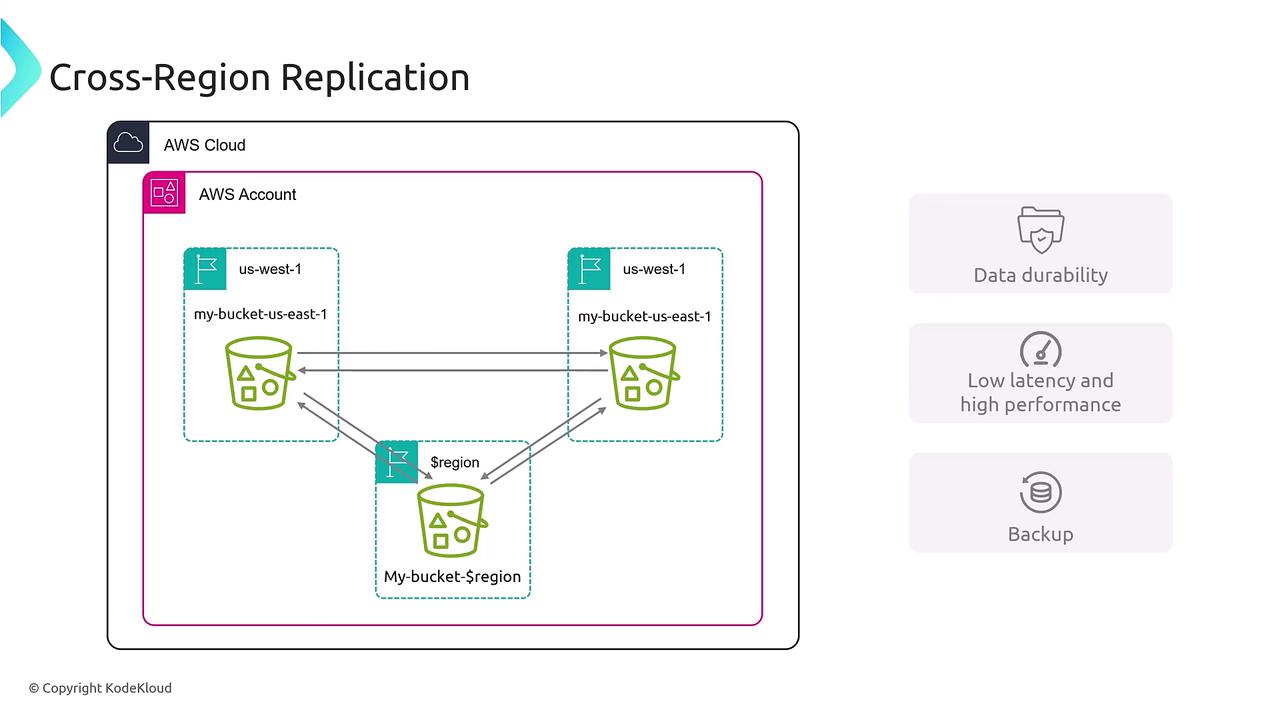
- Enhanced data durability
- Reduced latency for users near the replicated data
- A robust backup mechanism during regional failures
-
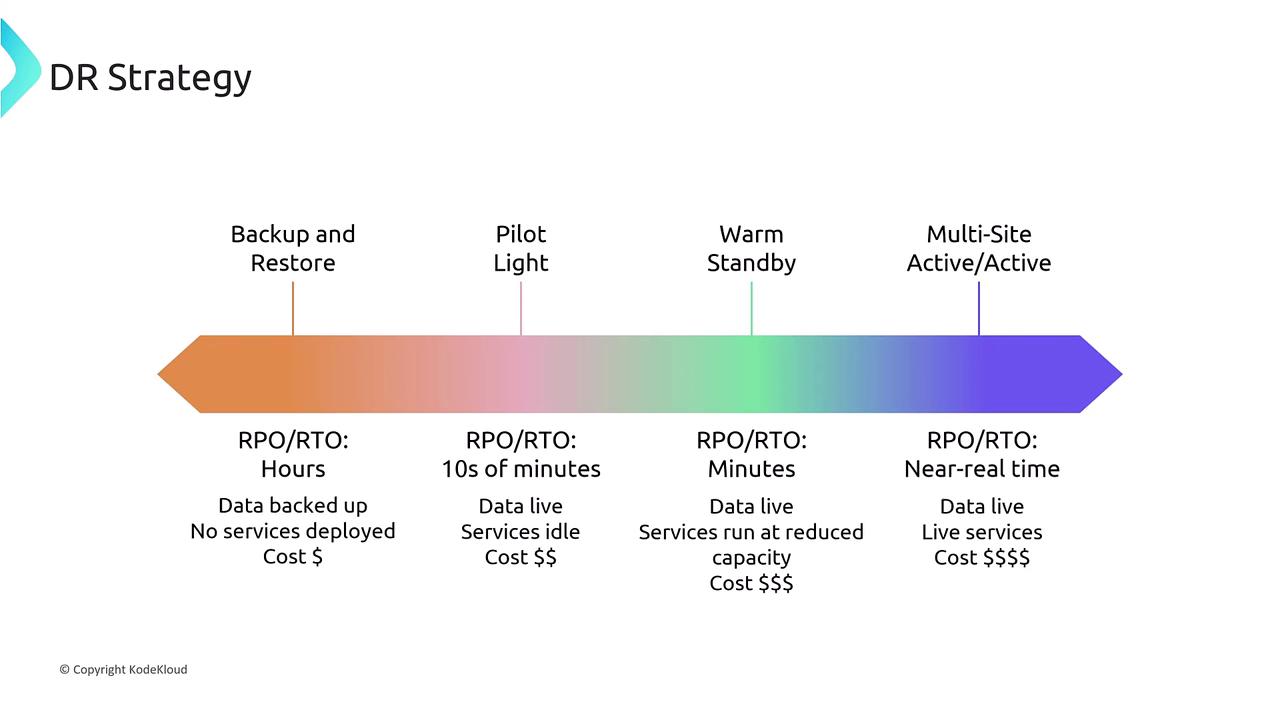
Backup and Restore:
Data is backed up at scheduled intervals. Although there might be a potential loss of a few hours’ data and a longer recovery time, this cost-effective method is ideal for non-critical systems. -
Pilot Light:
In this approach, a minimally active (or “pilot”) version of your environment is continuously running. Most services remain inactive until a disaster occurs, reducing recovery time to approximately 10–30 minutes with minimal data loss. -
Warm Standby:
Both applications and data are partially live, which allows for quicker recovery (typically under 10 minutes) compared to the pilot light approach. However, the costs are slightly higher as more resources are maintained in an active state. -
Active-Active:
This is the most robust DR strategy, offering near real-time recovery by running two fully active sites concurrently. In an active-active setup, if one site experiences an outage, the other immediately takes over, ensuring continuous service delivery.
Regularly test and update your disaster recovery plan to ensure your organization is prepared for any unexpected event.
| AWS Service | CRR Capability | Use Case |
|---|---|---|
| Amazon S3 | Cross-region replication of S3 buckets | Data durability, low latency access, and backup |
| DynamoDB Global Tables | Asynchronous replication with eventual consistency | Global distributed database management |
| Amazon RDS | Cross-region read replicas | Database failover and disaster recovery |
| Aurora | Cluster replication or global databases | High availability with near real-time replication |
| AWS Secrets Manager | Multi-region replication | Secure, cross-region secret management |
| Systems Manager Parameter Store | Cross-region replication | Centralized configuration management |
| Elastic File System (EFS) | Replication across regions | Shared data management across regions |