create new tests from code changes or usage telemetry.
- Generate test cases from natural-language specifications.
- Detect bugs by analyzing logs, traces, and execution outputs.
- Integrate with test toolchains such as Playwright and Selenium, and with CI/CD.
- Produce structured bug reports with remediation suggestions.
- Learn from prior test runs to improve coverage and reduce false positives.

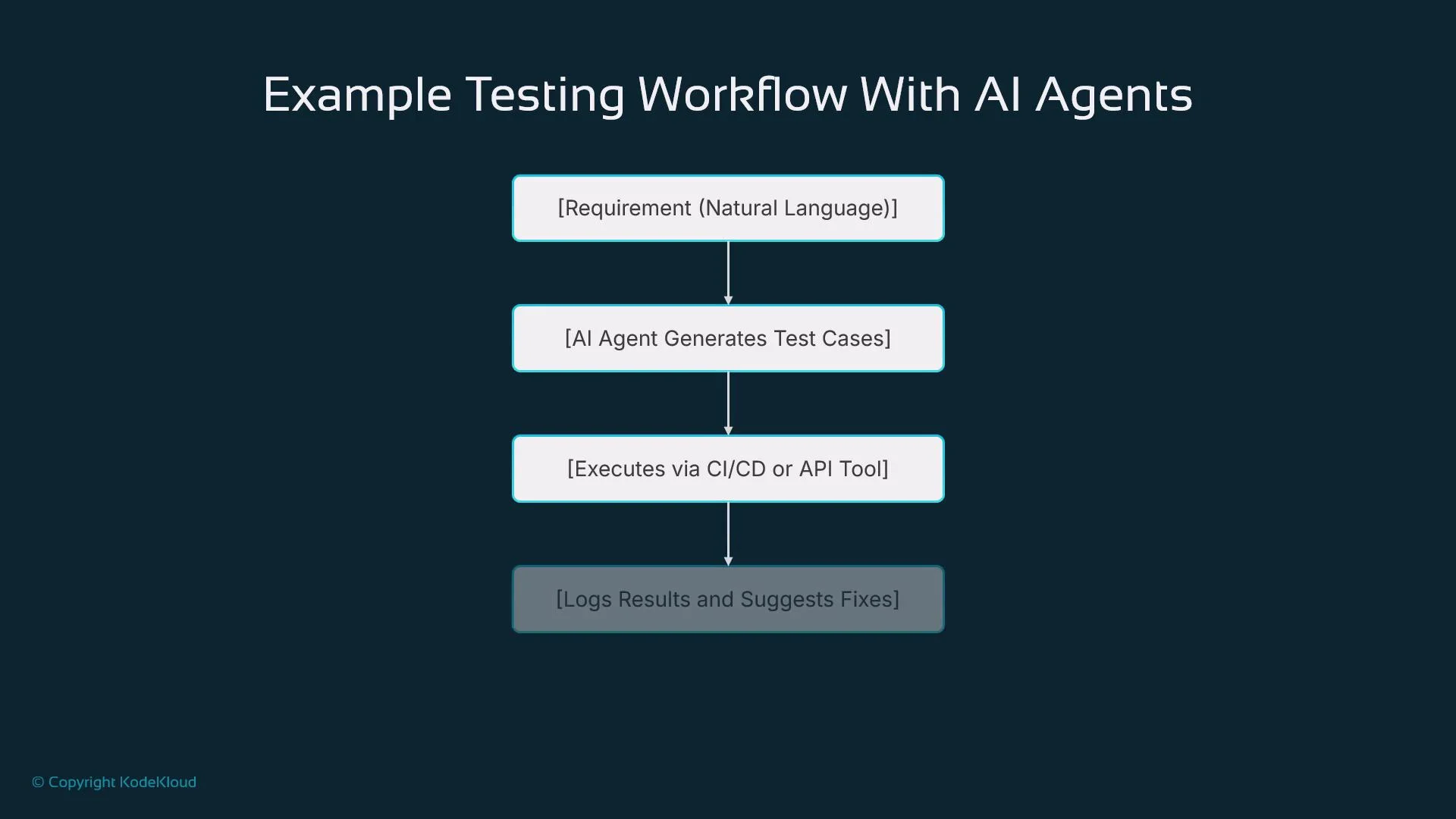
- Feed agents product requirements or user stories (structured or natural language).
- Agents generate test cases and execute them through the test toolchain.
- Outcomes are logged and analyzed; agents recommend fixes or test adjustments.
- Integrate into CI/CD (for example, GitHub Actions: https://docs.github.com/actions or Jenkins: https://www.jenkins.io/) so tests run on code changes.
- Agents adapt test cases over time using telemetry and observed outcomes.
- Regression testing at scale
- Exploratory testing to uncover edge-case bugs
- Visual/UI testing for layout and rendering regressions
- Generating human-readable reports and automated developer notifications
- Quality of output depends on input quality and precise requirement definitions.
- Complex business logic and nuanced edge cases often still require human oversight.
- Integrating agents with legacy monoliths can be difficult.
- Agents must be tuned to minimize false positives and negatives.
- Self-healing tests that adapt to code changes automatically.
- Automation of repetitive setup and verification tasks to speed cycles.
- Predictive analytics that forecast defect-prone areas.
- Natural-language-first testing to make test creation accessible to non-engineers.
- Continuous, real-time validation for faster feedback loops.
- Increased test coverage through adaptive exploration and prioritization.
- AI-driven optimization to refine test effectiveness continuously.