- Clone the n8n self-hosted AI starter kit repository.
- Copy and edit the
.envfile to configure secrets and host settings. - Start the stack with Docker Compose using the profile appropriate for your hardware.
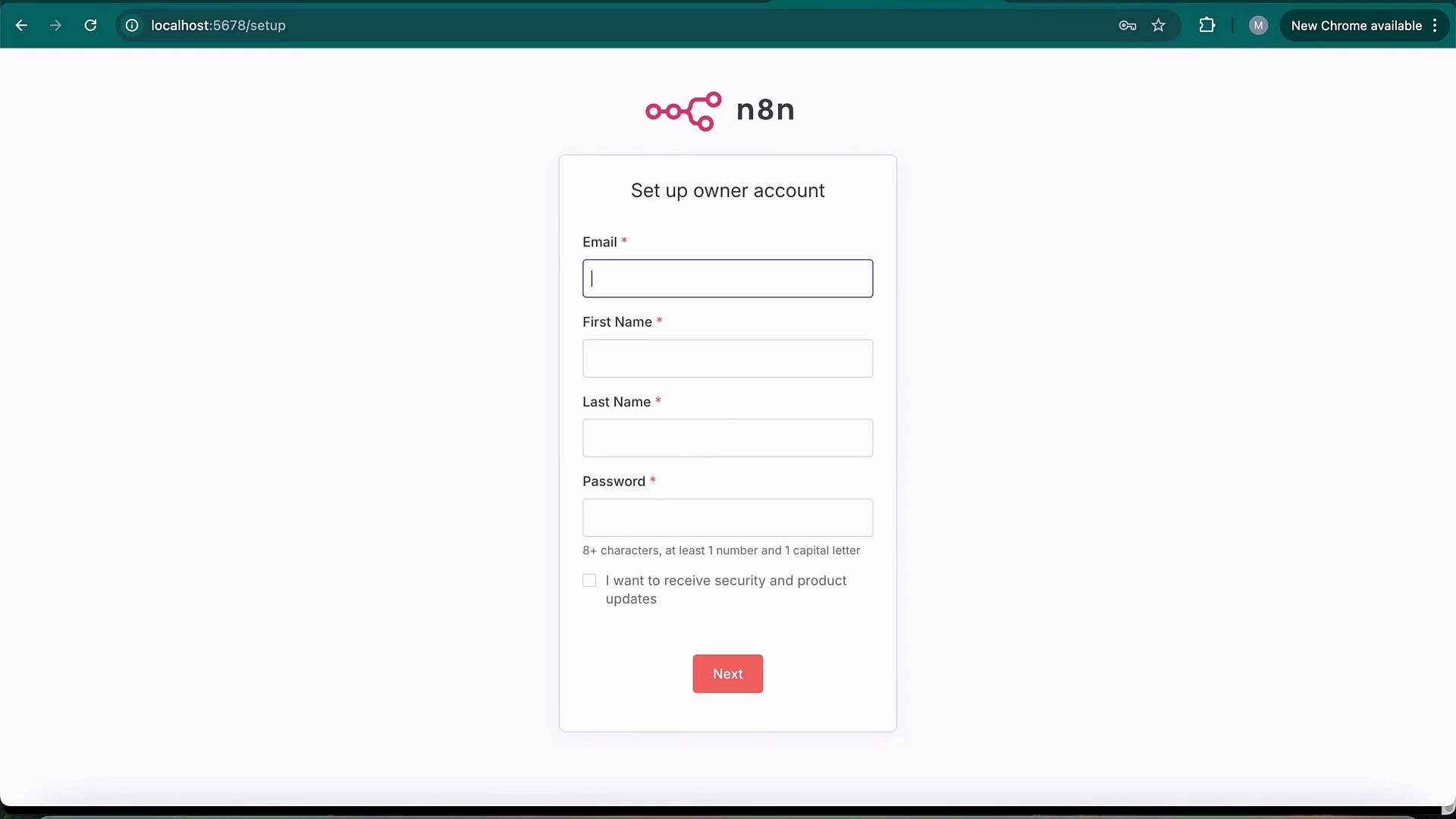
- Open n8n at http://localhost:5678 and create an owner account.
- Inspect and run the demo workflow that uses a local Ollama model.
.env
Open
.env and update secrets (database credentials, encryption keys, JWT secrets, etc.) before starting the stack. If you plan to use a separately installed Ollama instance, set OLLAMA_HOST (for example: http://localhost:11434).
Example:
Example terminal output (truncated)
- Go to: http://localhost:5678
- On first visit you will be prompted to create an owner account (email, name, password). Any local email works for this self-hosted setup.
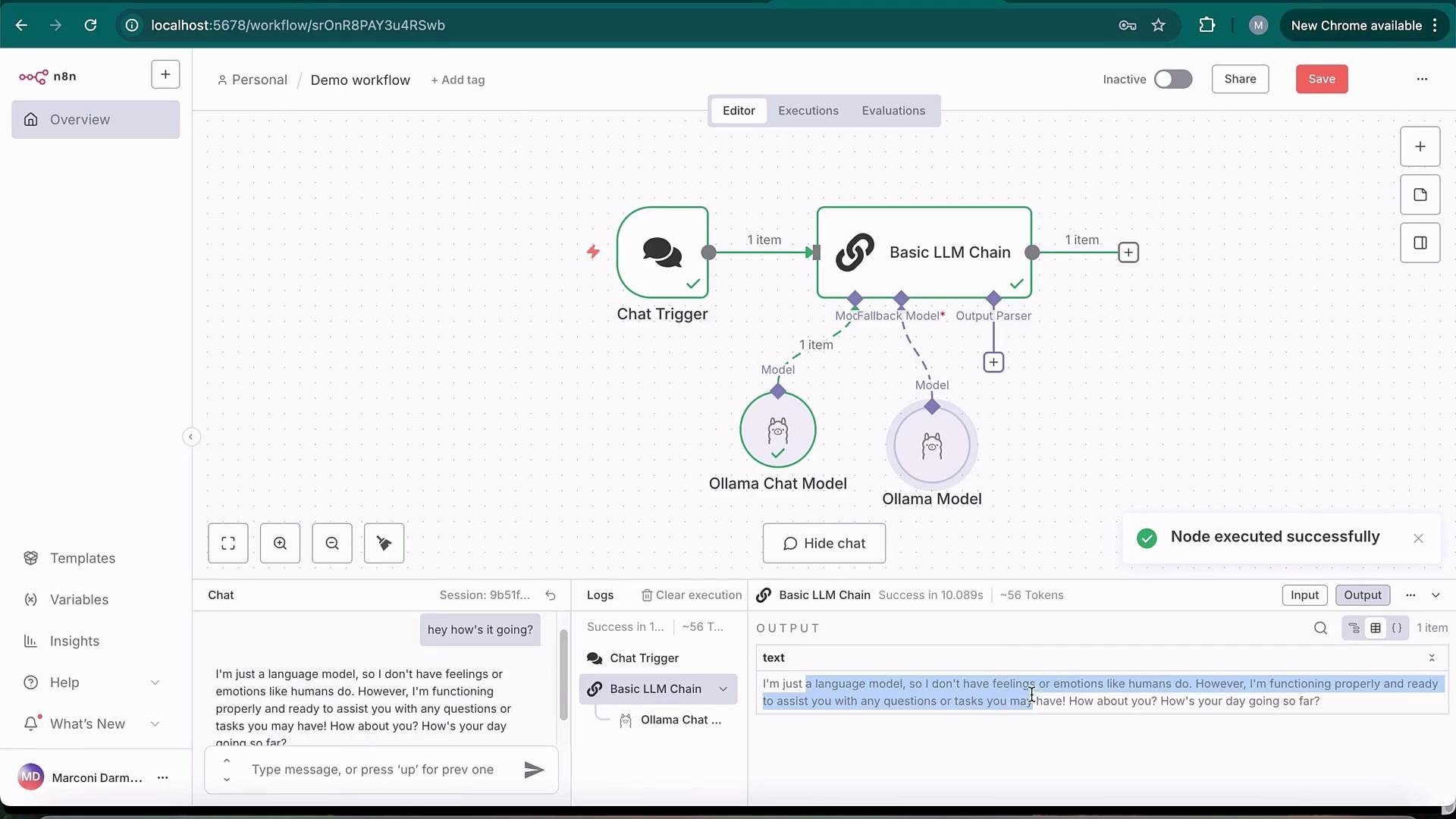
- The starter kit automatically imports a demo workflow when n8n starts.
- Open the demo workflow in the editor: it demonstrates a simple LLM chain using an Ollama chat model.
- Create an Ollama credential in n8n and point it to your Ollama host. When using the compose stack, the default is
ollama:11434(Docker-internal hostname mapped tolocalhost:11434on the host machine). - Send a sample prompt (for example, “Hey, how’s it going?”) to test the node. Responses should come from the local Ollama instance running in the compose stack.
- Use Docker Desktop to view containers, images, networks, and volumes created by the starter kit.
- Stopping the compose stack (or containers) will disconnect n8n from Ollama and other services because they run in the same compose network.
- Volumes hold Postgres and Ollama state; manage them via Docker Desktop if you need to clear or backup data.

.env values as appropriate.
Do not commit your
.env file to source control. The file contains sensitive values (database passwords, encryption keys, JWT secrets). Use secure storage or environment-specific secrets for production deployments.- n8n self-hosted AI starter kit: https://github.com/n8n-io/self-hosted-ai-starter-kit
- Ollama docs: https://ollama.ai/docs
- Docker Desktop: https://www.docker.com/products/docker-desktop
- Docker documentation and Compose reference: https://docs.docker.com/
- Docker training (beginner): https://learn.kodekloud.com/user/courses/docker-training-course-for-the-absolute-beginner
- This starter kit runs n8n, Ollama, Postgres, and Qdrant locally using Docker Desktop, enabling full local development and testing of AI-driven workflows.
- For production-grade deployments, evaluate network security, backups for volumes, and using managed database or vector stores as needed.