What is Chaos Engineering?
Traditionally, teams measure and fix systems after incidents occur. Chaos Engineering flips that process: it treats failures as hypotheses to test. Instead of hoping systems will behave under stress, you run controlled experiments—often in production-like environments—to discover weaknesses before customers notice. Large organizations (for example, Netflix and Amazon) use chaos experiments to gain confidence that systems will recover automatically during real outages.
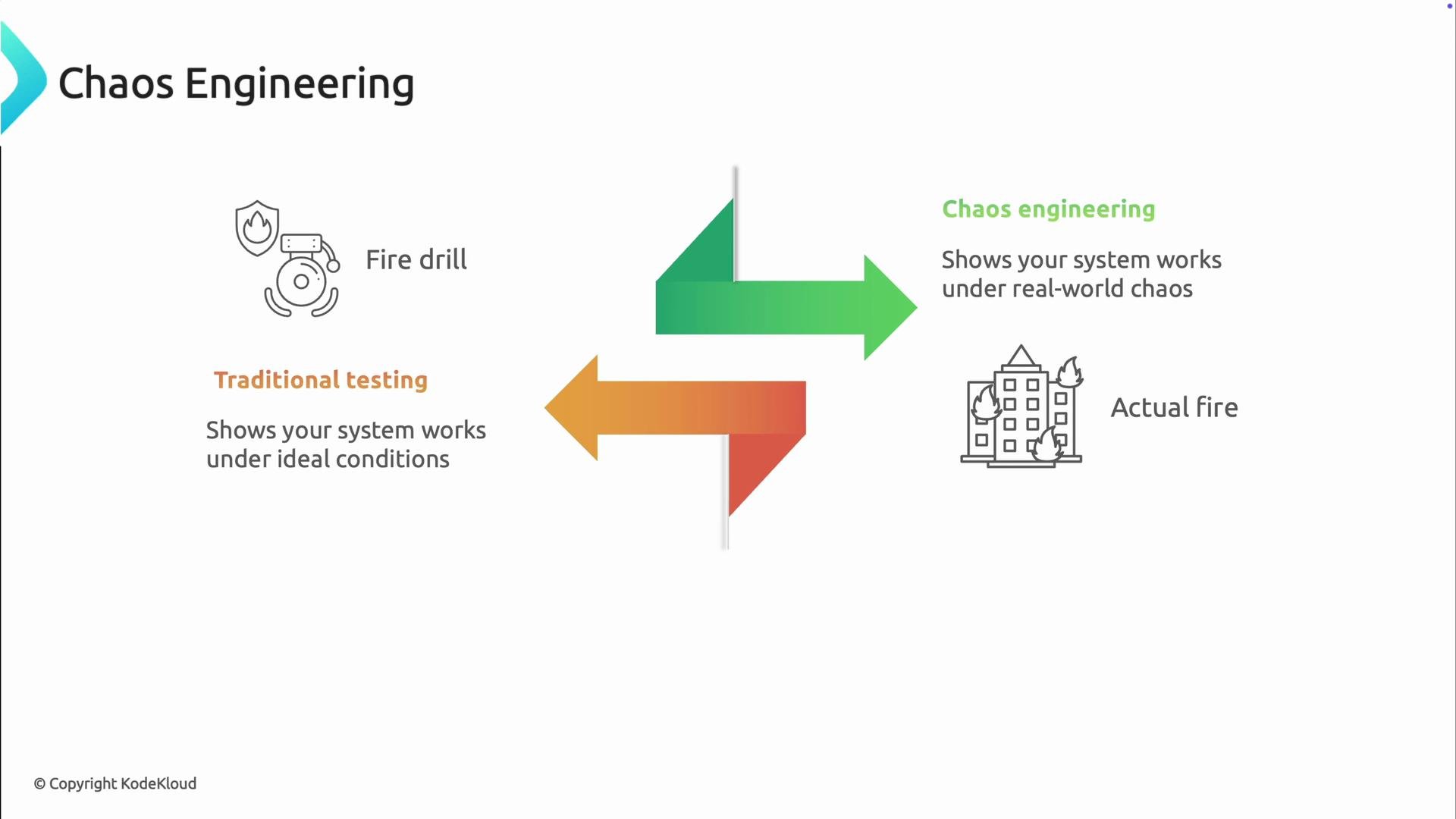
Resilient testing vs. Chaos Engineering
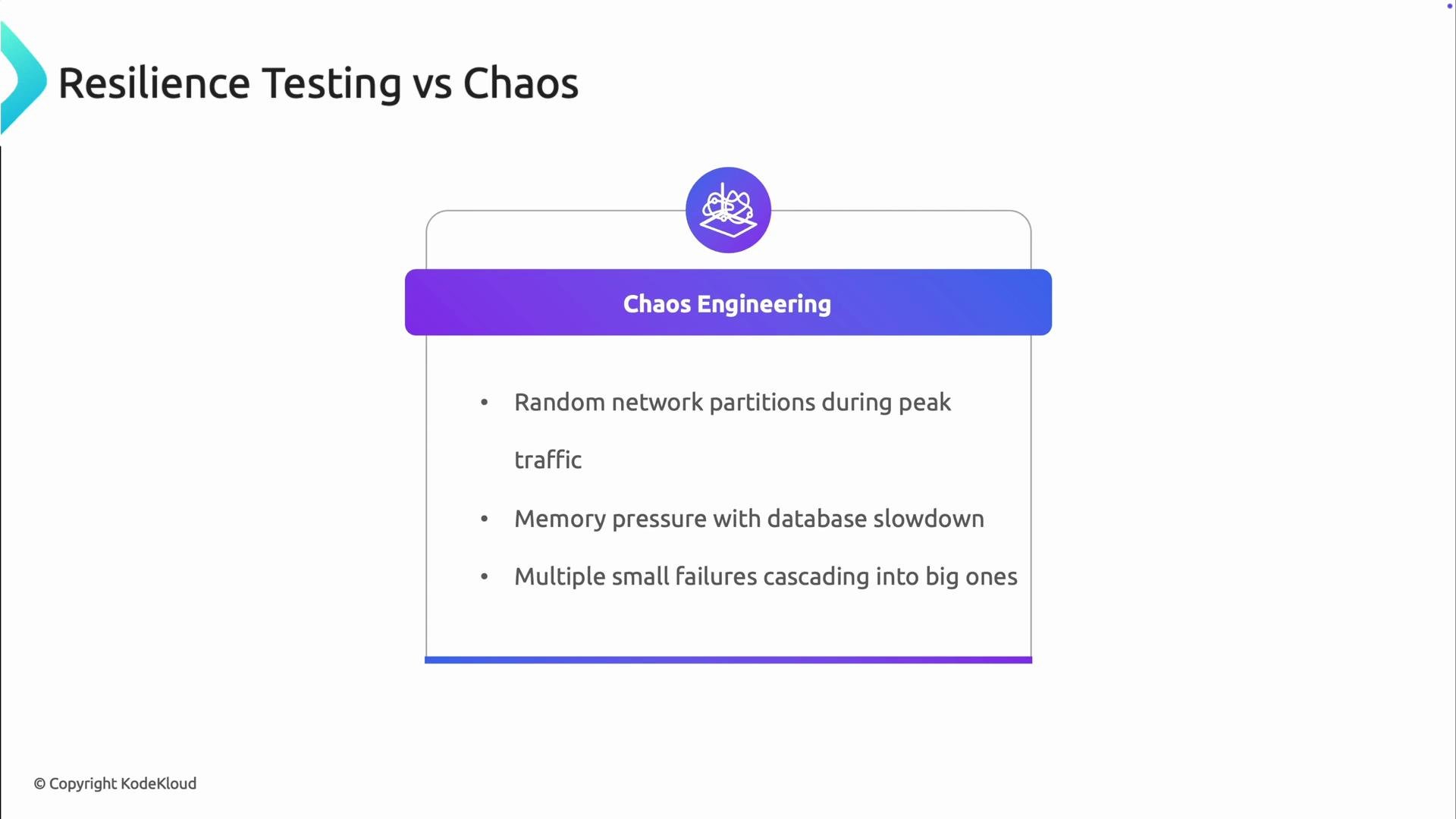
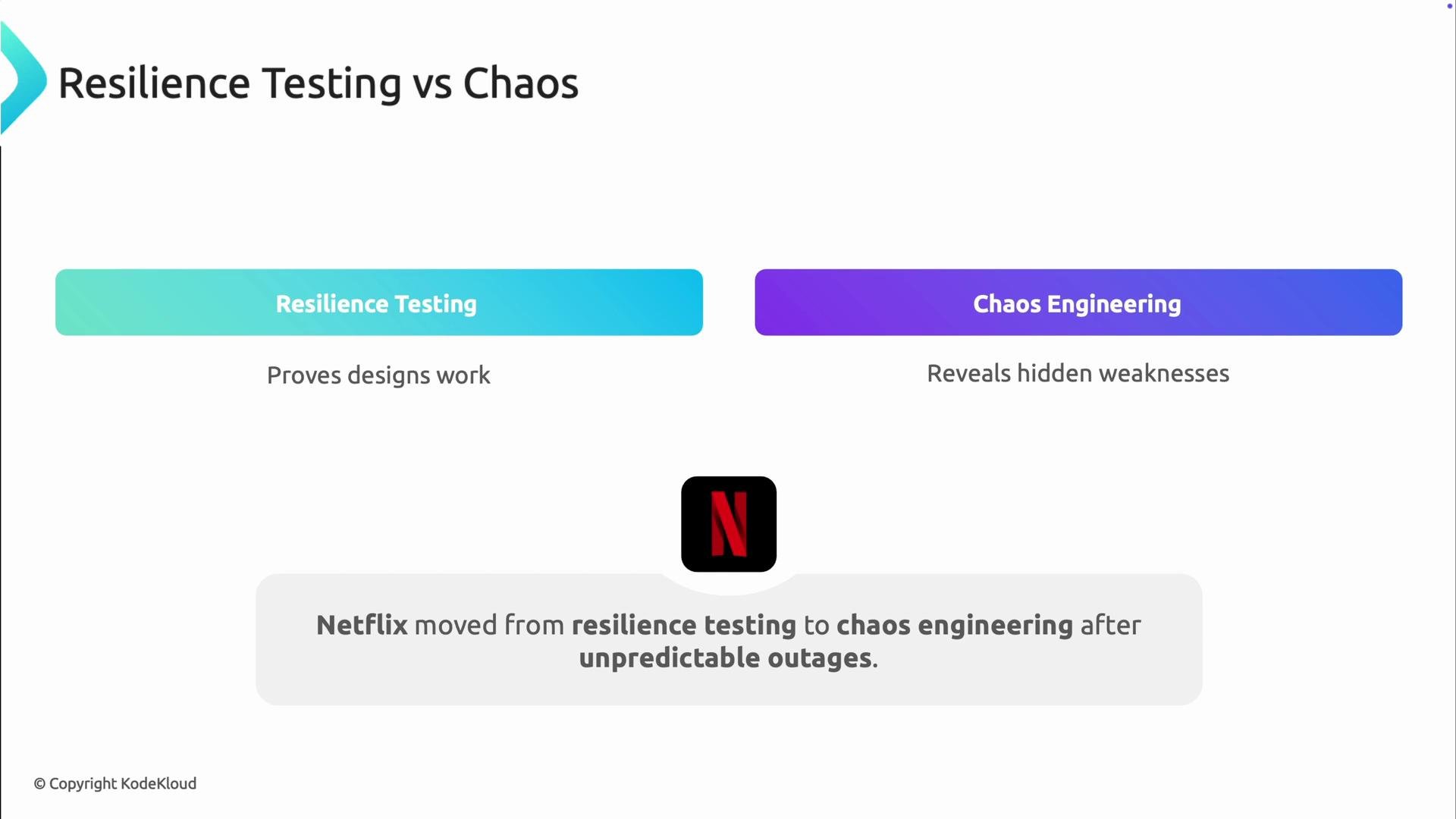
Resilient testing and chaos engineering complement each other. Use resilient testing to verify expected behaviors, and use chaos engineering to discover unknown failure modes.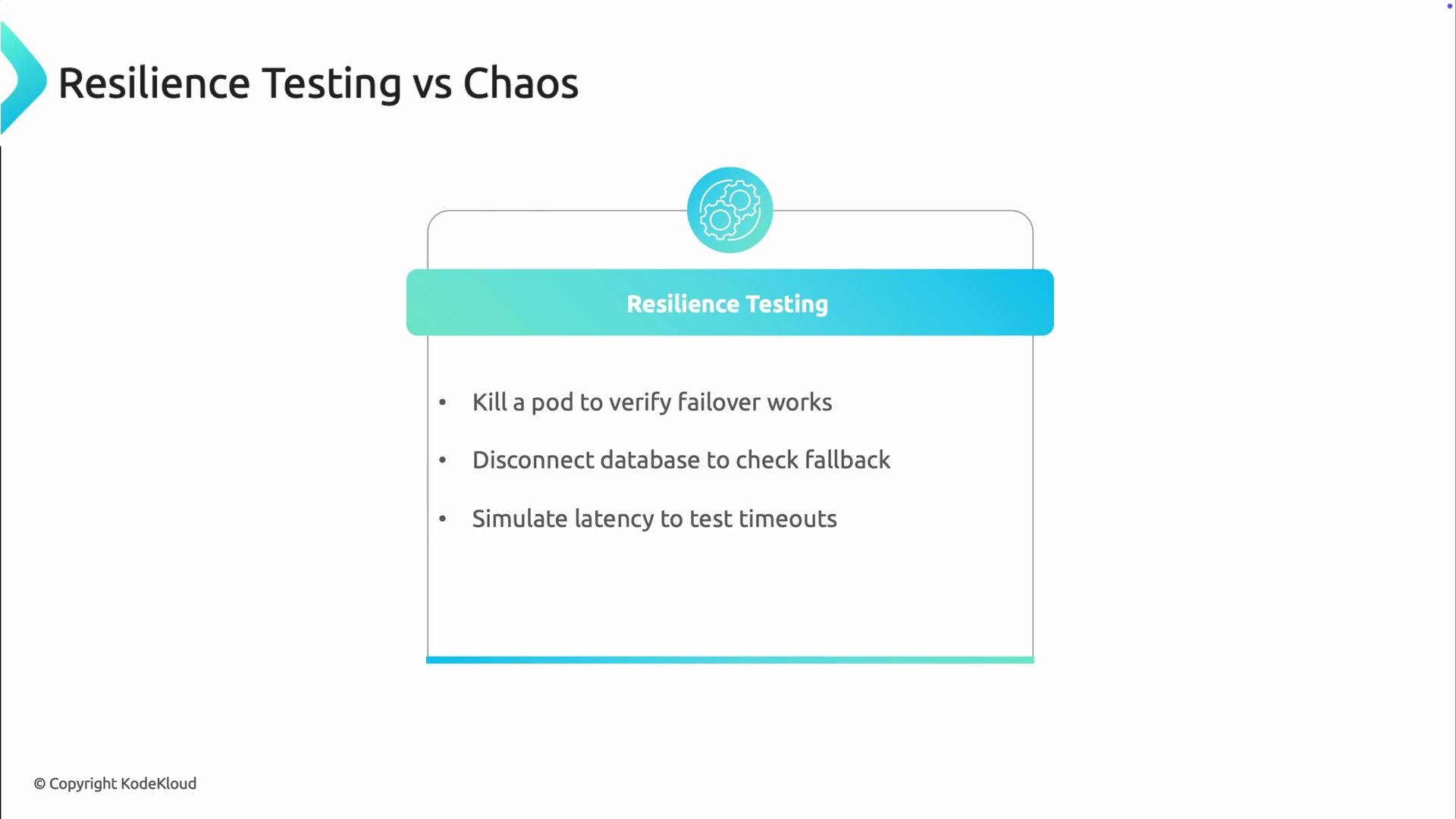
- Resilient testing = verification: confirm designed behaviors under known conditions.
- Chaos Engineering = discovery: introduce unexpected or compound failures to learn about previously unseen modes.
How to run chaos experiments safely
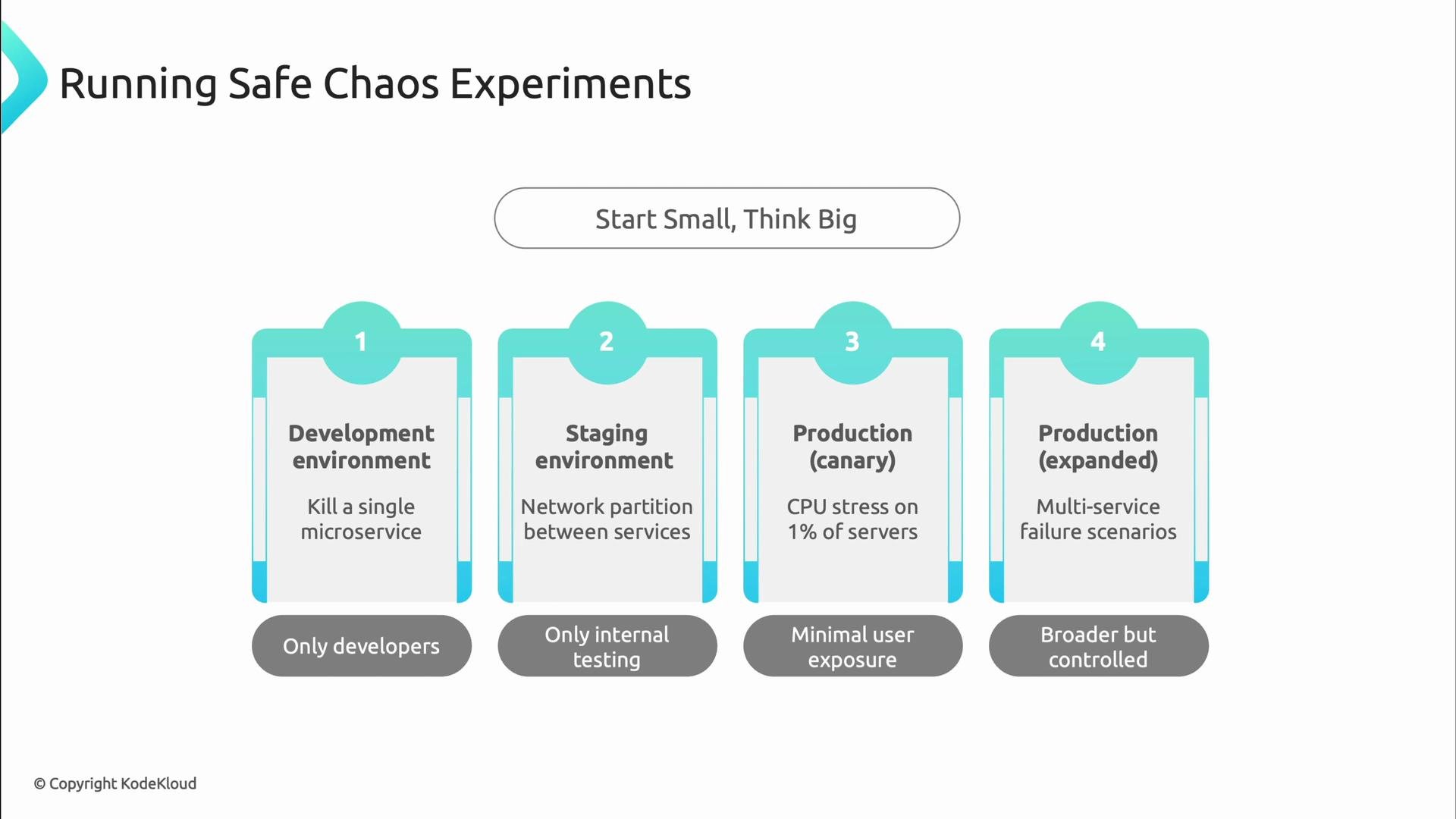
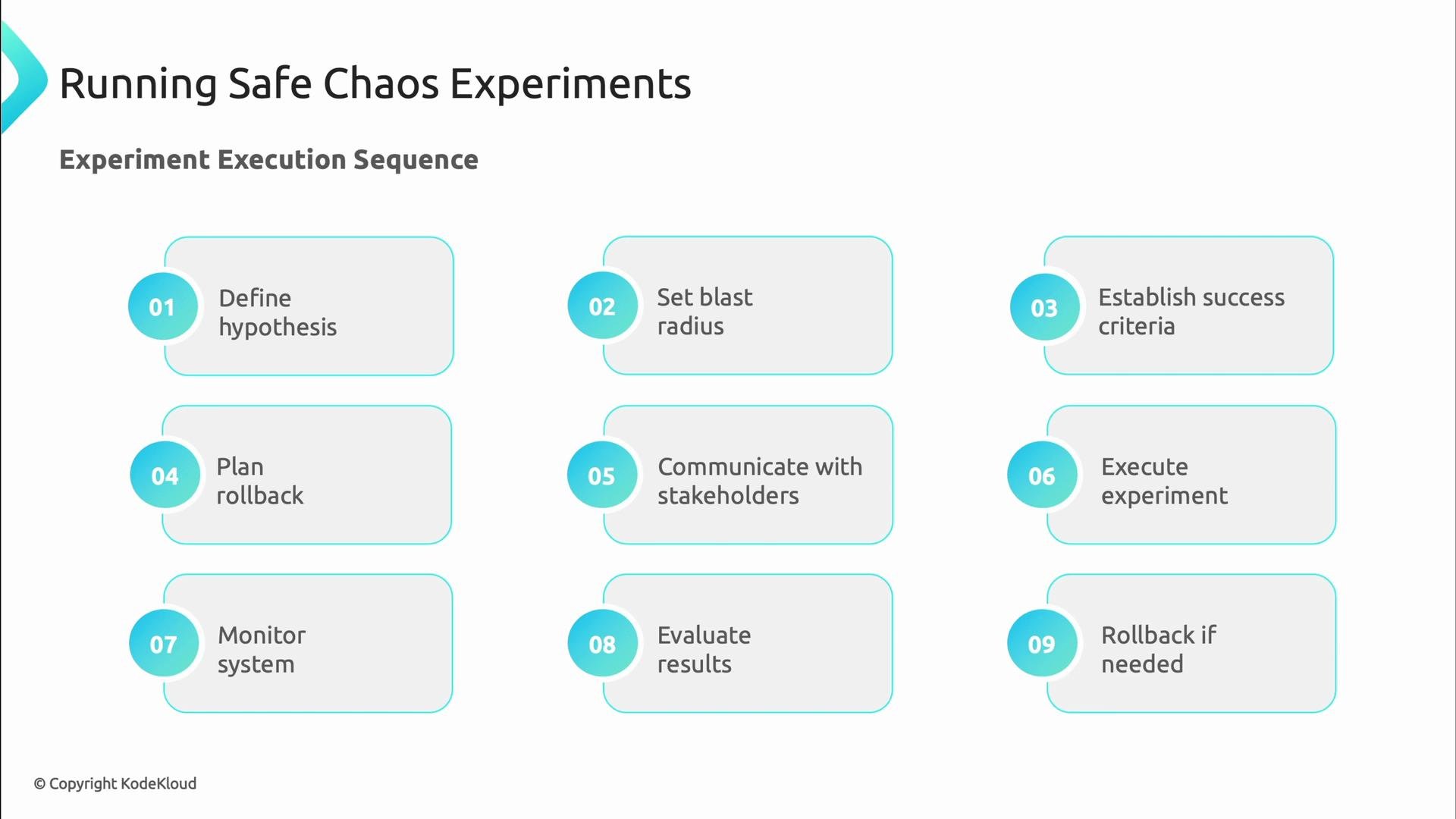
A safe rollout follows a gradual progression from low-risk environments to production canaries:
Start small, limit risk, and expand only after observing expected behavior.
- Define a hypothesis (what you expect to happen).
- Set the blast radius (who or what is affected).
- Establish success criteria and metrics.
- Plan rollback and communication paths.
- Execute the experiment.
- Monitor real-time metrics and alerts.
- Evaluate results and iterate.
Guardrails — keep experiments controlled
Common safety measures: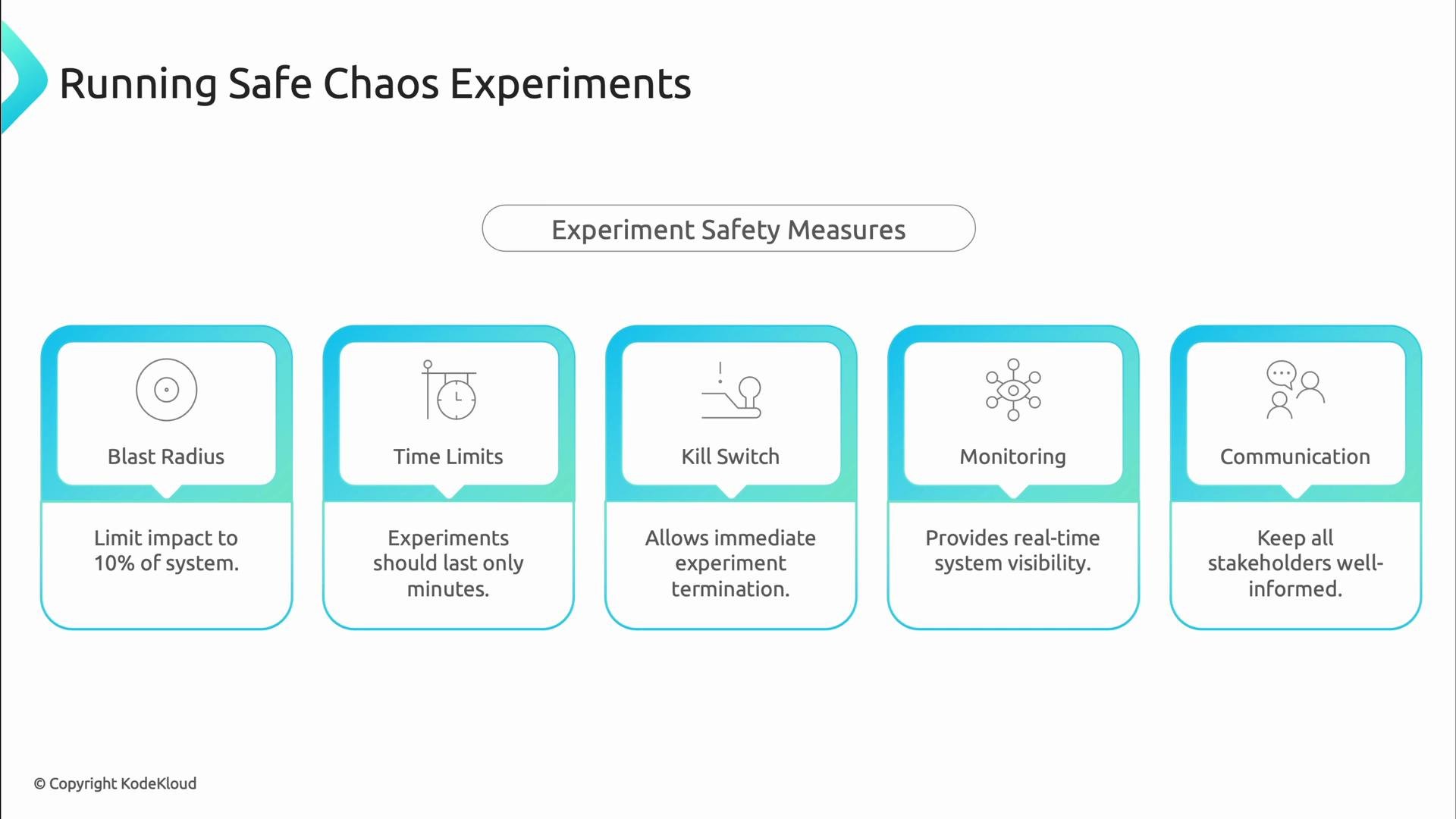
Design experiments to be reversible, observable, and time-bounded. If you can’t observe the impact or rollback quickly, pause the experiment until those controls exist.
Never run an experiment without a tested kill switch and real-time monitoring. Unobserved or irreversible tests can create major outages.
Real-world origin: Netflix and Chaos Monkey
Netflix’s migration to AWS exposed production failures that weren’t reproducible in traditional tests. In response, they created Chaos Monkey, a tool that randomly terminated instances during business hours to force teams to build services that recover automatically.
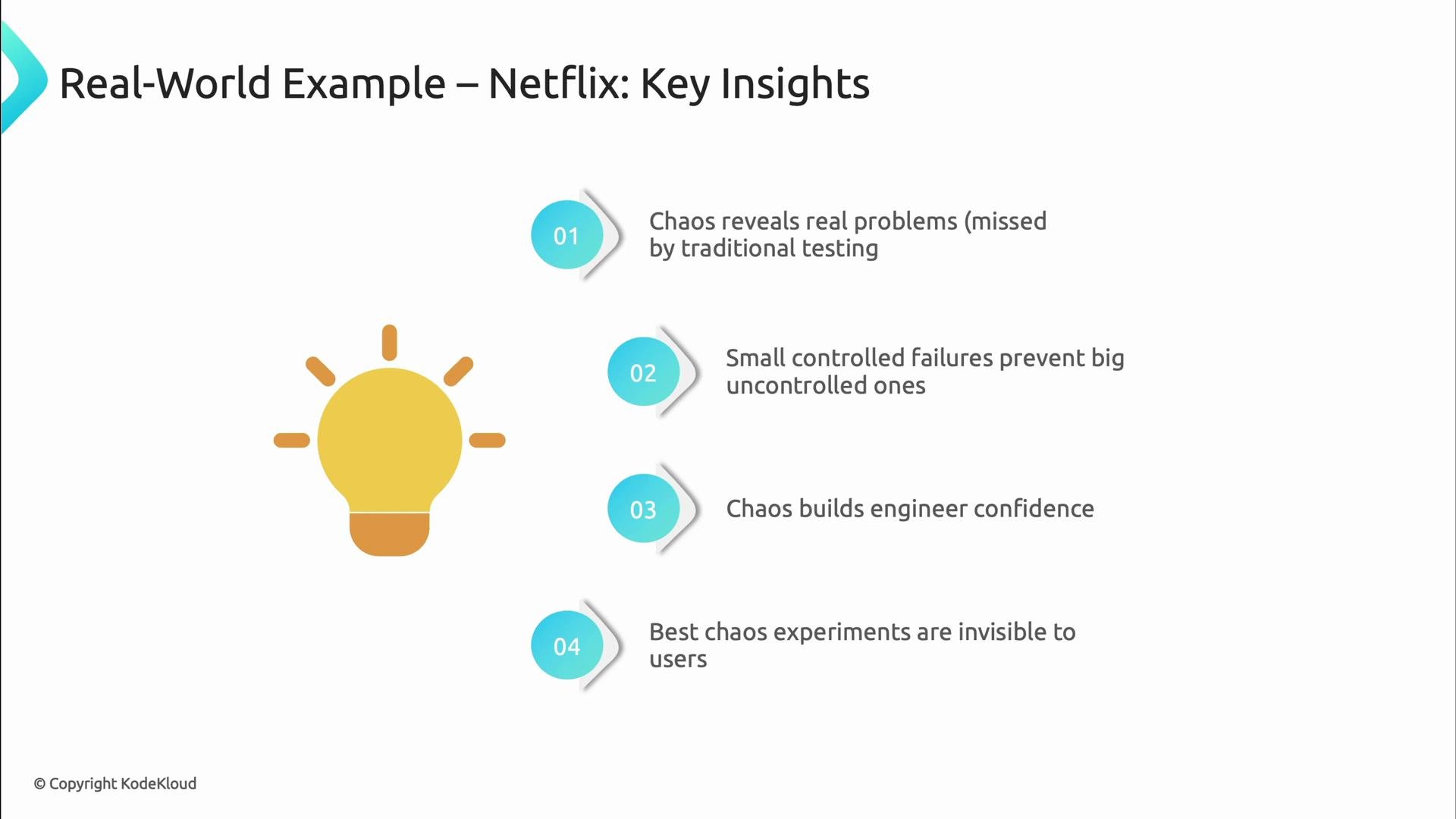
- Chaos reveals problems that traditional testing misses.
- Small, controlled failures reduce the risk of large uncontrolled outages.
- Regular experiments build engineering confidence—teams stop fear-driven avoidance of production.
- The best experiments are invisible to users: customers don’t notice, but systems become more robust.
Operational principles and maturity
Netflix codified several operational principles to make chaos practical:- Run chaos during business hours (failures happen then).
- Integrate chaos into deployment pipelines.
- Treat chaos as a continuous practice, not a one-off stunt.
- Measure everything—without metrics you cannot build confidence.

Summary
Chaos Engineering is a disciplined, scientific practice for discovering failure modes and improving resilience. When done safely—using small blast radii, defined hypotheses, strong observability, and tested rollback plans—chaos experiments become a powerful tool to reduce outage risk and raise operational confidence. A related advanced topic is the trade-off between cost efficiency and reliability, which ties engineering decisions to business impact and requires its own set of practices and measurements.Links and References
- Chaos Monkey (Netflix) — GitHub
- Simian Army (Netflix) — GitHub
- Kubernetes Documentation — Basics & Concepts
- Chaos Engineering resources — Principles and best practices