- Startup e-commerce site
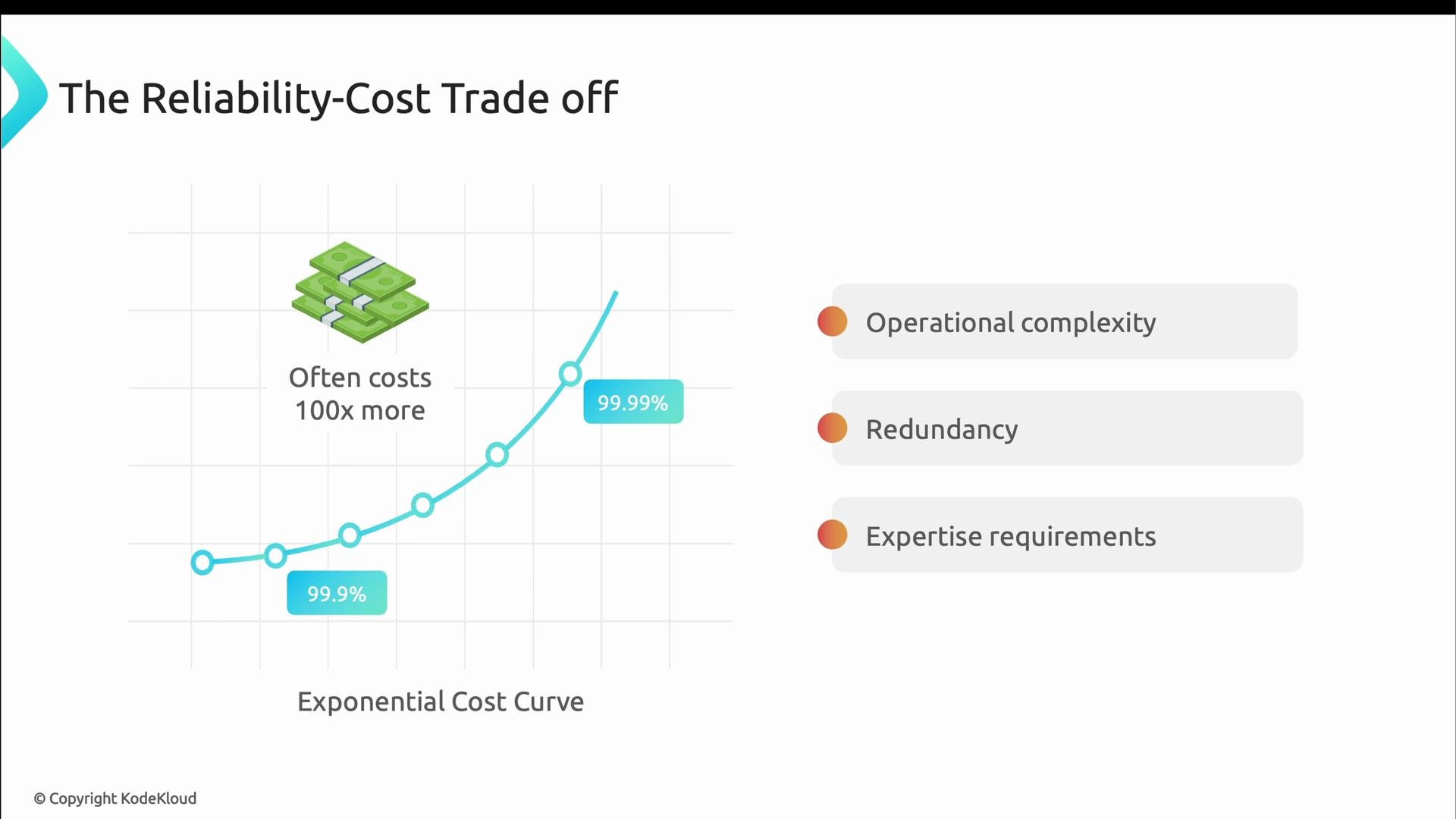
- 99.9% reliability → ≈ $6,000 / month
- 99.99% reliability → ≈ $53,000 / month (≈9× increase)
- Enterprise financial services
- 99.99% reliability → ≈ $150,000 / month
- 99.999% reliability → ≈ $750,000 / month (≈5× increase)

- Over‑engineering trap: Spending a disproportionate portion of engineering budget (e.g., 60%) to reach four nines for a feature used by only 10% of customers, while the core product runs at 99.5% — misaligned investment.
- Under‑engineering disaster: Cutting $20K/month in infrastructure costs, then suffering a major outage (for example on Black Friday) that costs millions in lost revenue and reputation.

- Predictive scaling: Forecast traffic spikes and scale out in advance (used at scale by companies such as Netflix).
- Reactive scaling: Increase replicas/resources when metrics (CPU, memory, queue depth) cross thresholds. Kubernetes Horizontal Pod Autoscaler (HPA) is a common reactive tool.
- Graceful degradation: Reduce or disable lower-priority, expensive features when capacity is constrained so the system remains available.
- Cost‑optimized instance mix: Combine reserved, on‑demand, and spot instances to balance predictable baseline capacity and inexpensive burst capacity.

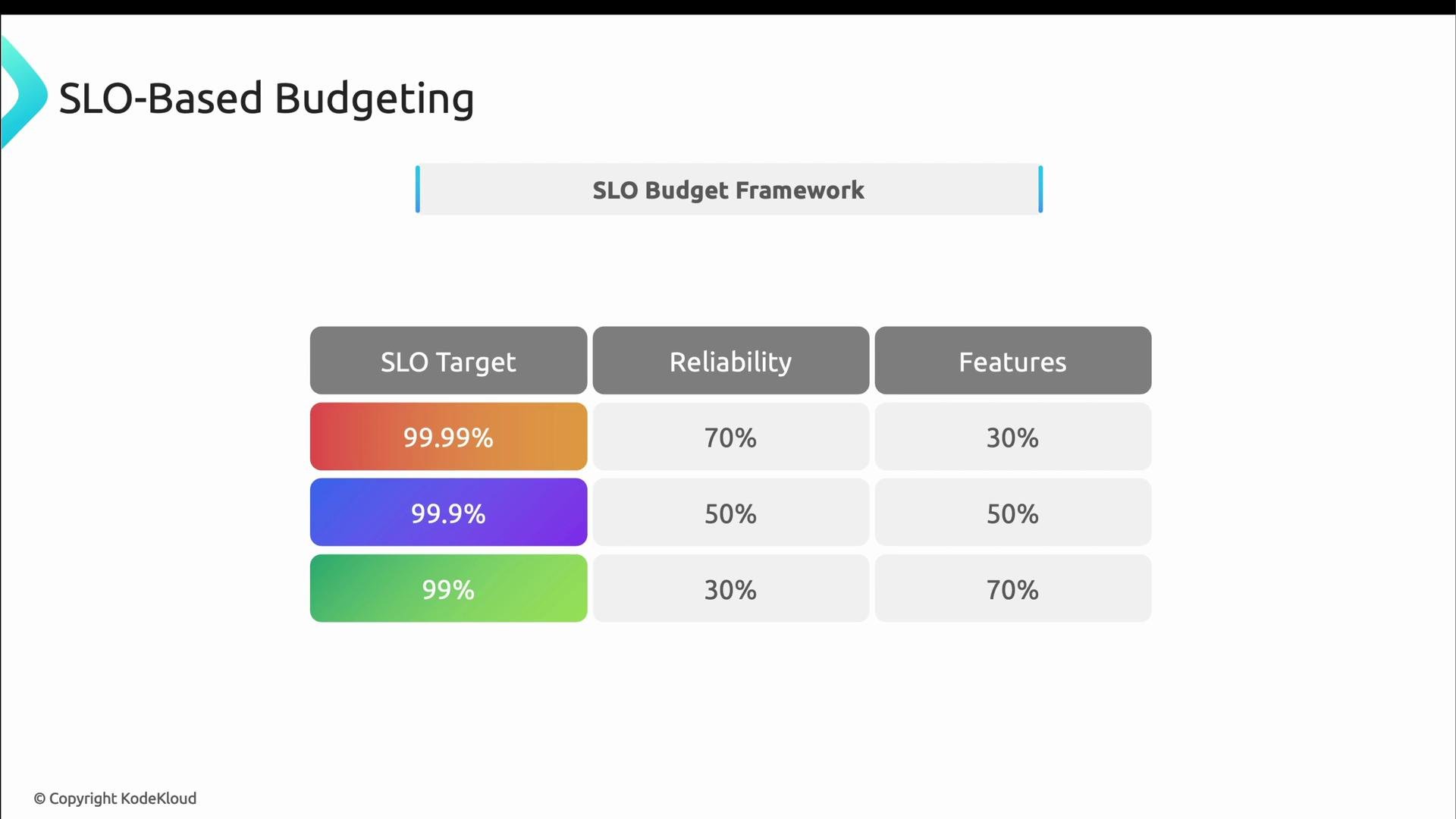
- 99.99% SLO: very strict — often requires considerable investment and may consume a high fraction of monthly spend.
- 99.9% SLO: moderate — budgets are often split between reliability and new features.
- 99% SLO: relaxed — more budget remains available for feature development.

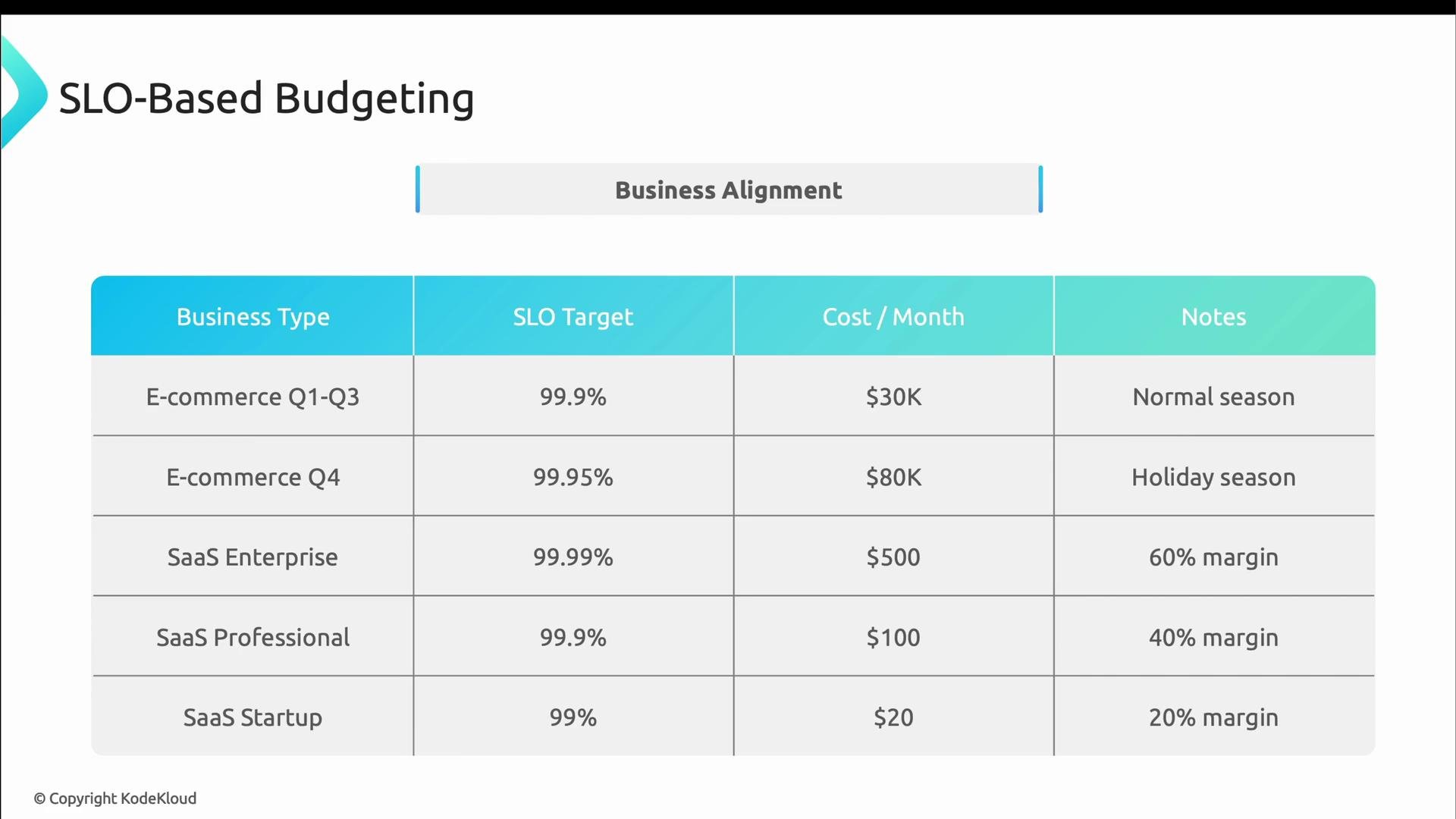
- E‑commerce might operate at 99.9% for most of the year (~80K/mo).
- SaaS vendors commonly tier SLOs: enterprise customers expect four nines (large investment), professional tiers get three nines, entry-level tiers accept lower targets.
- Business alignment: Higher-value or mission‑critical customers get stricter SLOs funded by higher investment.
- Resource allocation: Budgets are guided by concrete reliability commitments rather than guesswork.
- Risk management: When outages burn error budget, prioritize reliability work until the error budget is replenished.
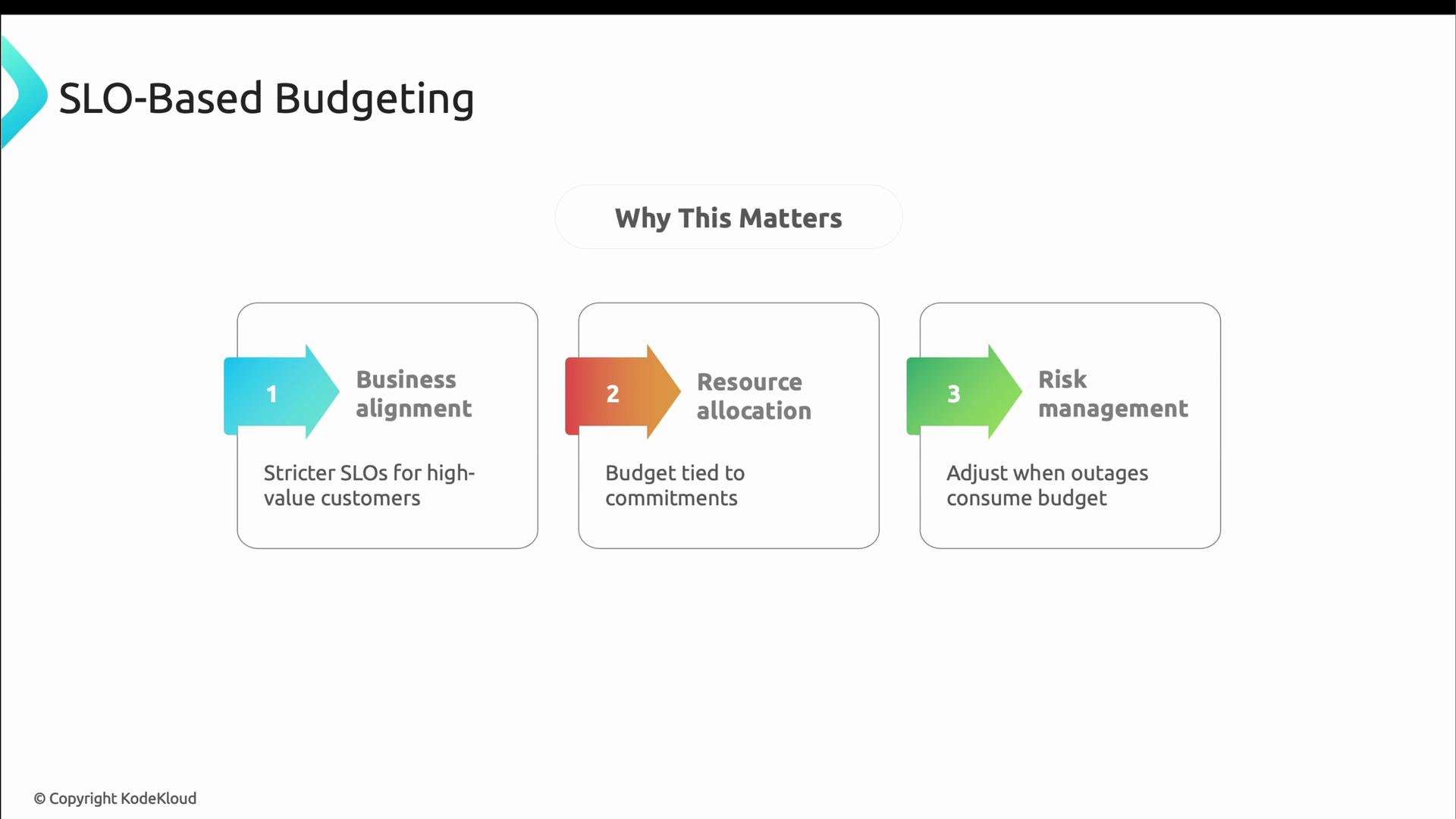
SLOs are business commitments. Use them to transparently decide where to invest: if an outage causes you to burn error budget, that’s a clear signal to prioritize reliability work over feature development until the error budget is replenished.
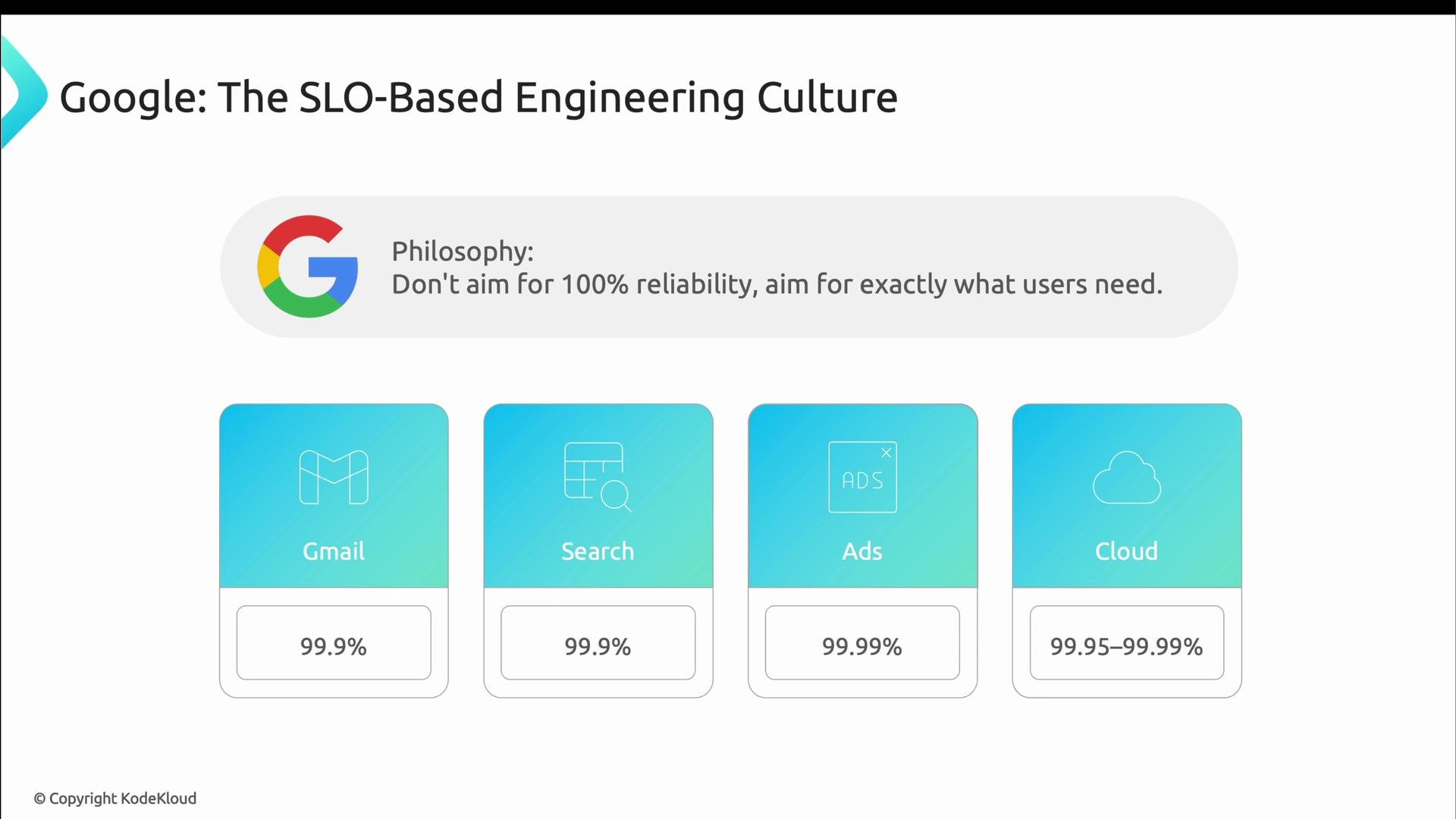
- Gmail and Search: ~99.9% (users tolerate brief delays)
- Google Ads: ~99.99% (downtime directly impacts revenue)
- Google Cloud Services: 99.95%–99.99% depending on SLAs
- Reliability cost grows nonlinearly as targets tighten; every extra “9” usually requires materially more investment.
- Use autoscaling, graceful degradation, and mixed instance strategies to make reliability cost-effective.
- Tie budget to SLOs: the error budget should guide when to prioritize reliability work over feature development.
- Align SLOs to business context and customer tiers so spending matches value delivered.
- Kubernetes Horizontal Pod Autoscaler: https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/
- Google SRE and SLO culture: https://sre.google/
- Kubernetes autoscaling overview and best practices (additional guides): https://kubernetes.io/docs/concepts/cluster-administration/autoscaling/