Prerequisites
- A running Kafka broker and Connect cluster on your EC2 instance
- AWS credentials configured for the S3 sink connector
- An S3 bucket created for storing topic data (e.g.,
my-kafka-bucket)
1. Start the Kafka Console Producer
- SSH into the EC2 instance and elevate to root:
- Navigate to your Kafka installation:
- Launch the console producer for the
carteventtopic:
2. Publish Sample Car Events
Copy and paste each line below into the producer terminal. Each JSON message represents a single car event:By default, the S3 sink connector flushes records every 5 messages or after a time interval. After sending at least five events, you can immediately verify data landing in S3.
3. Verify JSON Files in Amazon S3
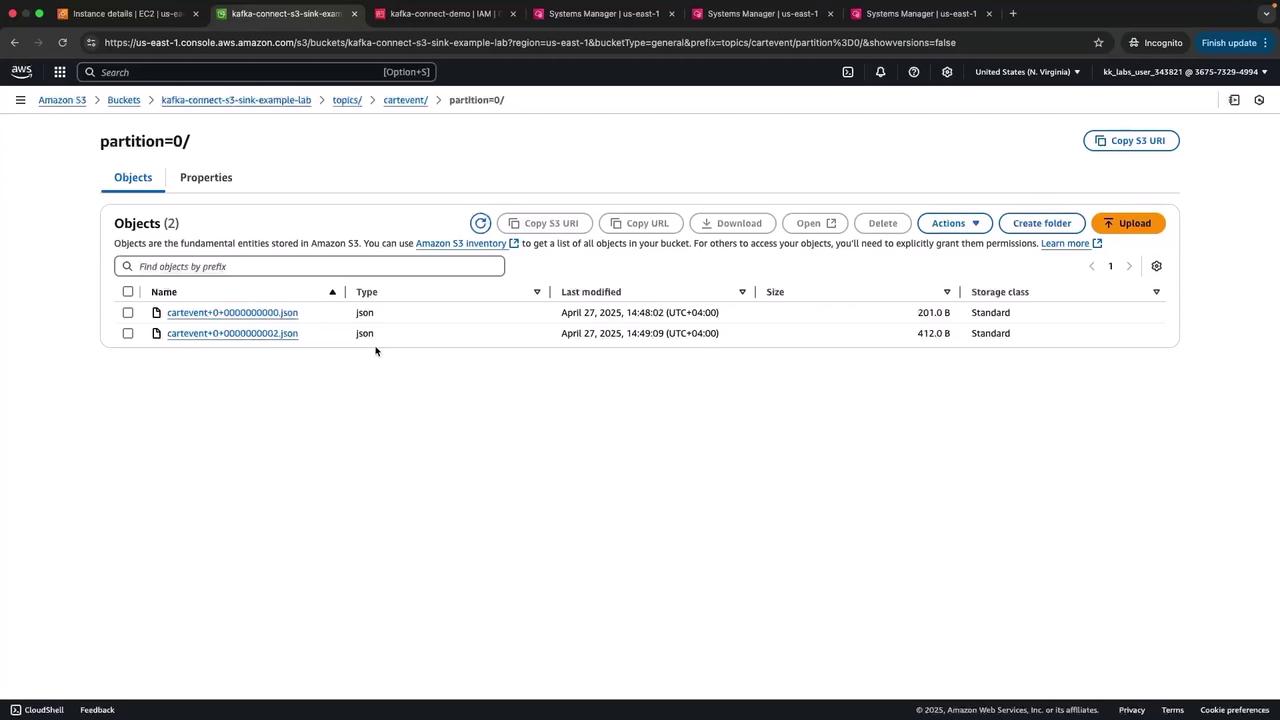
Navigate to the S3 console and open the prefixtopics/cartevent/partition=0/ in your bucket. You should see JSON files named using the convention topic+partition+startOffset.json.

4. How It Works
- The Kafka Connect S3 sink connector continuously polls the
carteventtopic. - Upon reaching the configured batch size or interval, it writes a bulk JSON file to S3.
- Connector handles offset management, retries, and error handling automatically.
- You can query these files directly with Amazon Athena or integrate with downstream analytics tools.
Supported Kafka Connectors
| Connector Type | Examples | Use Case |
|---|---|---|
| Sink | Amazon S3, Google Cloud Storage, RDS | Persist Kafka data to external stores |
| Source | FileSource, JDBC Source, S3 Source | Ingest external data into Kafka |
That wraps up this demo of the Kafka Connect S3 sink. Next, explore additional connectors and integration patterns to build scalable event-driven architectures!