- What SRE looks like today and why it matters
- Typical entry-level responsibilities and how to approach them
- Paths into SRE (operations, development, or new-to-tech)
- Practical ways to gain experience (on the job, side projects, open source)
- Essential technical and soft skills to focus on
AI amplifies the scale and complexity of production systems. Expect more opportunities to shape how AI-powered services are operated, observed, and safely released—making SRE skills more valuable, not less.
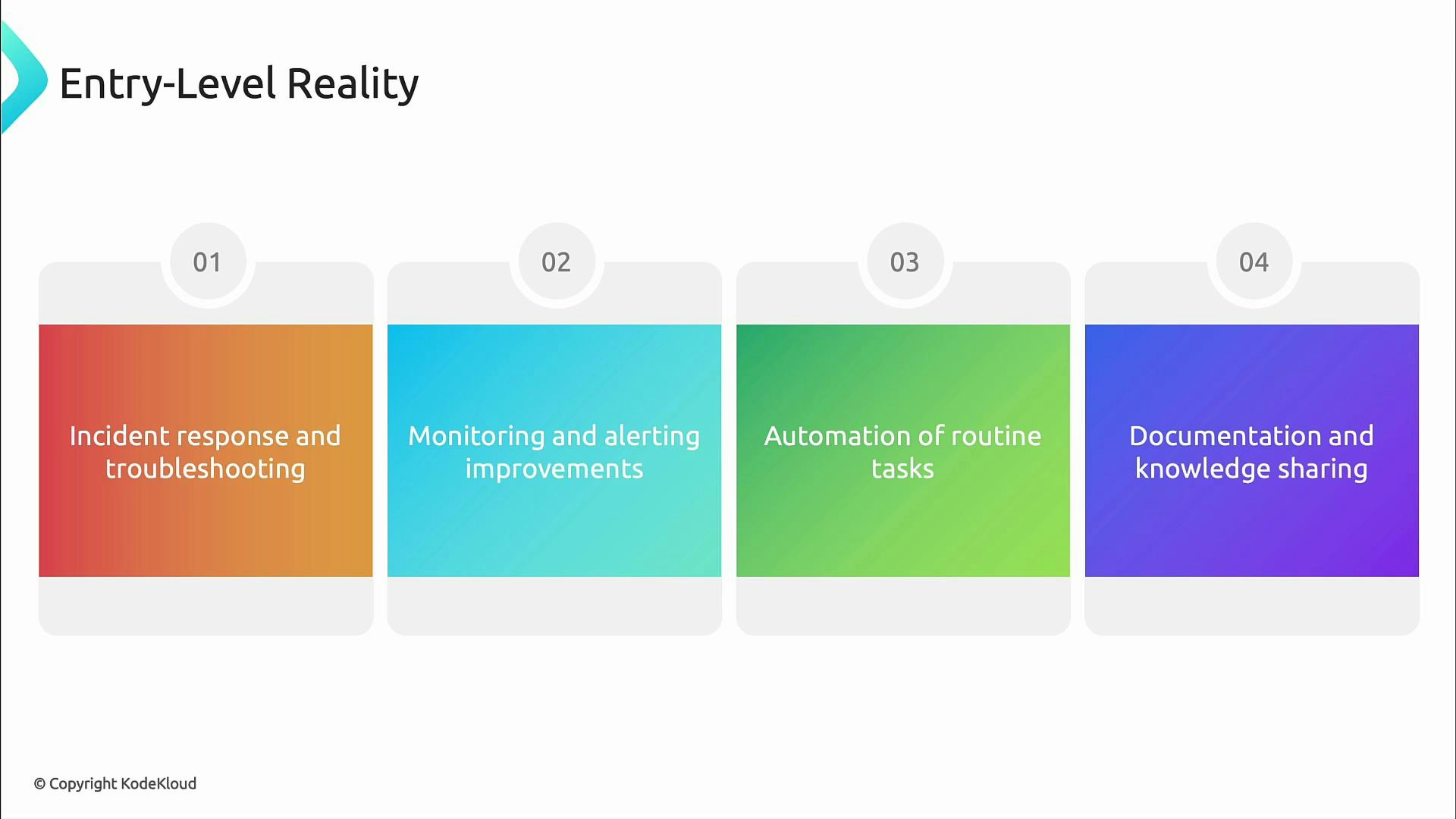
Entry-level reality: what to expect day one
At the entry level you’ll often be thrown straight into operational work. Common responsibilities include:- Incident response and troubleshooting
- Tuning monitoring and alerting
- Automating repetitive tasks to reduce toil
- Writing and improving documentation and runbooks
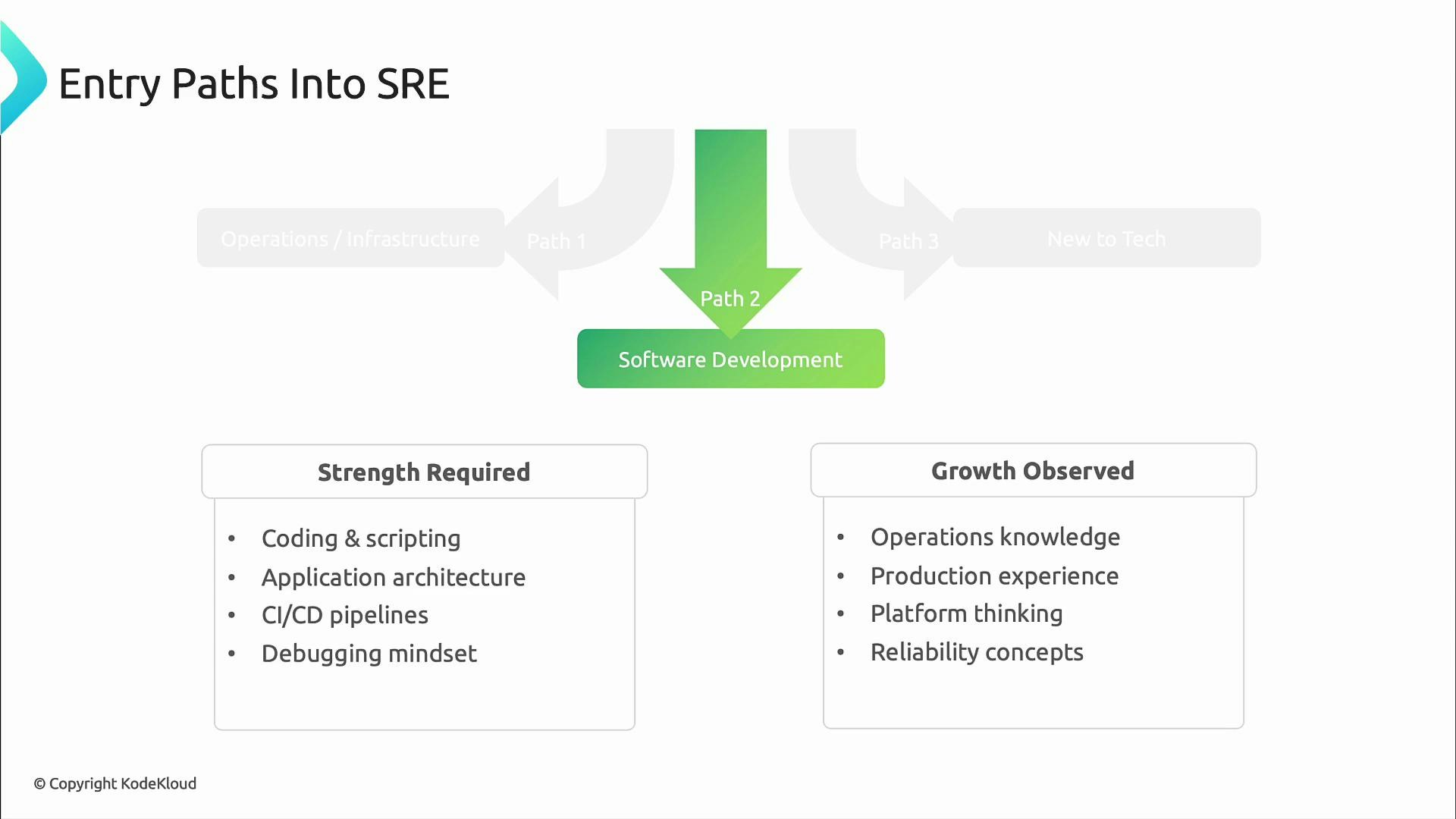
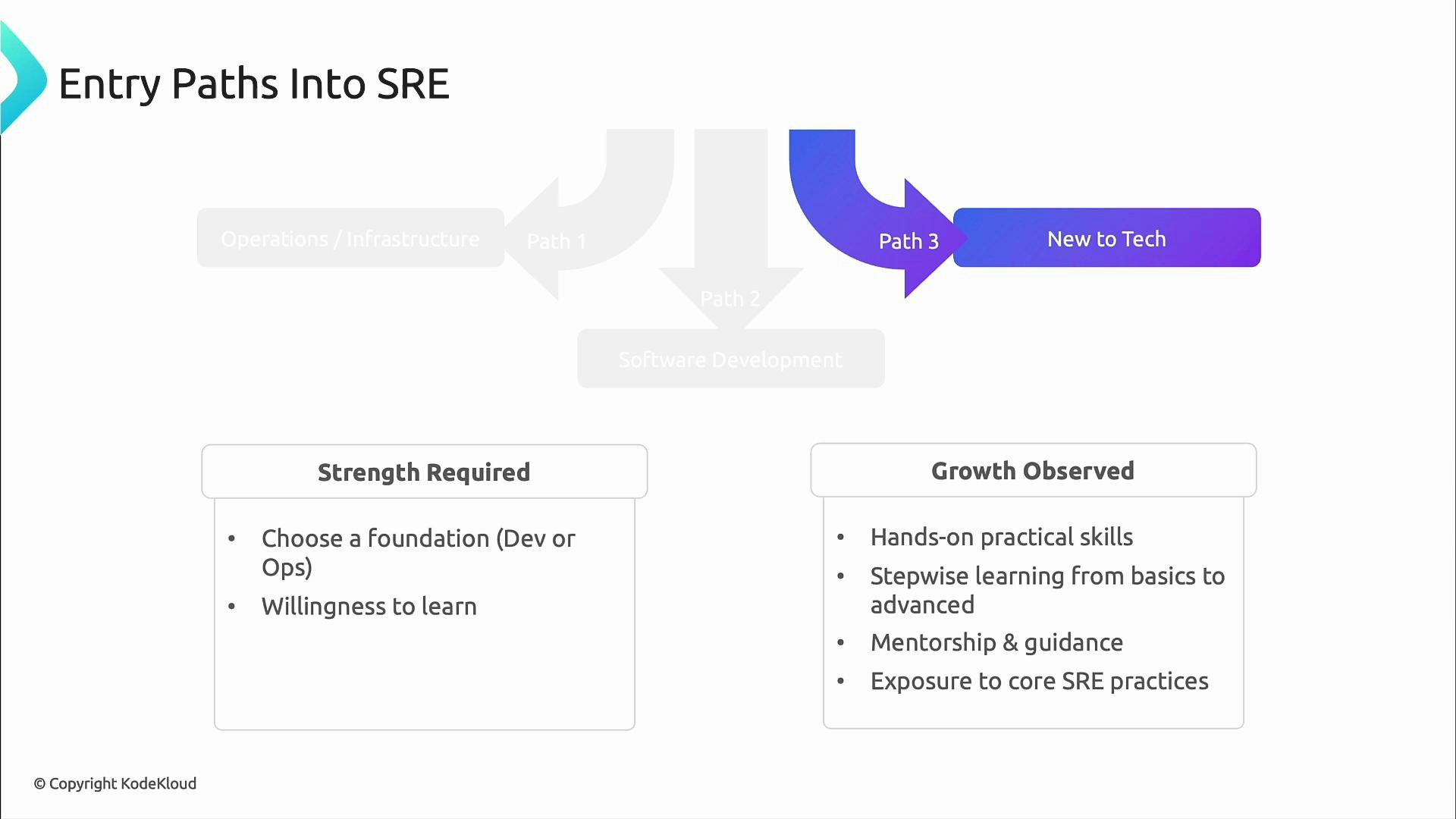
Paths into SRE: choose a starting foundation
There are multiple, often non-linear paths into SRE. Each background brings strengths and gaps you can address with targeted learning. If you come from operations or infrastructure, you likely already know production systems, troubleshooting, monitoring, and on-call practices. To level up for SRE, focus on programming and automation (scripting, APIs), infrastructure-as-code, and fundamental reliability concepts like SLOs and error budgets.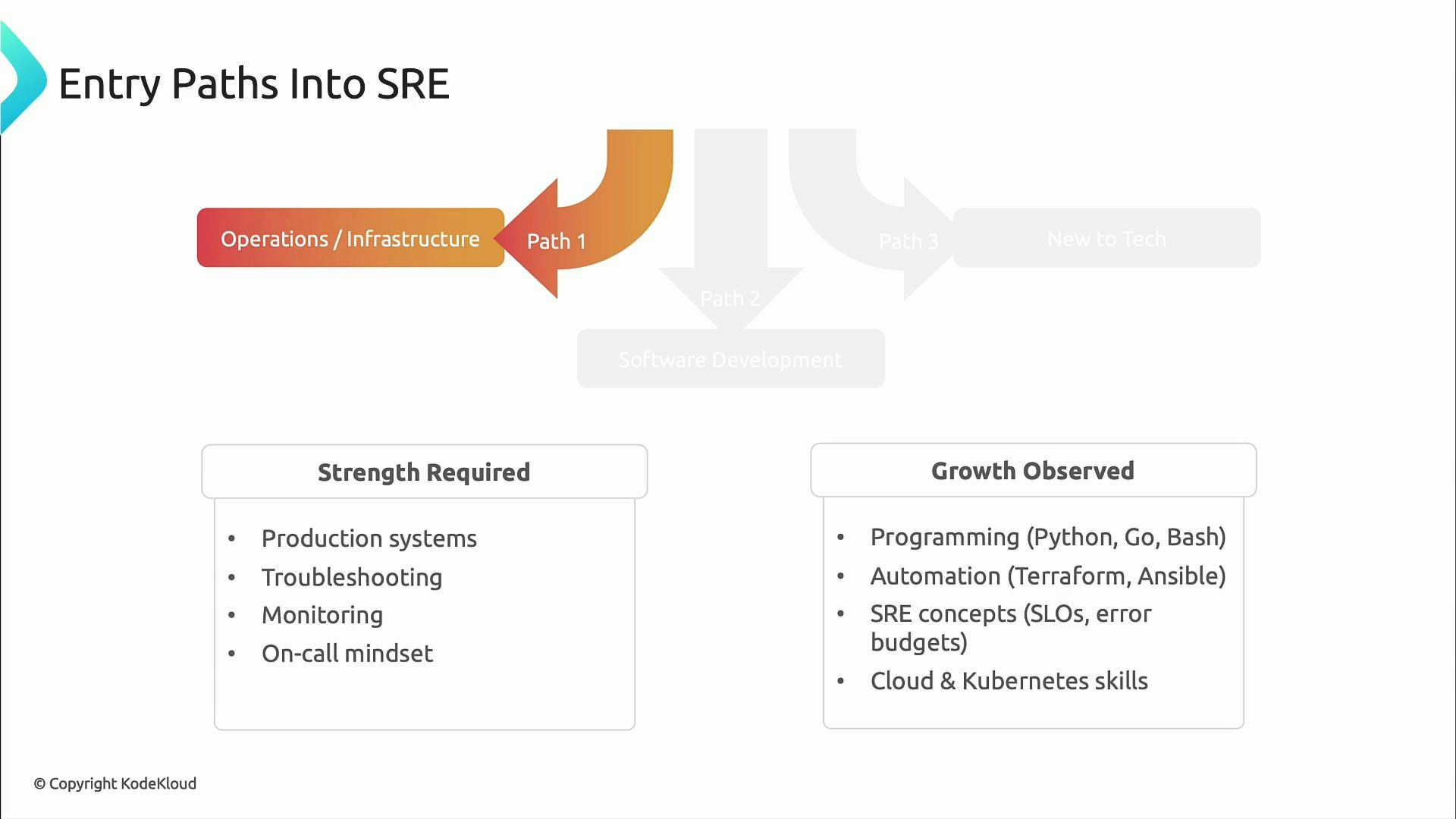
Useful learning resources:
- Python Basics
- Golang
- Advanced Bash Scripting
- Terraform Basics Training Course
- Learn Ansible Basics - Beginners Course
- Cloud Computing Fundamentals
- Kubernetes for the Absolute Beginners - Hands-on Tutorial
- EFK Stack: Enterprise-Grade Logging and Monitoring
- Learning Linux Basics Course & Labs
- Networks and Communications
Core technical skill areas for SREs
To succeed, focus on three broad technical domains:
These areas combine to help you keep systems reliable and scalable.
Gain experience where you are
You don’t need the SRE title to build SRE expertise. In your current role, look for opportunities to:- Volunteer for reliability work (alerts, runbooks, incident drills)
- Automate repetitive tasks to free team bandwidth
- Join post-incident reviews and start contributing to remediation
- Track metrics that show impact (MTTR, alert noise reduction, error rates)

- Build a personal SRE lab: deploy a small app, add metrics and alerts, and automate deployments.
- Add observability to a website: metrics, logs, and tracing.
- Create an API health checker that triggers alerts and dashboards.
- Automate CI/CD pipelines and practice rolling updates and canary releases.
When experimenting, avoid making risky changes in production. Use local labs, staging environments, or small canary deployments to validate automation and monitoring before wide rollout.
Soft skills: communication and teamwork
SRE is not purely technical. Clear communication and collaboration are essential:- Explain technical issues to non-technical stakeholders
- Write concise incident reports and postmortems
- Provide succinct updates during incidents
- Present reliability work and trade-offs to product and leadership

Practice continuously and reflect
SRE is a craft that improves with repetition and reflection. Tactics to accelerate learning:- Write technical notes or blog posts to clarify your understanding
- Participate in communities, forums, and meetups
- Study incident postmortems—real incidents teach operational reality faster than theory
- Run test types (load, stress, soak, spike) to see how systems behave under different pressures
