This course emphasizes practical labs and exercises so you can apply SRE concepts in realistic environments.
- Fundamental SRE concepts and history
- How to design and measure reliability with SLIs, SLOs, and error budgets
- Reducing toil through automation and sound system design
- Incident response, on-call best practices, and blameless postmortems
- Release engineering and infrastructure-as-code for safe deployments
- Observability, monitoring, and alerting patterns
- Advanced topics: chaos engineering, cost-aware reliability, and trade-offs
Course detail and sequence
-
Origins, culture, and core principles
- We begin by tracing how SRE evolved and the core philosophies that guide it.
- Compare SRE and DevOps in practice and learn how teams are organized to support reliability.
- Useful reference: DevOPS and SRE Basics.
-
SLIs, SLOs, and error budgets
- Learn to design Service Level Indicators (SLIs), set meaningful Service Level Objectives (SLOs), and implement error budgets to balance feature velocity and system stability.
- SLO-driven decisions help prioritize work and make trade-offs visible to stakeholders.

-
Foundations of reliability engineering
- Deep-dive on designing SLIs, setting SLO targets, and measuring outcomes.
- Learn approaches for visualizing reliability metrics and using them to drive operational decisions.
-
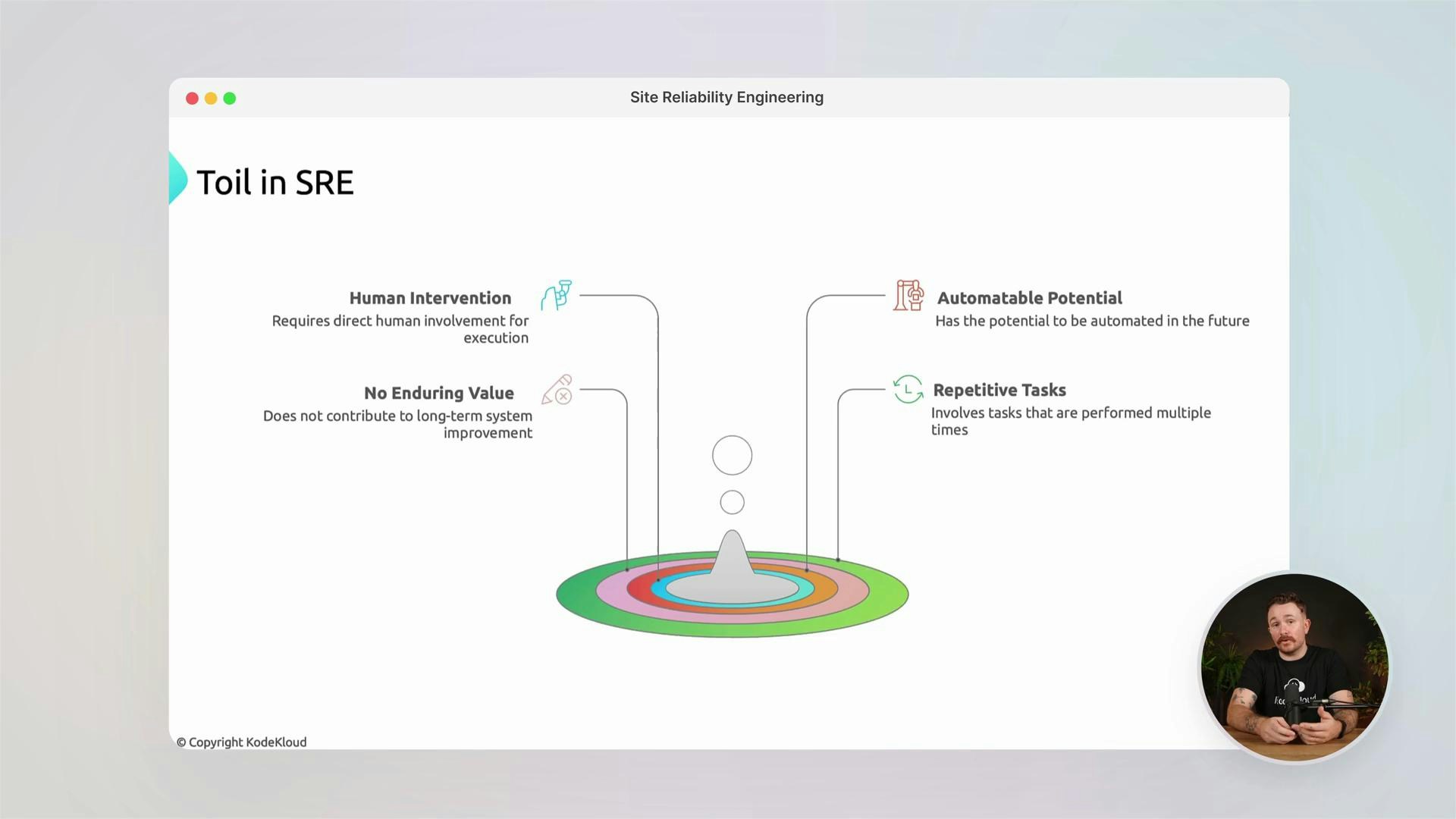
Managing complexity, risk, and toil
- We’ll look at how system complexity increases failure modes and how to manage dependencies and scale.
- Techniques to reduce operational toil include automation, thoughtful APIs, and simplified runbooks.
- Incident management and on-call operations
- Prepare for and respond to incidents with proven processes: alerting strategy, incident command, and scalable communication.
- We emphasize blameless postmortems as a continuous improvement mechanism.

On-call rotations and incident response can be stressful. Prioritize sustainable rotations, clear runbooks, and automation to reduce human load and burnout.
- Release engineering and deployment readiness
- Learn readiness checks, automated pipelines, and configuration management to ensure safe releases.
- Topics include feature flags, canary rollouts, and rollback strategies.
- Observability, monitoring, and telemetry
- Learn to collect, store, and visualize telemetry (logs, metrics, traces).
- Design alerts that are actionable and aligned with SLOs to avoid alert fatigue.
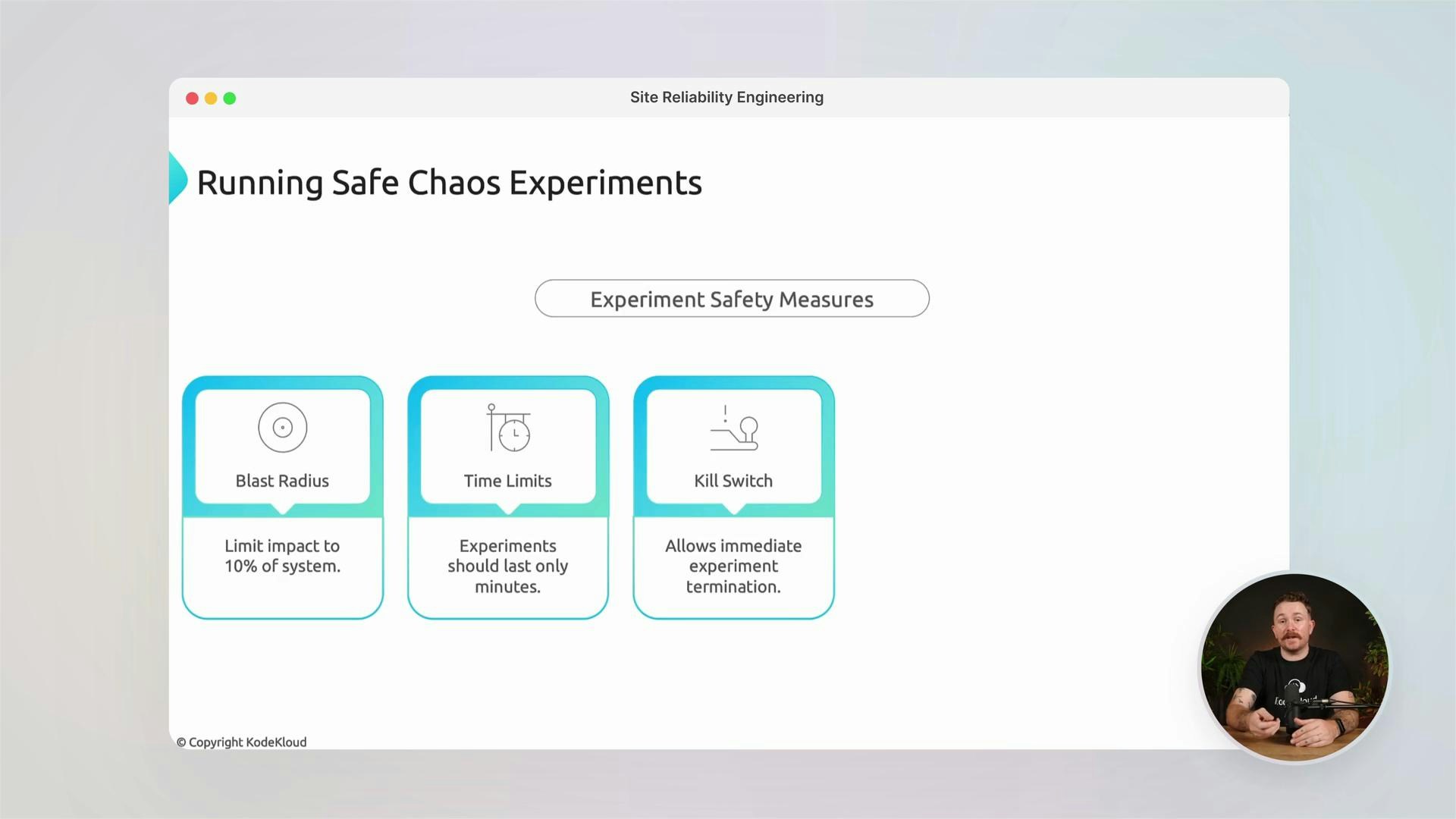
- Advanced reliability: Chaos engineering and cost-aware design
- Learn to plan and execute safe chaos experiments that uncover hidden failure modes.
- Design reliability with cost trade-offs in mind so systems remain resilient and economically sustainable.
- Join the forums and peer groups to ask questions, share solutions, and collaborate on hands-on labs.
- Continuous learning and community feedback are key to becoming an effective SRE.
- SRE Workbook and Resources (Google)
- DevOps and SRE Basics — KodeKloud
- Chaos Engineering — KodeKloud
- Kubernetes Documentation — Concepts