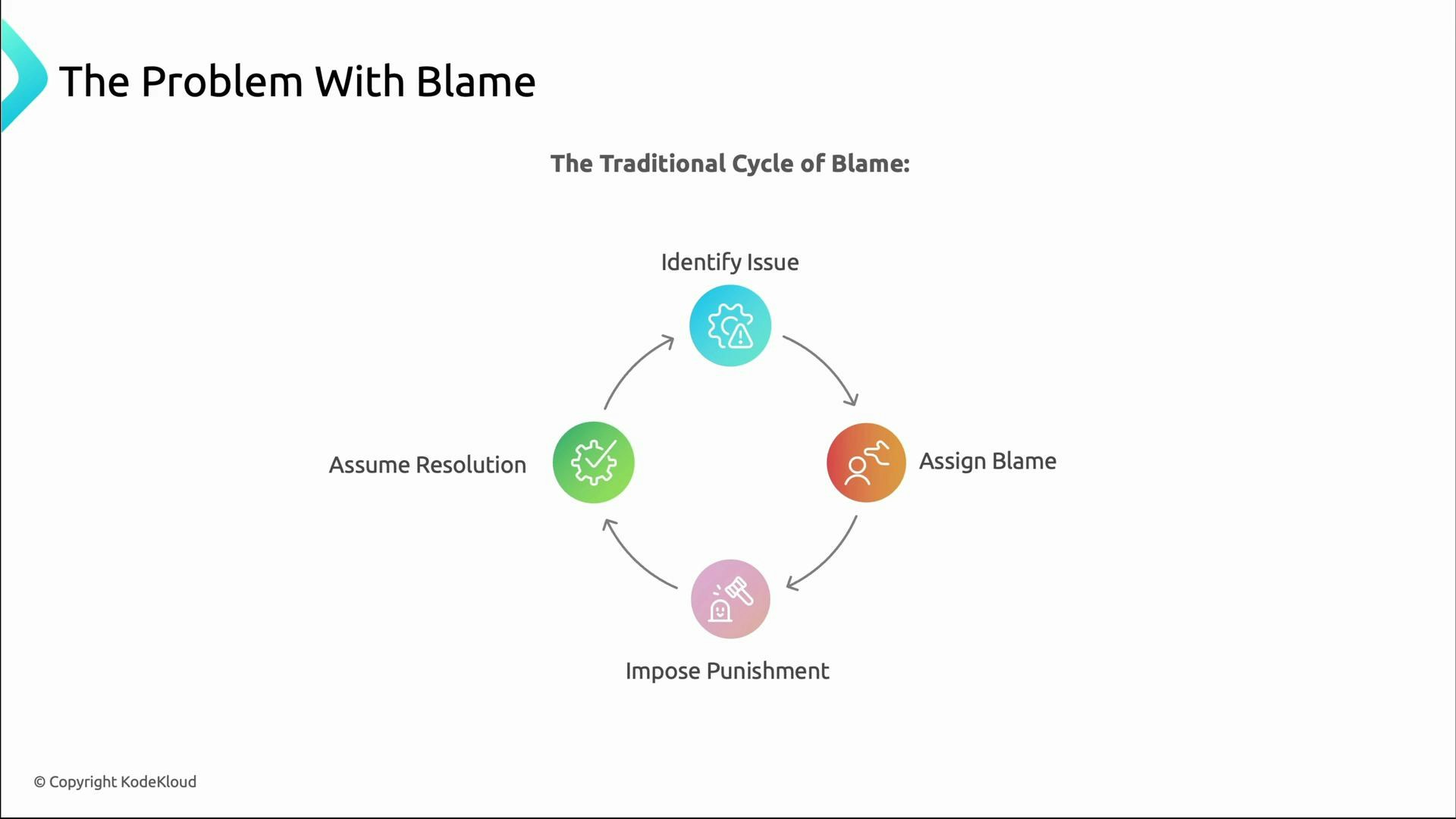
The problem with blame
Imagine two teams facing the same outage:- Team A points fingers, engineers become defensive, details are hidden, and trust erodes.
- Team B assumes everyone acted with the best knowledge available, focuses on systems and processes, documents what happened, and improves.

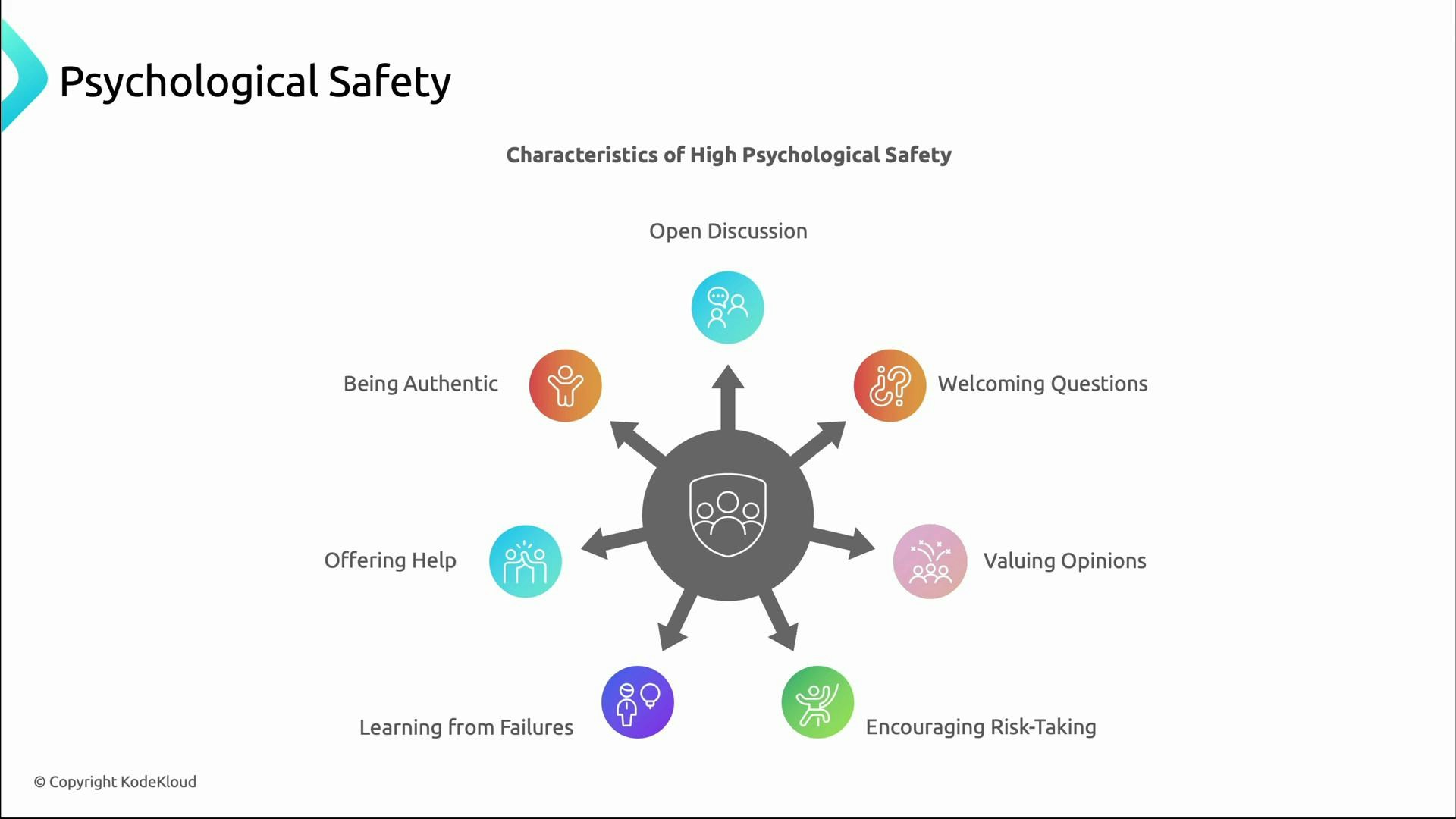
Psychological safety: the foundation of blamelessness
Blamelessness depends on psychological safety: people must feel safe to speak up, share questions, and admit mistakes without fear of retribution. High-safety teams:- Encourage open discussion and diverse viewpoints
- Welcome questions and constructive challenge
- Value learning and accept risk-taking
- Offer help freely and normalize admitting mistakes

What is a postmortem (retrospective)?
A postmortem is a structured review held after an incident. Its purpose is to:- Document what happened with an objective timeline
- Understand why the incident occurred through root cause analysis
- Produce concrete, actionable improvements to reduce recurrence
- Spread knowledge across the organization and institutionalize learning

How to run effective postmortems
A reliable postmortem process reduces blame and increases engineering effectiveness. A typical four-step workflow:- Preparation
- Schedule the review soon after the incident (once immediate remediation is done).
- Collect logs, alerts, timelines, runbooks, graphs, and any related artifacts.
- Invite operators, developers, and stakeholders who can contribute facts and context.
- Meeting structure
- Walk through an objective timeline (who did what and when).
- Identify contributing factors and failure modes.
- Brainstorm concrete improvements and prioritize them.
- Documentation
- Create a neutral, fact-based writeup: summary, timeline, impact, root cause analysis, action items, and lessons learned.
- Avoid accusatory language; focus on systems, processes, and gaps.
- Follow-up
- Track action items to completion with owners and deadlines.
- Share the postmortem and any remediation progress broadly.

Follow-up is essential. Without tracking and completing action items, a postmortem becomes a historical record instead of a mechanism for change.
- What happened? — An objective, time-ordered narrative.
- Why did it happen? — Contributing factors and causal chains.
- How did we respond? — What mitigations were used and how effective they were.
- What did we learn? — Technical and process observations.
- What will we change? — Specific, owned action items to reduce recurrence.
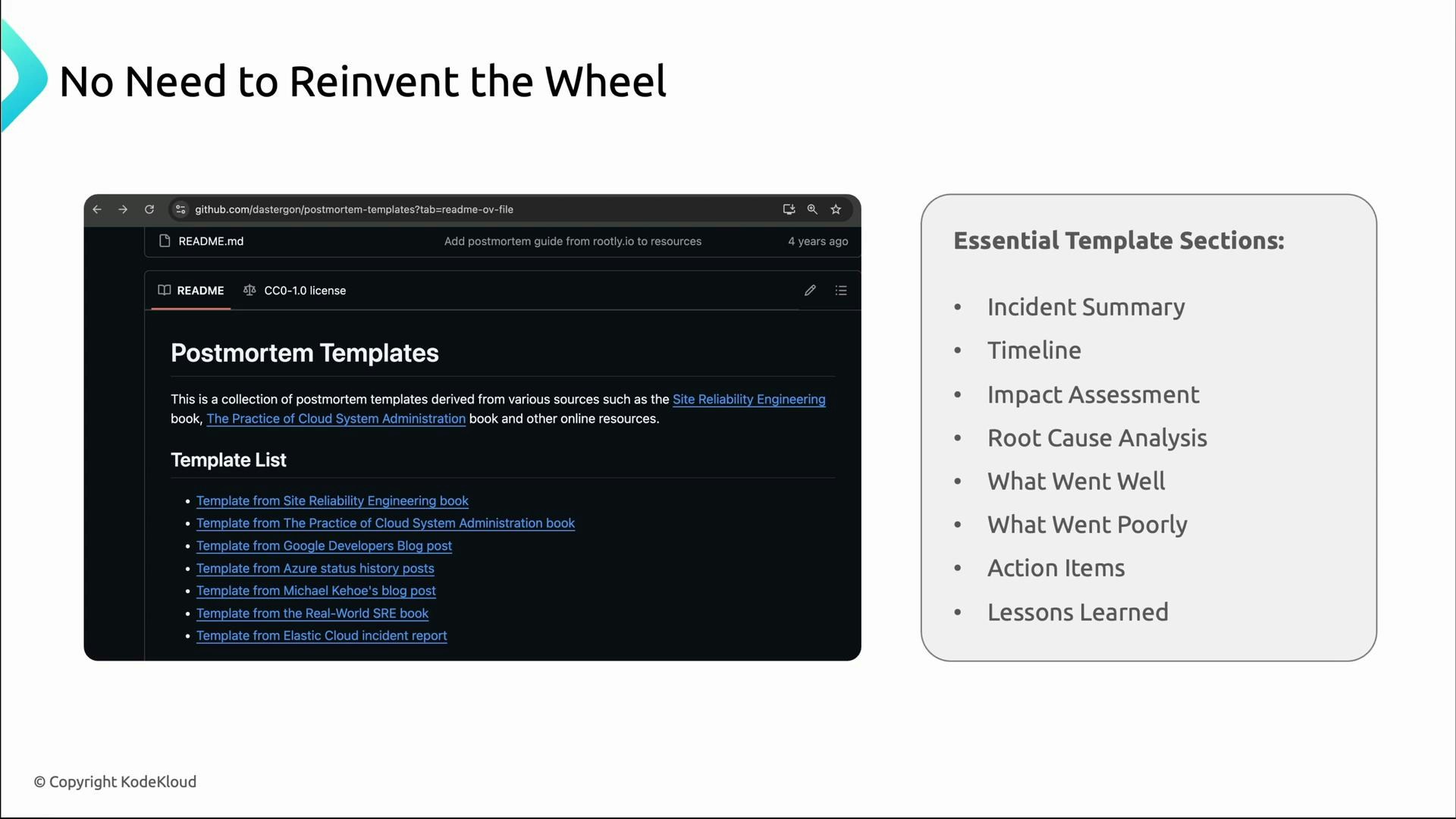
Postmortem template (recommended sections)
Use templates from SRE practitioners to keep postmortems consistent. Below is a concise template and purpose for each section.
You can adapt this structure to your tooling (GitHub, Confluence, Google Docs, or a ticketing system) and your incident severity levels.
Root cause analysis (RCA)
Root cause analysis should dig beyond human error to identify systemic contributors: tooling gaps, ambiguous runbooks, insufficient automation, missing tests, or unclear ownership. Techniques to improve RCA include:- Five Whys (iterate “why” until you find systemic causes)
- Fishbone/Ishikawa diagrams (categorize contributing factors)
- Timeline correlation (relate metrics, logs, and human actions)
- Fault tree analysis (map dependencies and failure paths)
Share, track, and improve
Postmortems are only useful if action items are tracked and learnings spread. Make postmortems accessible (with appropriate privacy controls), incorporate recurring findings into onboarding and runbooks, and regularly review outstanding action items in team rituals.Further reading and references
- Site Reliability Engineering: How Google Runs Production Systems — foundational SRE practices, including postmortems.
- Kubernetes Documentation — Concepts — incident categories often relate to orchestration and infra.
- GitHub collections of public postmortems (search “postmortem” or “incident report” on public repos) — curated examples accelerate learning.
- The Postmortem Template pattern — many industry templates exist; reuse rather than reinvent.