1. What Is Apache Kafka?
Apache Kafka is a distributed event streaming platform built for high-throughput, low-latency data pipelines and real-time streaming applications. It functions as a persistent, fault-tolerant store of ordered event logs, enabling you to:- Ingest data from websites, IoT sensors, microservices, and mobile apps
- Process and transform streams of events in real time
- Distribute data to various downstream systems for analytics, storage, or further processing
Kafka’s distributed commit log ensures ordered event storage. You can replay messages anytime, making it ideal for auditing, reprocessing, and stateful stream processing.
2. Kafka in the Data Ecosystem
Kafka sits at the heart of your data ecosystem, decoupling producers (data sources) from consumers (data sinks). This separation allows each component to scale independently and reduces system coupling.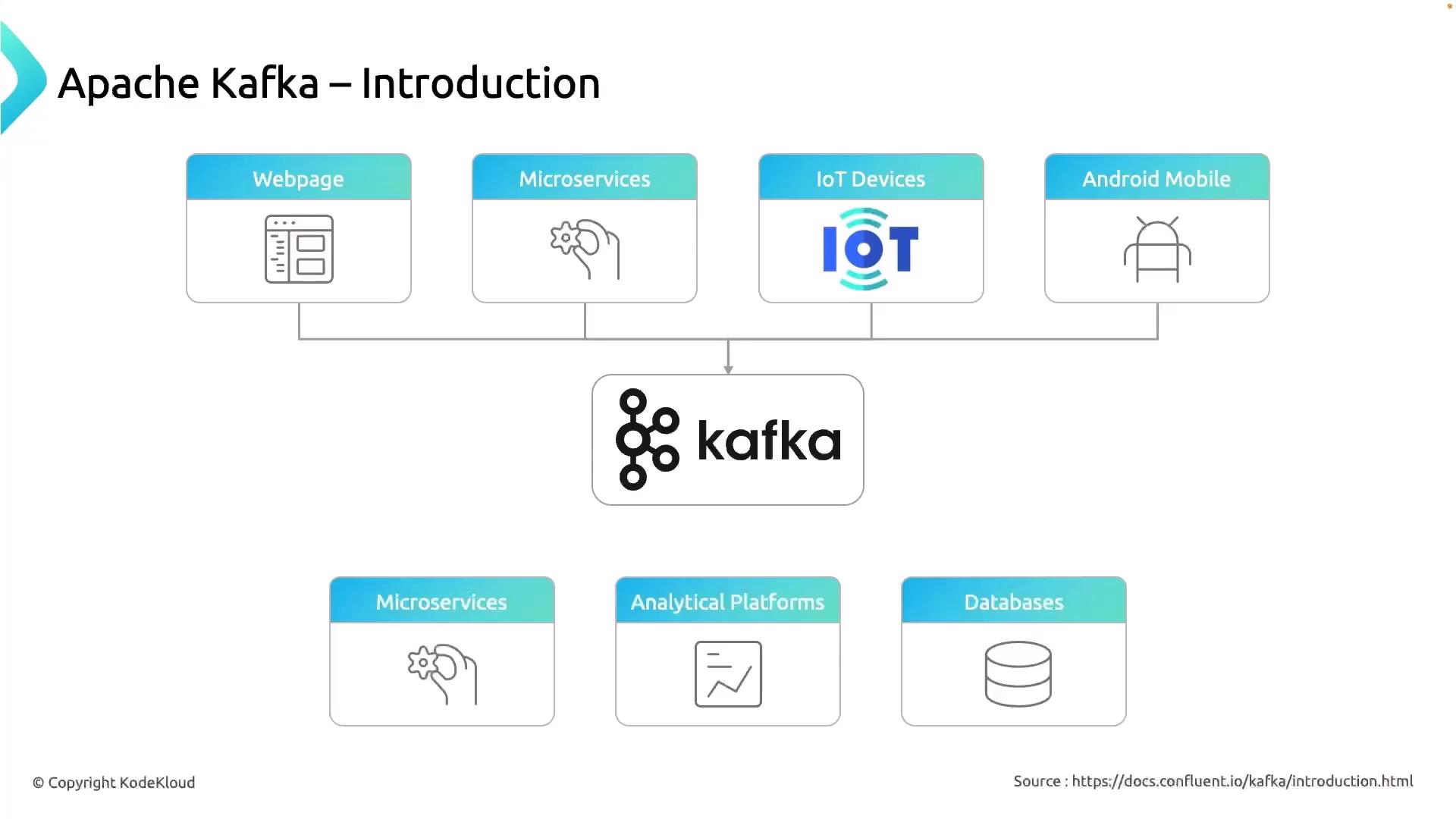
| Component | Examples |
|---|---|
| Producers | Web servers, IoT sensors, mobile apps |
| Topics | user-signups, sensor-readings, logs |
| Consumers | Real-time dashboards, data warehouses, ML |
3. Kafka as a Central Hub
By centralizing event storage and distribution, Kafka acts like a “data superhighway” for your organization. All incoming event traffic is:- Published to topics, partitioned for parallelism
- Replicated across brokers to guarantee durability
- Consumed by services, analytics engines, or databases
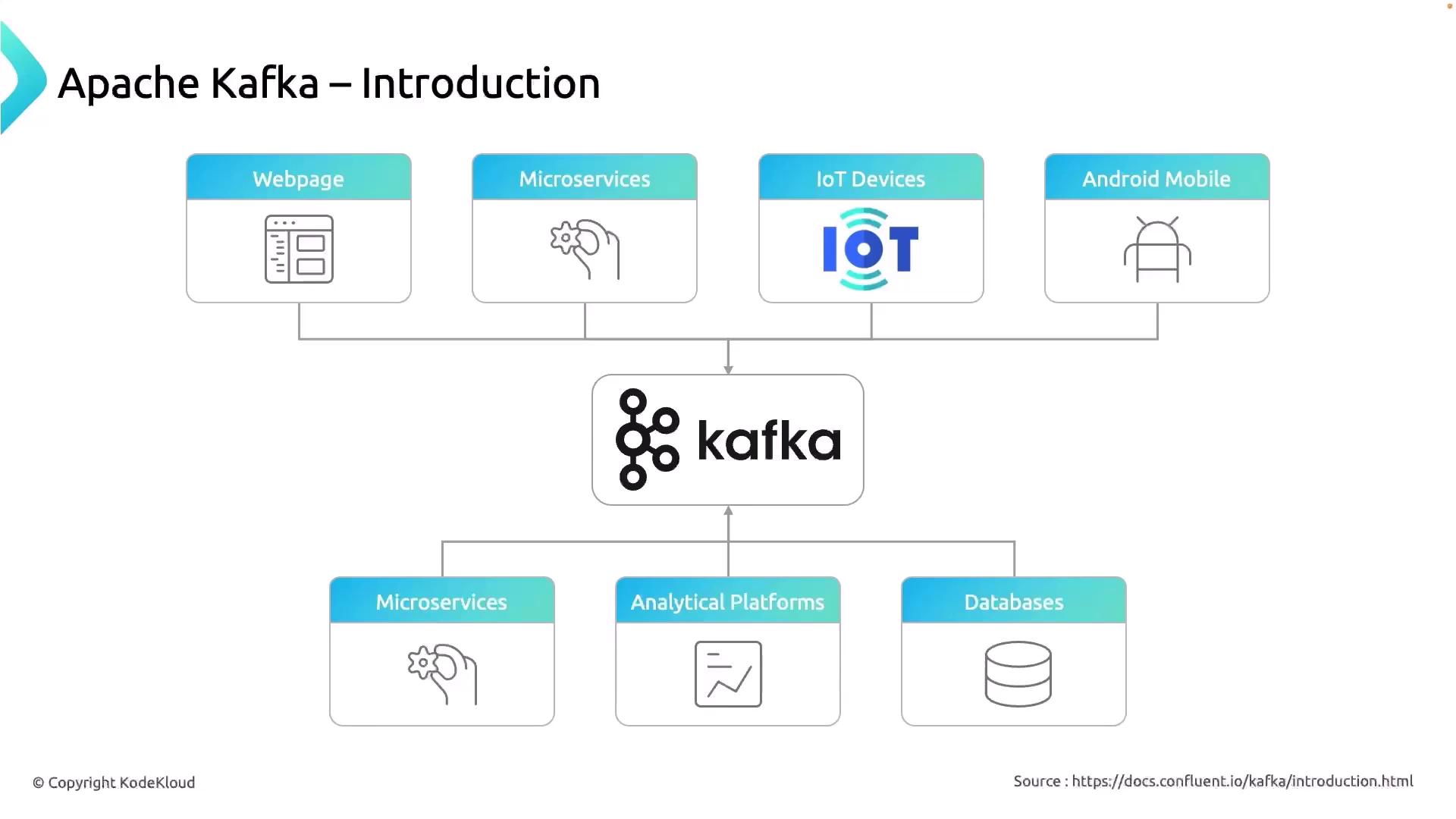
| Feature | Benefit |
|---|---|
| Horizontal Scaling | Add brokers without downtime |
| Durability | Data replicated across multiple nodes |
| Fault Tolerance | Automatic leader election and failover |
| Replayability | Consumers can reprocess from any offset |
Kafka is optimized for high-throughput workloads. For very small-scale messaging, consider lightweight alternatives like RabbitMQ or cloud-native pub/sub services.
Next Steps
- Dive into Kafka Core Concepts for brokers, topics, and partitions
- Explore real-time processing with Apache Kafka Streams
- Learn about deploying Kafka on Kubernetes with Strimzi