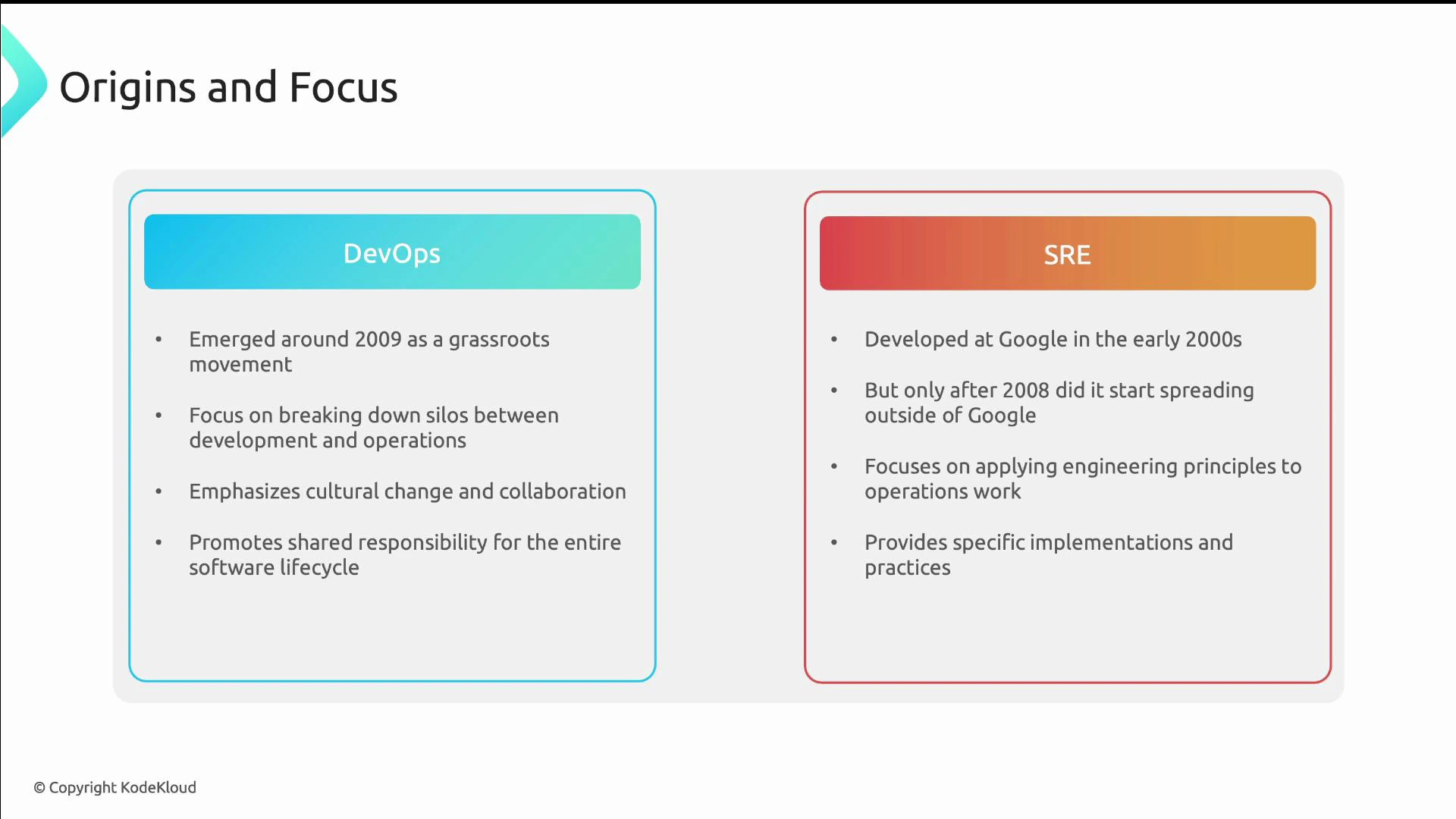
DevOps and Site Reliability Engineering (SRE) are closely related approaches to building and running software, but they have different origins, emphasis, and methods. Both aim to deliver value faster and keep systems reliable, yet DevOps is primarily a cultural and organizational philosophy while SRE applies software engineering practices specifically to operations and reliability. We’ll start with their origins. DevOps emerged around 2009 as a grassroots movement focused on removing silos between development and operations. It centers on cultural change, collaboration, and shared responsibility across the software lifecycle. SRE originated at Google in the early 2000s as a formal effort to apply engineering practices to operational problems. By around 2008 it began spreading beyond Google, bringing specific, measurable practices for managing reliability.Documentation Index
Fetch the complete documentation index at: https://notes.kodekloud.com/llms.txt
Use this file to discover all available pages before exploring further.
If you want a structured introduction to the cultural practices that complement SRE, consider the Fundamentals of DevOps course by Michael Forrester: https://learn.kodekloud.com/user/courses/fundamentals-of-devops. Pairing DevOps fundamentals with core SRE readings (for example, the Google SRE book at https://sre.google/books/) gives a fuller, practical foundation.
Principles and practices: How DevOps and SRE compare
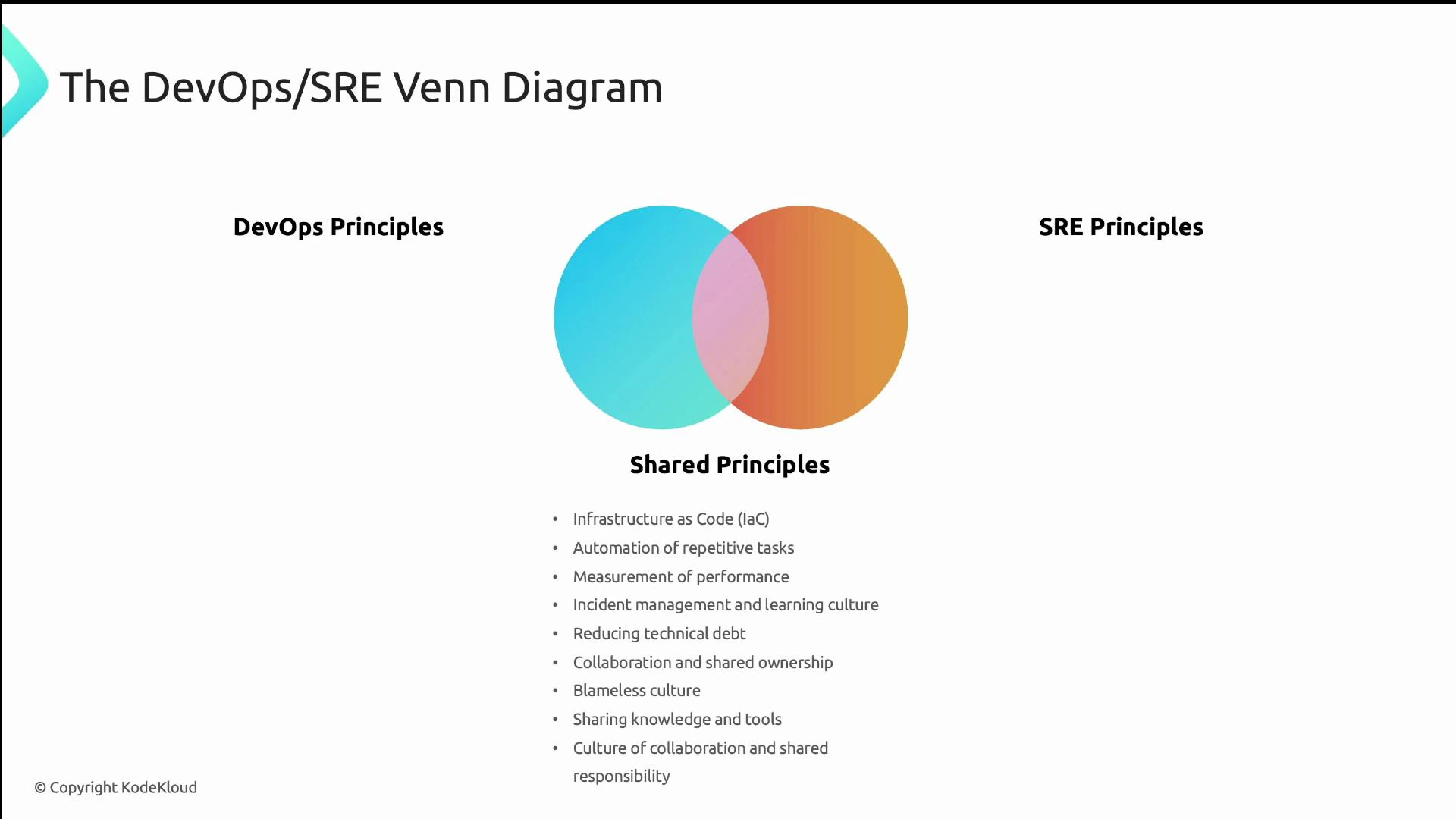
DevOps and SRE share many practices (automation, IaC, observability), but they prioritize different things and use distinct frameworks for operational decision-making. DevOps principles typically emphasize:- Cross-functional teams and reduced silos
- Continuous integration and continuous delivery (CI/CD)
- Shift-left testing and early quality checks
- Lean, product-centric delivery and value-stream thinking
- Continuous improvement of delivery processes
- A culture of shared ownership and collaboration
- Defining reliability using SLIs (Service Level Indicators), SLOs (Service Level Objectives), and SLAs
- Managing error budgets to balance reliability and feature velocity
- Building observability (metrics, logs, traces) rather than only monitoring
- Blameless postmortems and learning from incidents
- Engineering resilience (graceful degradation, automated recovery)
- Embedding reliability-focused engineers (SREs) throughout the delivery lifecycle
| Focus area | DevOps | SRE |
|---|---|---|
| Primary goal | Faster, collaborative software delivery | Measurable reliability through engineering |
| Core artifacts | CI/CD pipelines, IaC, automated tests | SLIs, SLOs, error budgets, runbooks |
| Culture | Shared responsibility across teams | Reliability as a measurable engineering target |
| Approach to failures | Improve processes, speed up feedback | Quantify tolerance with error budgets and automate recovery |
| Typical roles | Cross-functional dev + ops teams | Dedicated or embedded SREs with engineering skills |

How SRE is implemented in organizations
There’s no single canonical SRE model—implementations depend on company size, maturity, technology, and business priorities. Common variations include:- Scale and scope: Large firms often staff dedicated SRE teams for critical services; smaller teams may fold SRE practices into existing product teams without formal SRE roles.
- Organizational structure: Centralized SRE supporting many products; embedded SREs inside product teams; or SREs acting as consultants/advisors.
- Error budget policies: Strict controls (feature freezes) when error budgets run out, or softer governance where exhaustion triggers priority shifts and visibility.
- Tooling and stack: Choices vary by platform—open-source observability tooling, cloud-native managed services, or proprietary stacks.
- On-call practices: Global follow-the-sun rotations, regional hubs, varied rotation lengths, compensation, and escalation rules differ by organization.
- Incident management processes: Escalation paths, runbooks, postmortem formats, and how blamelessness is practiced all vary.
| Variation | Typical choices | Example outcome |
|---|---|---|
| Scale and scope | Dedicated SRE teams vs embedded SRE responsibilities | Dedicated teams for high-criticality services; embedded practices in small orgs |
| Structure | Centralized, embedded, or advisory SRE models | Central SRE provides platform tooling; embedded SREs join product teams |
| Error budget policy | Hard controls vs visibility triggers | Feature rollbacks vs prioritization meetings when budget is low |
| Tooling | OSS stacks, cloud-managed, SaaS observability | Use Prometheus/Grafana, vendor APM, or cloud metrics |
| On-call | Follow-the-sun, regional rotations, compensation models | Reduced burnout and faster regional response with follow-the-sun |
| Incident management | Runbooks, blameless postmortems, RCA cadence | Faster remediation and continuous learning loops |

Real-world examples
Google- Google historically offers engineers a “SRE tour of duty,” where software engineers rotate into SRE teams for six months. This builds operational empathy and hands-on experience with production reliability work. Engineers may return to product teams with improved operational awareness or remain in SRE roles.

- Meta operates a global follow-the-sun on-call rotation. Engineers across North America, Europe, and Asia cover staggered eight-hour windows so no single region regularly handles middle-of-the-night pages. This reduces burnout and improves incident responsiveness across time zones.

Further reading and references
- Google SRE Book: https://sre.google/books/
- Fundamentals of DevOps (course): https://learn.kodekloud.com/user/courses/fundamentals-of-devops
- Kubernetes concepts (for operators and SREs): https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/