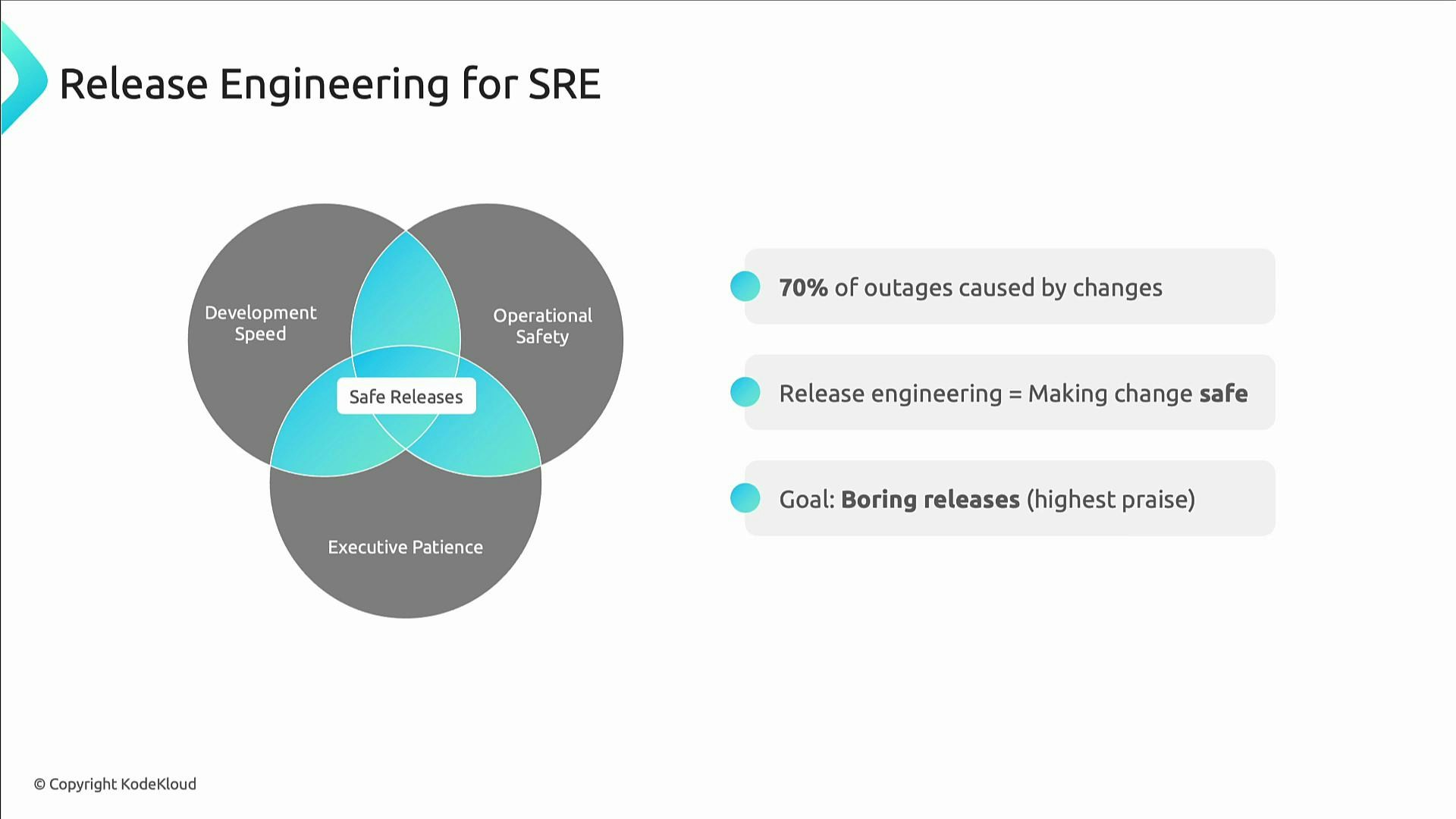
Core principles of safe release engineering
- Automate everything. Any manual step is a future outage vector.
- Use progressive delivery. Validate changes with a small percentage of traffic (e.g., 1%) before full rollout.
- Practice fast, tested rollbacks. If rollback is slower than deployment, the rollback process needs improvement.
- Always verify deployments with smoke tests to get quick feedback.
- Communicate relentlessly—silent deployments tend to become noisy incidents.
Apply automation to policy, approvals, and rollbacks. Automated “safety nets” (canaries, health checks, automatic rollbacks) let you move fast with confidence.
Deployment strategies — choose the right approach
Each strategy has trade-offs. Select the approach that matches your risk tolerance, infrastructure costs, and rollback needs.
Common guidance:
- Blue–Green is best when you can afford duplicate environments and need instant rollback.
- Canary deployments require solid monitoring and automated health gates.
- Feature flags decouple deployment and release — remove flags when stable.
- Rolling updates work well when instances are independent and stateless.

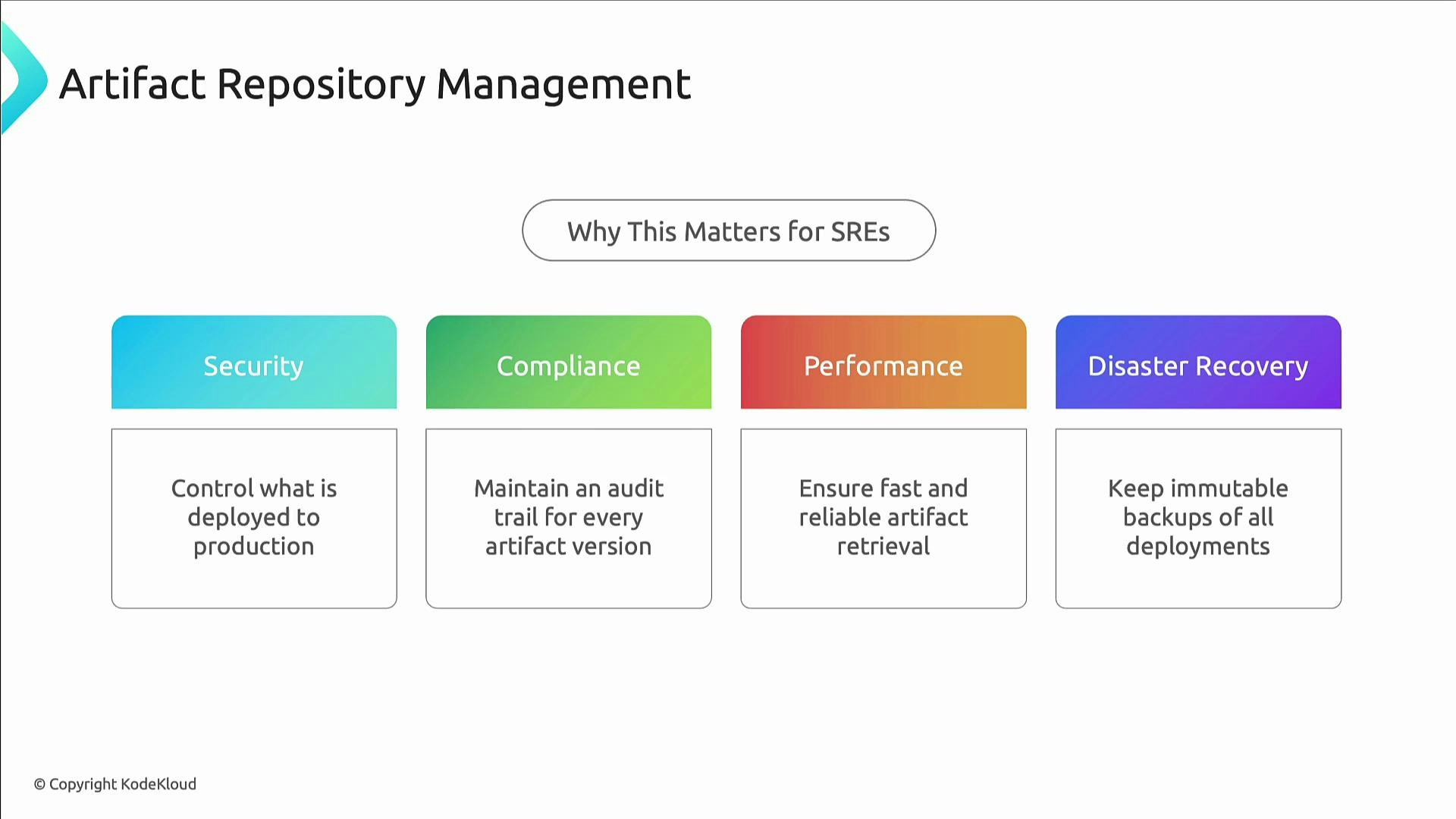
Artifact repository management
Artifact repositories are the core of a trustworthy software supply chain. They store Docker images, packages, and binaries and provide the guarantees needed for safe, auditable releases. Why they matter for SREs:- Security: control what is deployable.
- Compliance: retain audit trails for every version.
- Performance: accelerate retrieval and reduce network variability.
- Disaster recovery: immutable artifacts enable rollbacks and re-deployments.
- Use enterprise registries for production (AWS ECR, Google Artifact Registry) instead of public registries for critical systems.
- Enforce lifecycle policies to limit storage while keeping recovery points.
- Apply strict access control: automation writes, humans read or approve where necessary.
- Make production images immutable and block overwrites.
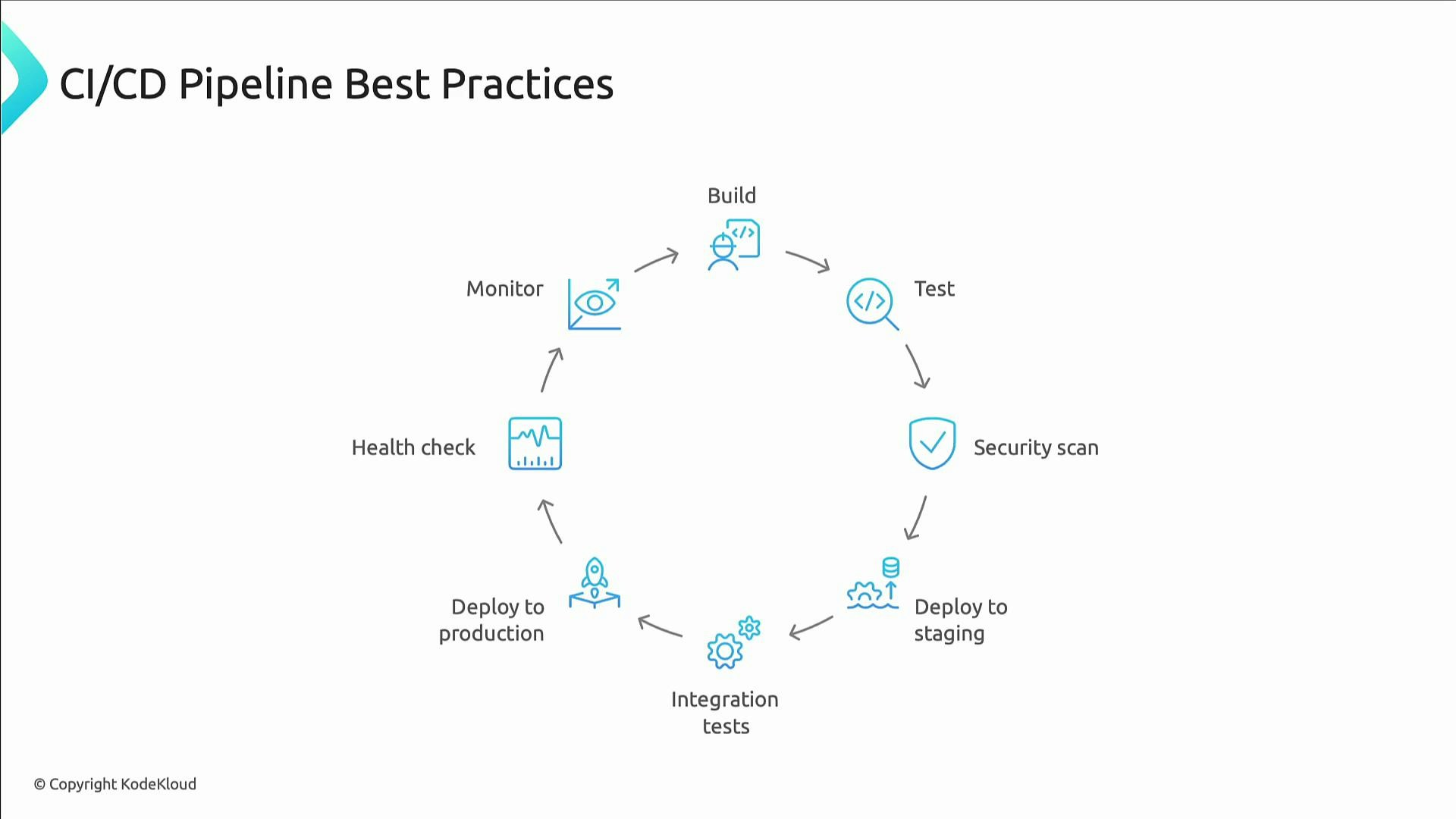
CI/CD pipeline best practices
A robust pipeline automates build, test, security, deployment, verification, and monitoring. Key elements:- Build artifacts in a reproducible, hermetic environment.
- Run unit, integration, and end-to-end tests before artifacts are promoted.
- Run security and vulnerability scans early (shift-left).
- Deploy to staging with automated integration tests and performance checks.
- Require explicit approvals for risky production changes (policy as code).
- Perform health checks and automated rollbacks on failure.
Secrets management
Secrets and credential leaks are a common source of incidents. Follow these rules:- Never hard-code secrets in source code or config files.
- Centralize secrets in a dedicated secrets manager (HashiCorp Vault, AWS Secrets Manager, etc.).
- Use short-lived, revocable credentials and automate secret rotation.
- Monitor for leaked secrets and automate incident response.
Never commit credentials or long-lived keys to source control. Assume secrets will leak and design for short-lived, revocable credentials plus automated rotation and monitoring.

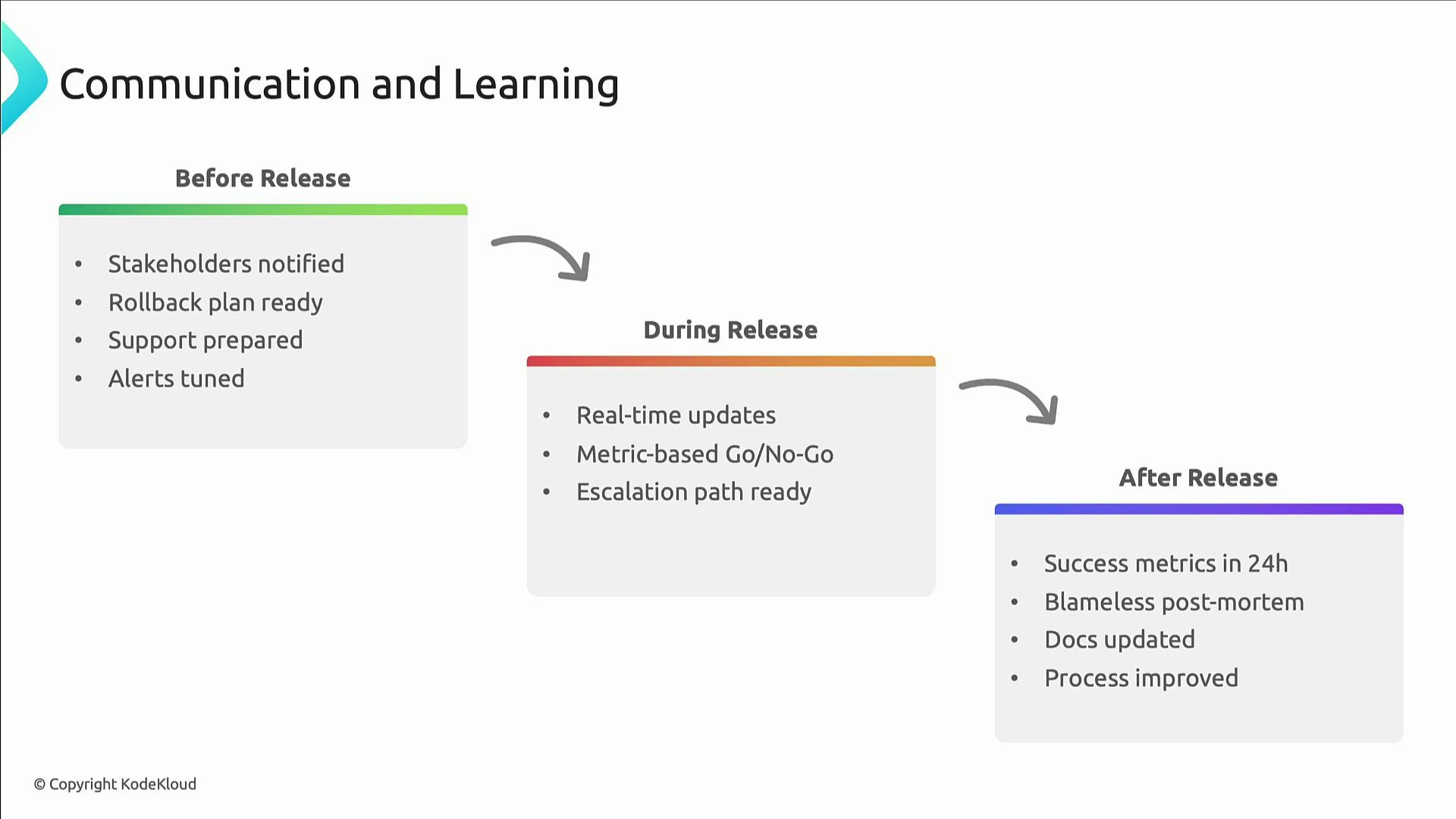
Communication and continuous learning
Release engineering is as much about people and process as it is about tools.- Before release: Notify stakeholders, prepare the support rota, and document rollback and mitigation plans.
- During release: Publish real-time updates and decide Go/No-Go using metrics (error rate, latency, saturation) rather than intuition.
- After release: Compare outcomes to success criteria, run blameless postmortems on failures, and update runbooks and automation.
Wrap-up
This lesson covered the operational patterns, technical controls, and organizational practices that make change safe and predictable:- Automation and policy-as-code
- Progressive delivery (canaries, feature flags)
- Fast, tested rollback processes
- Artifact repository management with lifecycle and access controls
- Secure CI/CD pipelines with shift-left security
- Secrets management with rotation and monitoring
- Continuous communication and blameless learning
Links and references
- Kubernetes Documentation
- Docker Hub
- AWS Elastic Container Registry (ECR)
- Google Artifact Registry
- HashiCorp Vault
- AWS Secrets Manager