
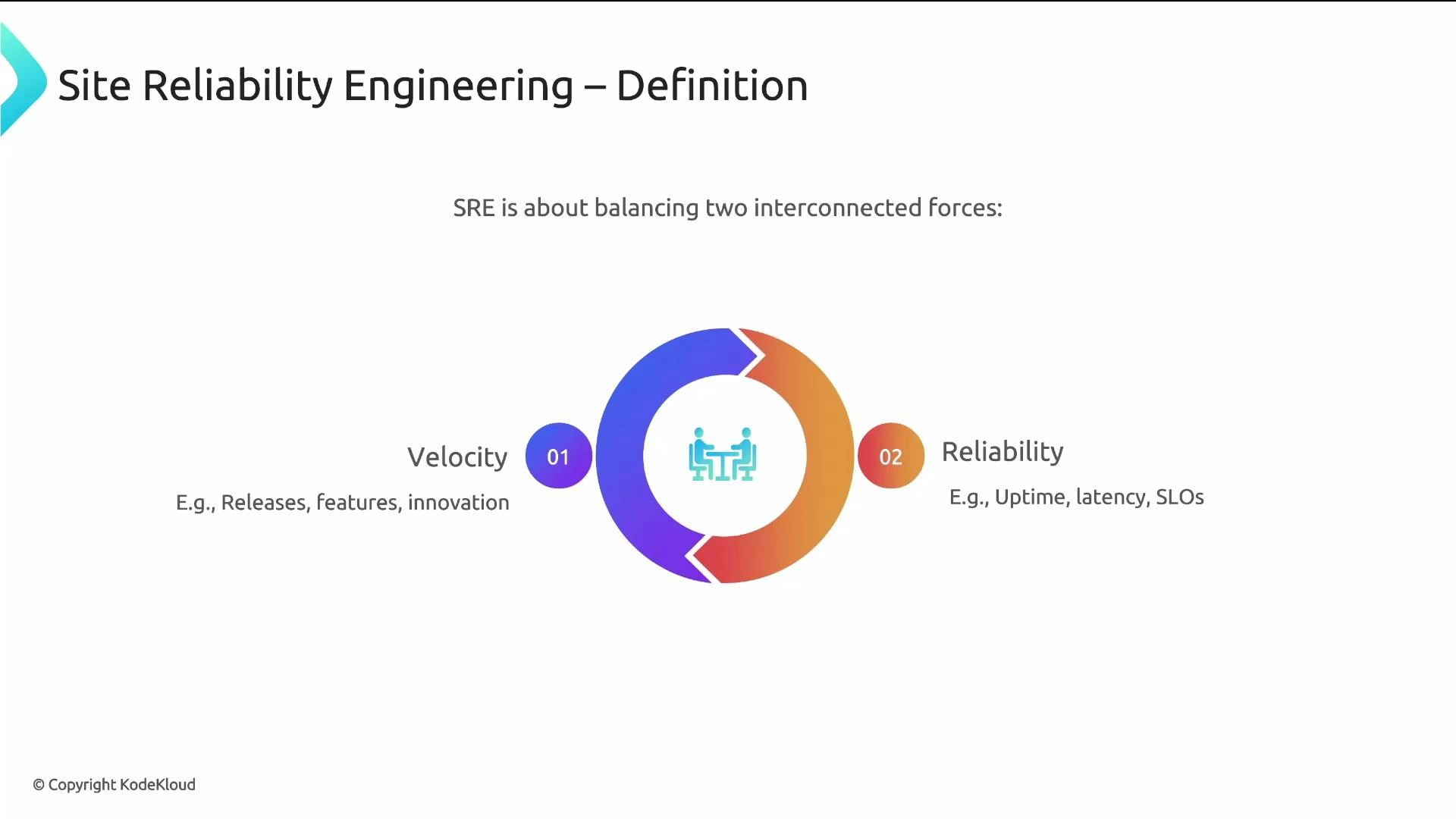
The central tradeoff: velocity vs. reliability
SRE is fundamentally a balancing act between two forces:- Velocity: delivering features, shipping changes, and innovating quickly.
- Reliability: maintaining uptime, acceptable latency, low error rates, and a good user experience.
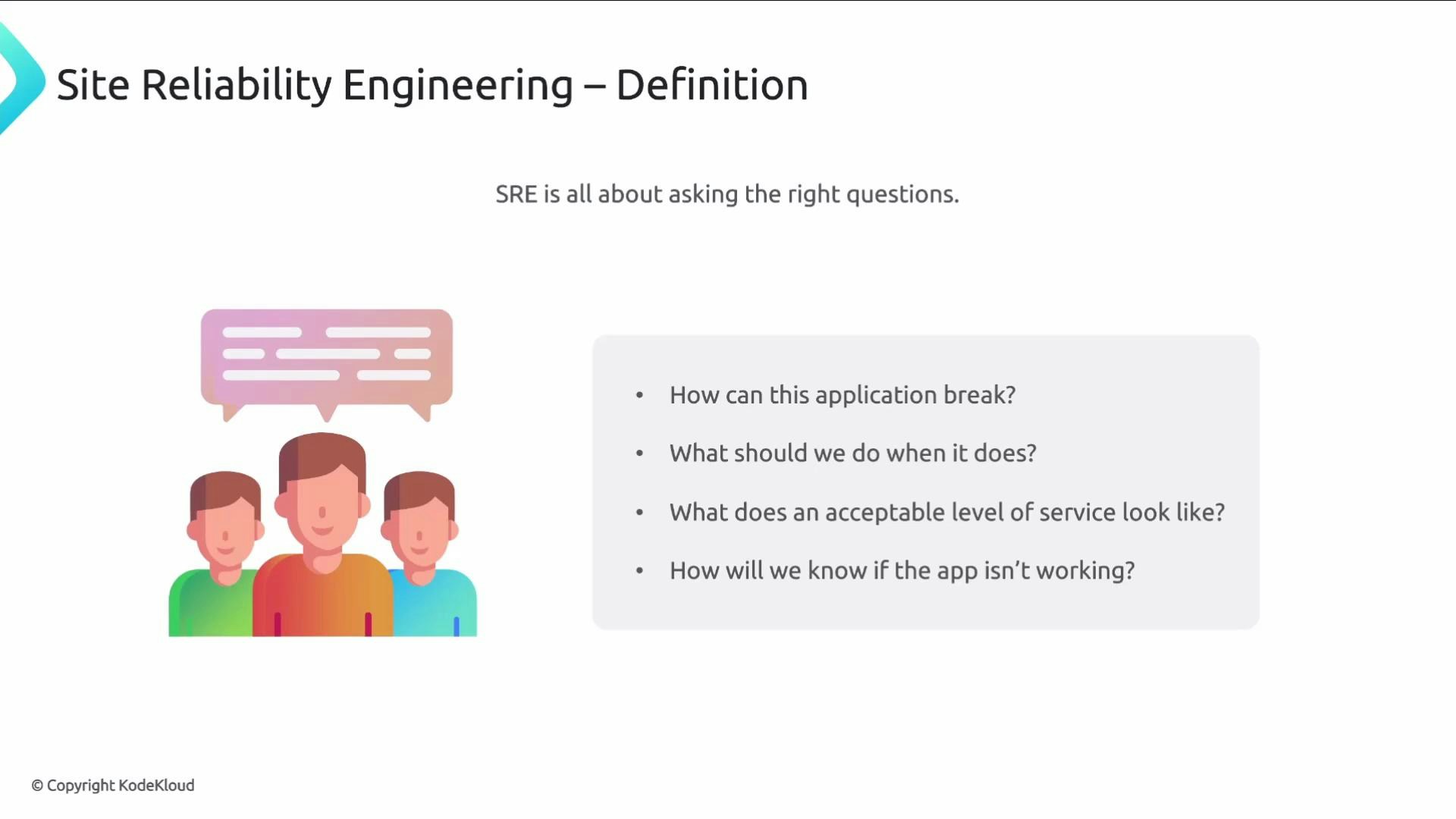
Ask the right operational questions up front
SREs start by anticipating failure modes and documenting responses. Common operational questions include:- How can this application fail?
- What mitigations and runbooks exist?
- What service levels does the business and users require?
- How will we detect, measure, and alert on failures?
Where SRE sits in the organization
SRE bridges traditional IT operations and DevOps practices. It narrows the gap between system design and production behavior by treating operations as an engineering problem: build for failure, measure behavior, automate responses, and continually iterate. Core SRE practices include: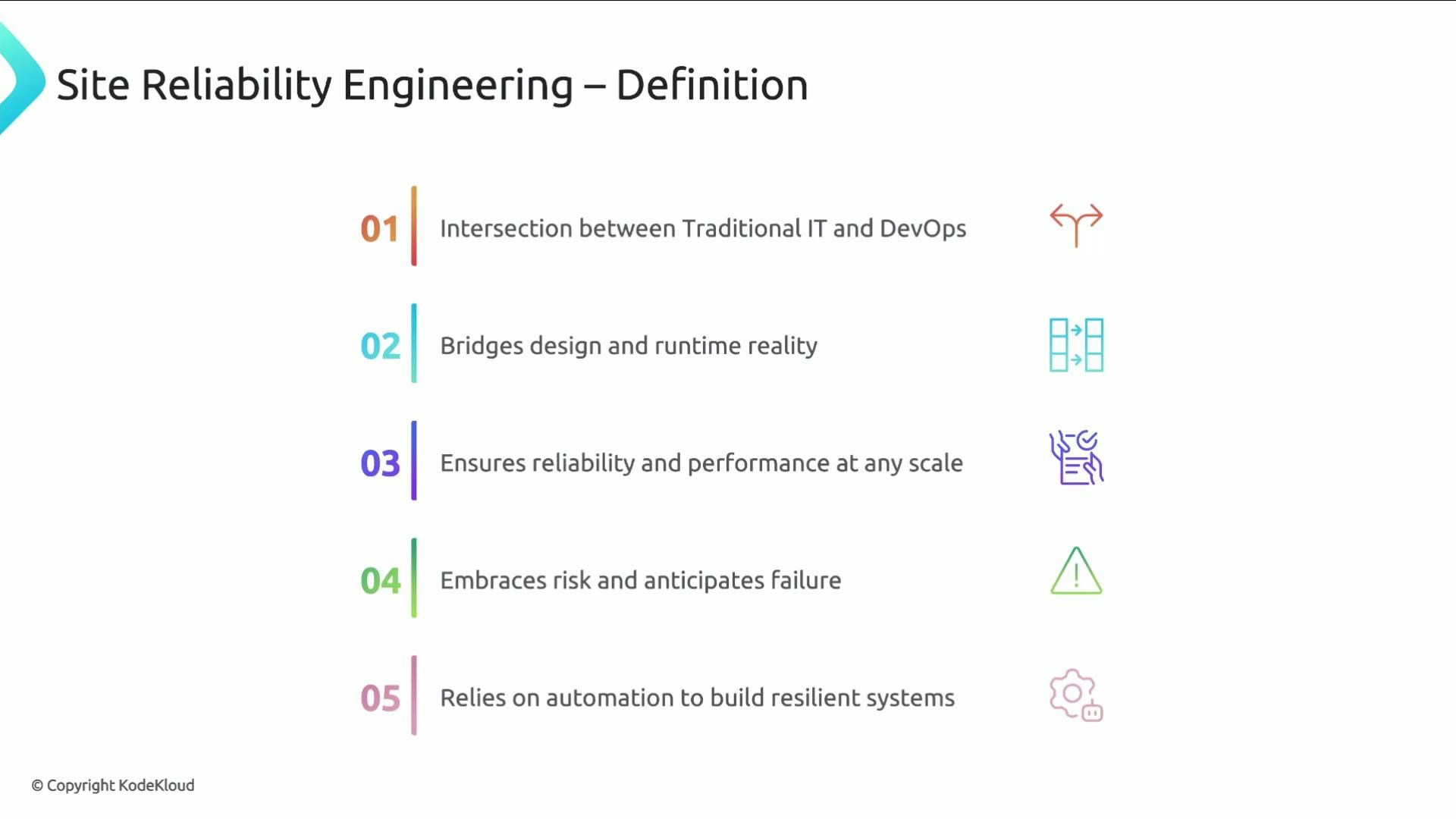
Error budgets are central to SRE risk management: they make reliability a measurable tradeoff, letting teams decide when to prioritize feature velocity versus stability.
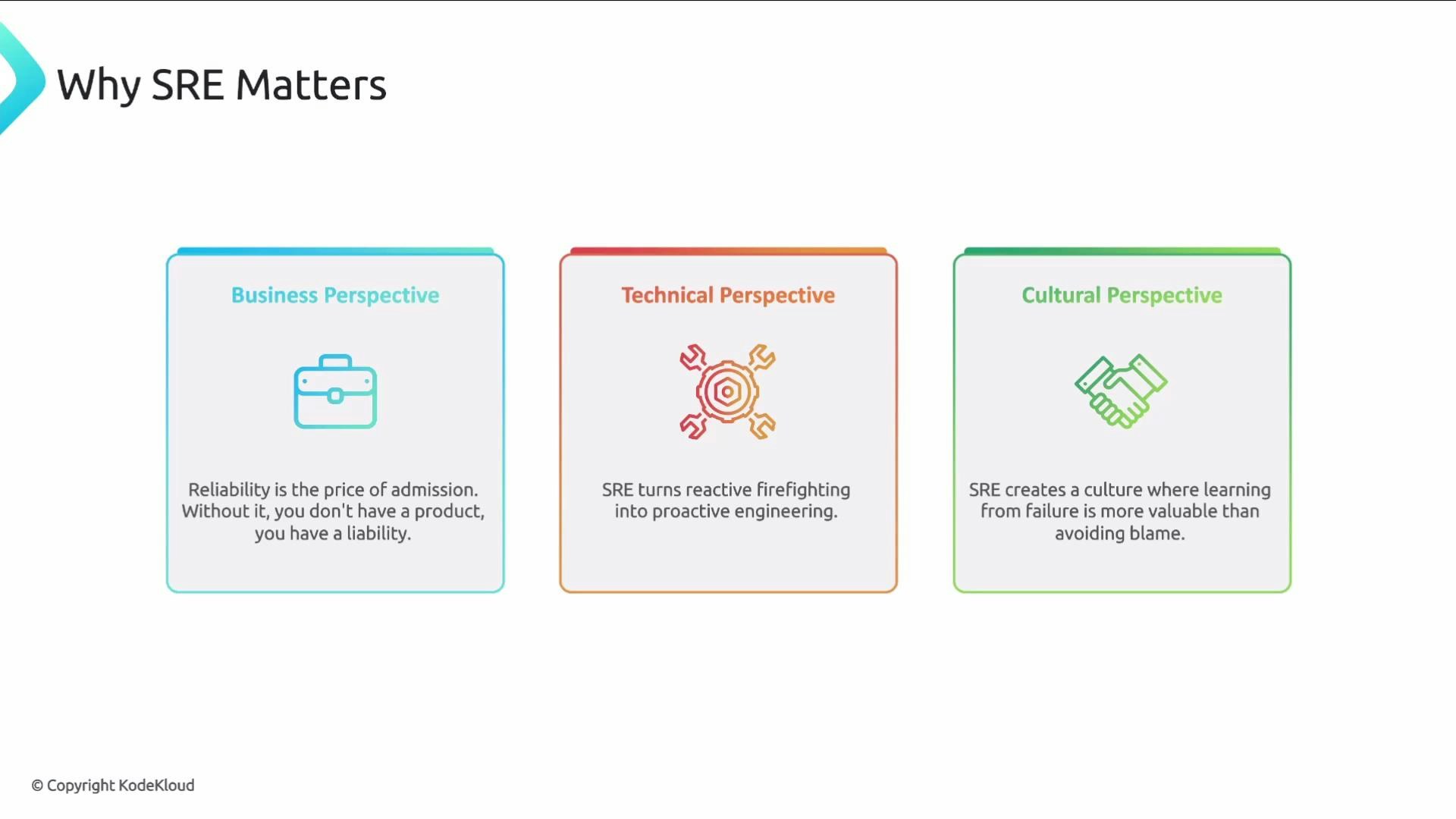
Why SRE matters — three perspectives
- Business: Reliability is a baseline requirement. Users and customers abandon unreliable services, so uptime and performance affect revenue, retention, and reputation.
- Technical: SRE transforms reactive firefighting into proactive engineering — designing systems that fail gracefully and recover automatically.
- Cultural: SRE fosters a blameless learning culture where teams analyze incidents, share knowledge, and continuously improve processes and systems.
Historical context and influential practices
SRE evolved through real-world demands at large-scale companies. Key influences include:- Google: Pioneered SRE as a discipline and popularized SLOs and error budgets.
- Netflix: Advanced chaos engineering and resilience testing to validate system behavior under failure.
- Airbnb and other companies: Demonstrated that SRE principles (automation, observability, cross-team collaboration) apply broadly — not just at hyperscale.

Summary
SRE is a pragmatic engineering discipline that balances speed and stability. It emphasizes anticipating failure, measuring what matters, automating toil, and learning continuously through blameless processes. Applying SRE practices helps teams ship faster with predictable risk and recover more quickly when things go wrong. In the next lesson we’ll dive deeper into specific SRE practices and tools — including how to define SLIs/SLOs, structure error budgets, and implement observability and automation in production systems.Links and references
- Site Reliability Engineering: How Google Runs Production Systems (book)
- Google SRE resources
- Chaos Engineering principles (Netflix-inspired)
- Observability vs Monitoring
- Kubernetes documentation (deploy and observe cloud-native systems)