At real-world scale, 100% uptime is infeasible. Trying to guarantee it leads to unsustainable costs, brittle systems, and slow innovation. SLOs help teams balance reliability, cost, and speed by defining realistic, measurable targets.
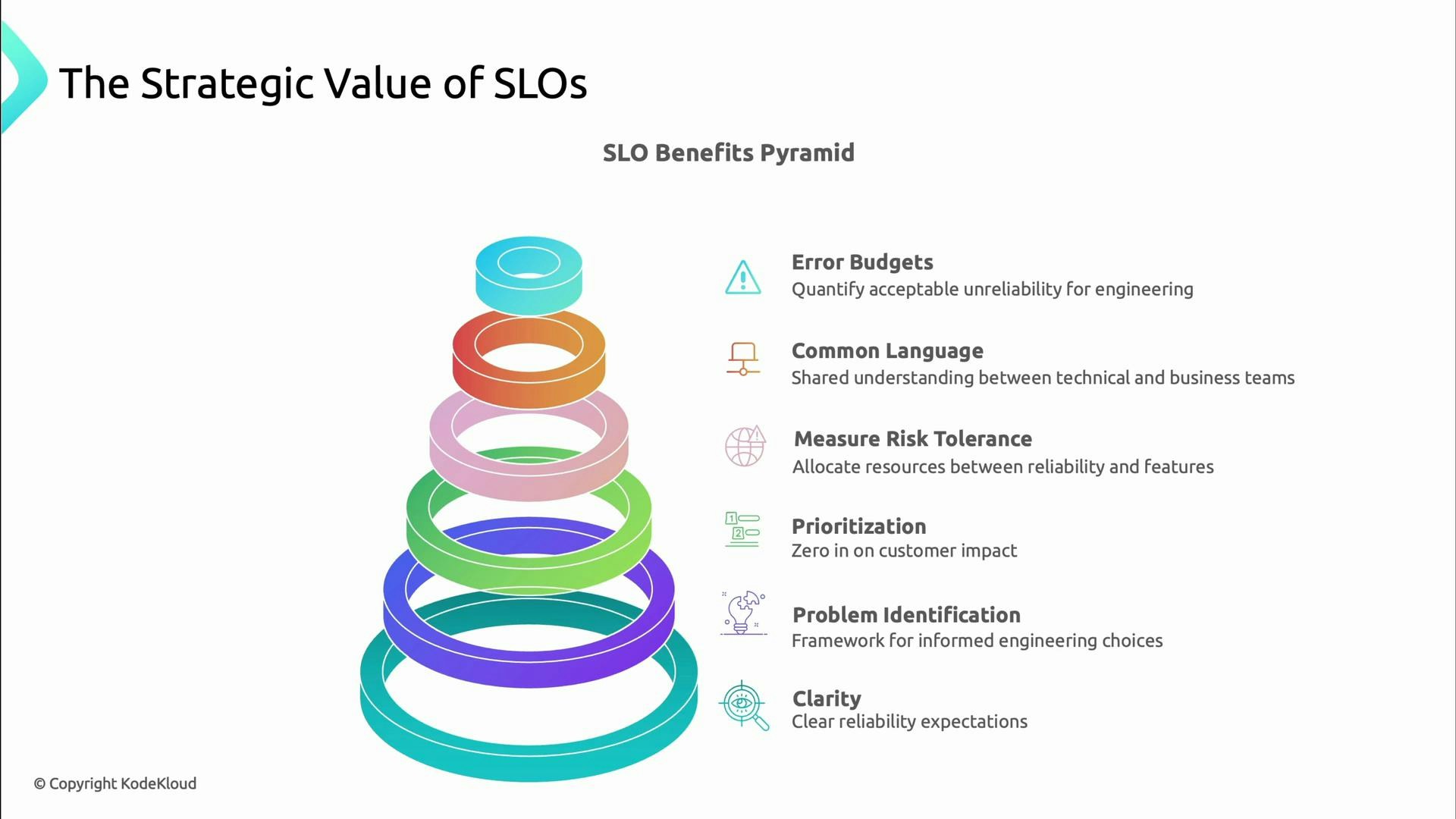
- Quantify acceptable unreliability (error budgets).
- Create a shared language across engineering and business stakeholders.
- Prioritize engineering effort and operational investment according to business risk.
- Surface the incidents that matter most to users.
- Make reliability visible, measurable, and actionable across the organization.
- Which user journeys are critical?
- What does “good enough” look like for those journeys (latency, availability, correctness)?
- What trade-offs between cost and reliability are acceptable?
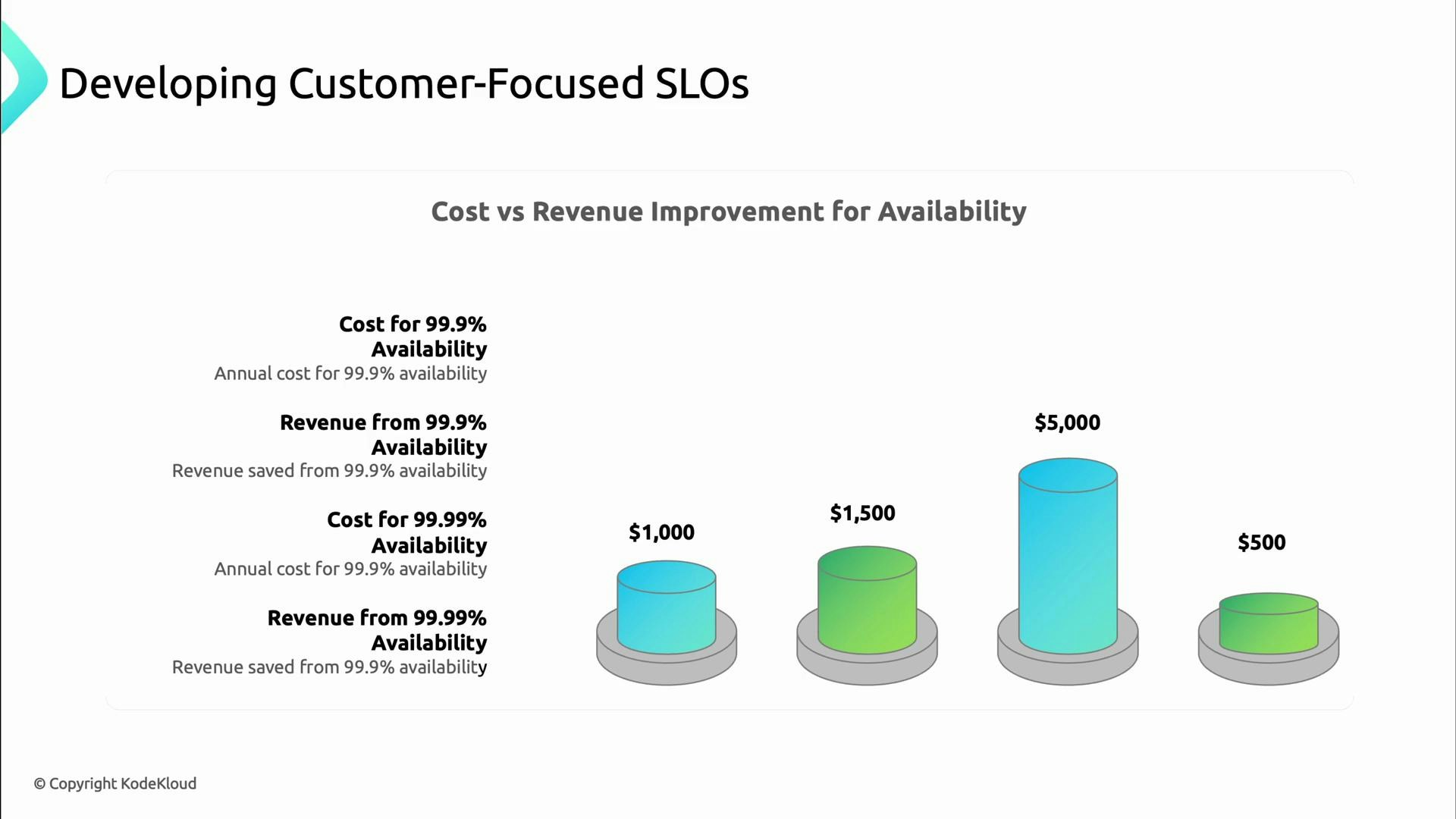
- Revenue: how do downtime and slow responses affect conversions and sales?
- Costs: what operational or engineering investments are required at each reliability level?
- Competitive position: what reliability levels do competitors promise?
- Brand perception: how does reliability affect trust and retention?

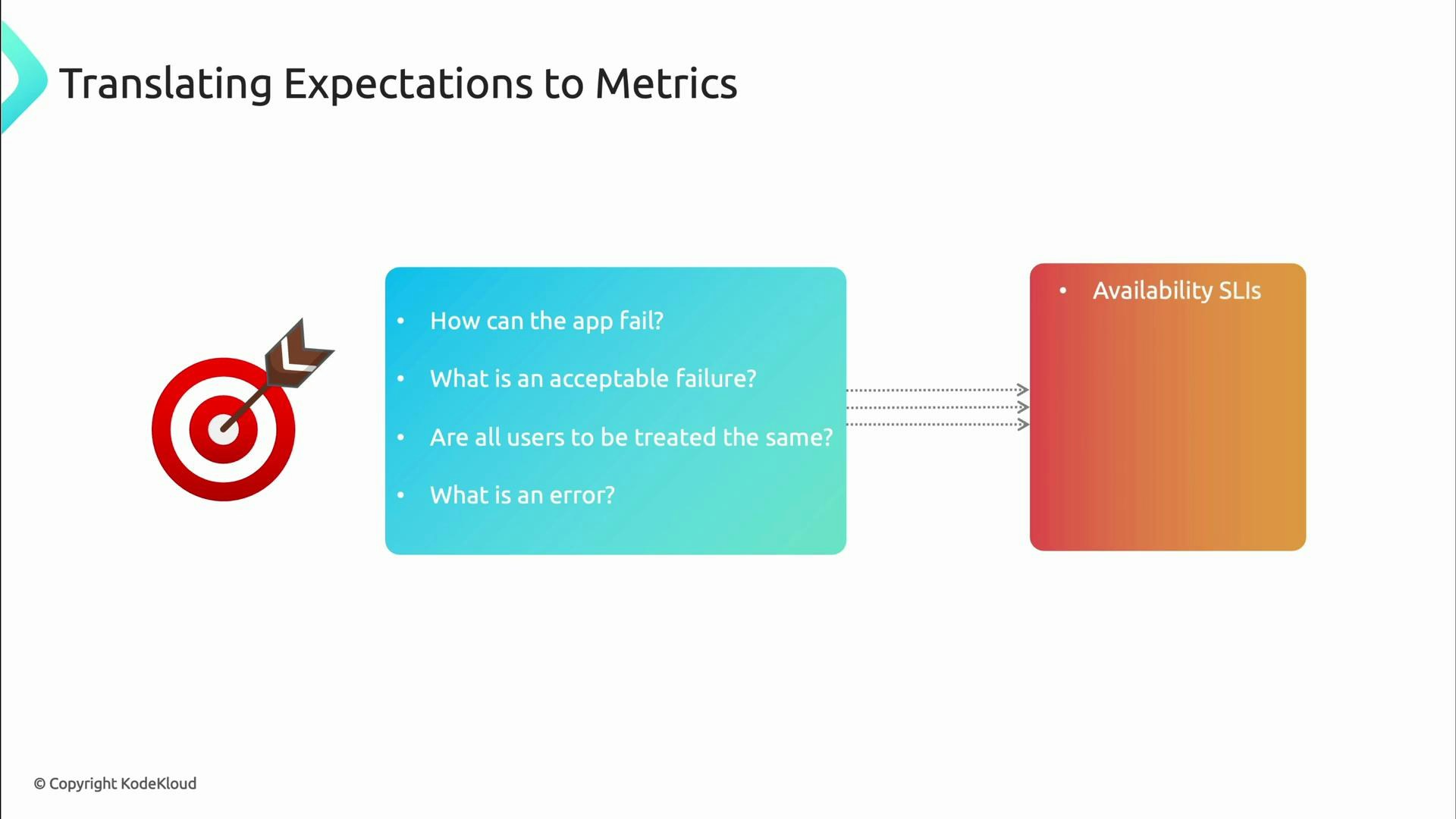
- How can this app fail?
- Which failures are acceptable for the user experience?
- Are different user segments treated differently?
- What counts as an error?
Map SLI measurements to SLO statements that are understandable by product and business teams.
Example: KodeKloud record store (search and orders)
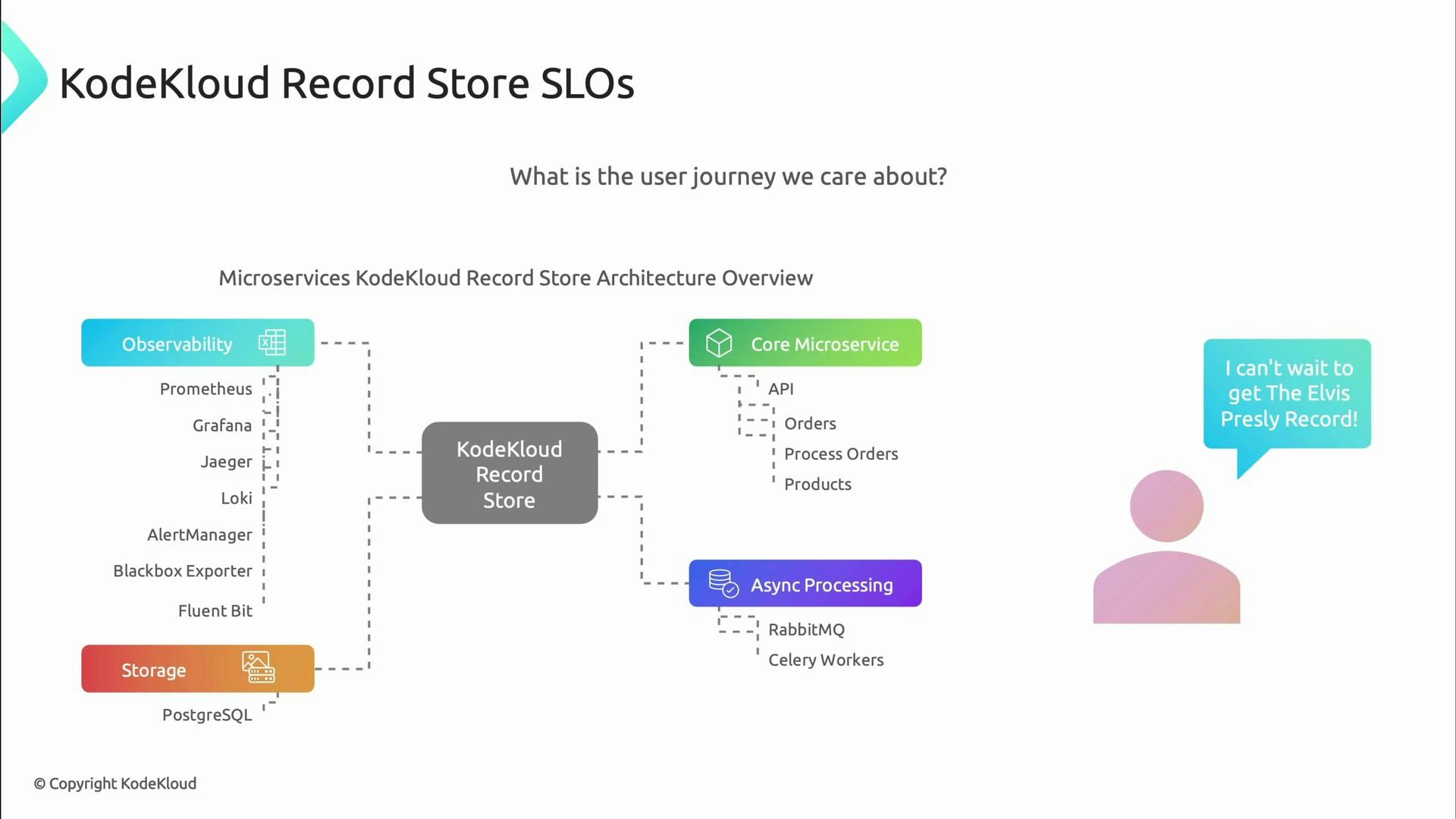
- Availability SLO: 99.9% of API requests succeed (catalog API).
- Latency SLO: 99% of search queries complete within 300 ms.
- SLIs: processing success rate, end-to-end order processing latency.
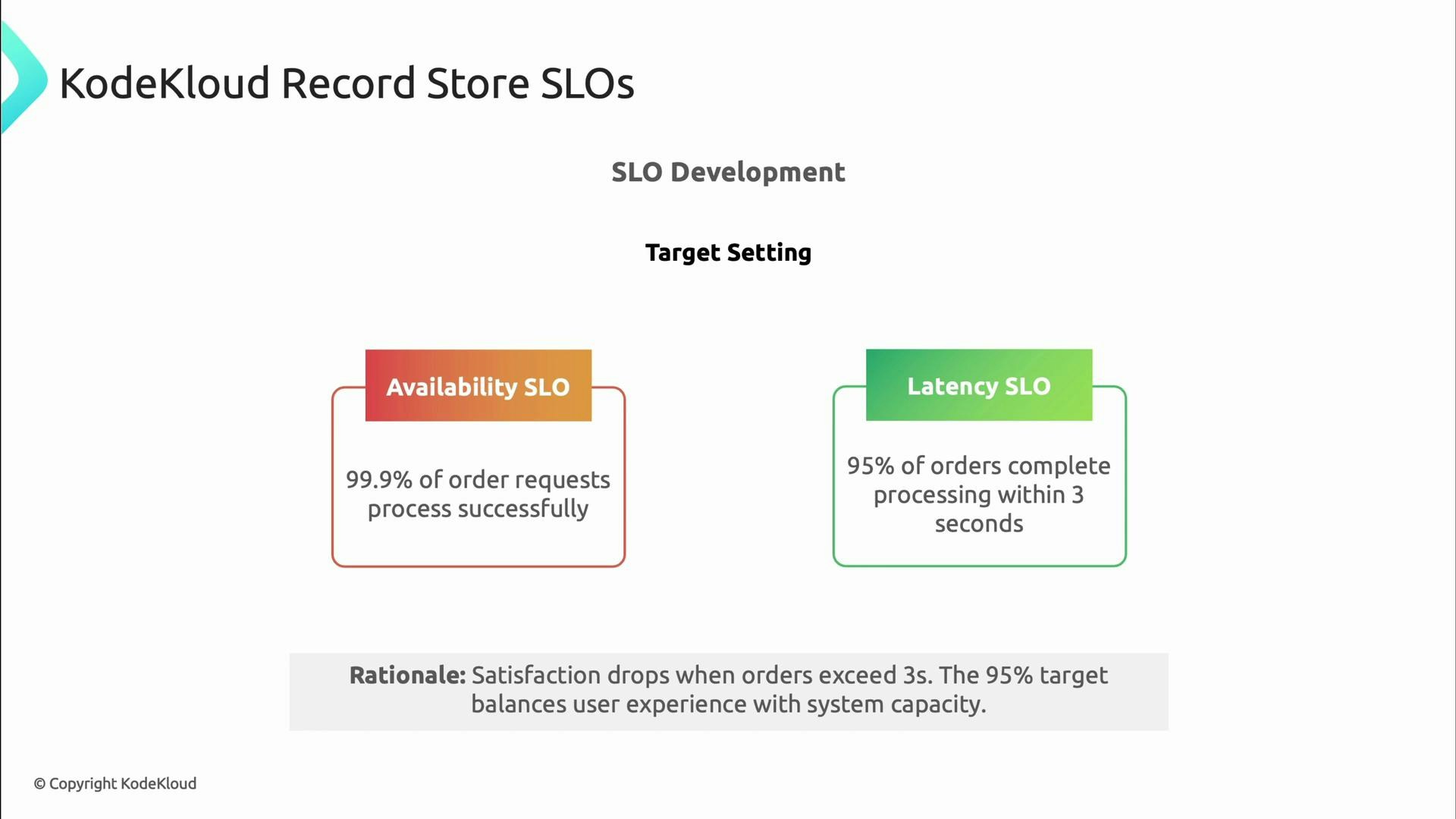
- SLO (availability/orders): 99.9% of order requests process successfully.
- SLO (latency/orders): 95% of orders complete processing within 3 seconds.

Always record the rationale and assumptions for every SLO. This documentation enables future teams to understand why targets were chosen and how to adjust them over time.
- Start with data-driven, educated estimates (benchmarks, architecture, stakeholder input).
- Record assumptions and measurement methods.
- Analyze actual performance during reviews: SLO adherence, trends, and patterns.
- Combine quantitative metrics with qualitative feedback (customer surveys, stakeholder concerns).
- Reassess business risk and operational cost (alert noise, toil).
- Adjust SLOs and error-budget policies based on evidence.
- Critical customer-facing systems (payments, authentication): very strict SLOs (e.g., 99.99%).
- Content delivery and public APIs: high availability but tuned to cost-impact.
- Internal tools and background jobs: more lenient SLOs, optimized for cost and throughput.
- If the error budget is healthy, teams can safely ship features and experiments.
- If the error budget is depleted, the team focuses on reliability work until the budget is replenished.
- Identify critical user journeys.
- Define SLIs with precise measurement methods.
- Set SLOs based on business impact and historical data.
- Document rationale, assumptions, and measurement details.
- Implement monitoring, dashboards, and alerting tied to SLOs and error budgets.
- Review and iterate SLOs regularly with business stakeholders.
- Google SRE Book — Service Level Objectives
- Prometheus — Monitoring system & time series database
- Site Reliability Engineering (SRE) — Principles and Practices
- SLO Playbooks and Guides — Practical SLO design
- How to measure latency percentiles and why p95/p99 matter for UX.
- Error budgets: policy templates and runbooks.
- Prometheus query examples for SLIs and SLO dashboards.