- Complex systems rarely fail from a single cause — incidents usually have multiple contributing factors.
- Human error is typically a symptom, not the fundamental root cause; it often exposes gaps in tooling, processes, or design.
- RCA isn’t only for large outages; small incidents offer high‑value learning opportunities.
- The aim of RCA is system improvement and prevention, not assigning blame.

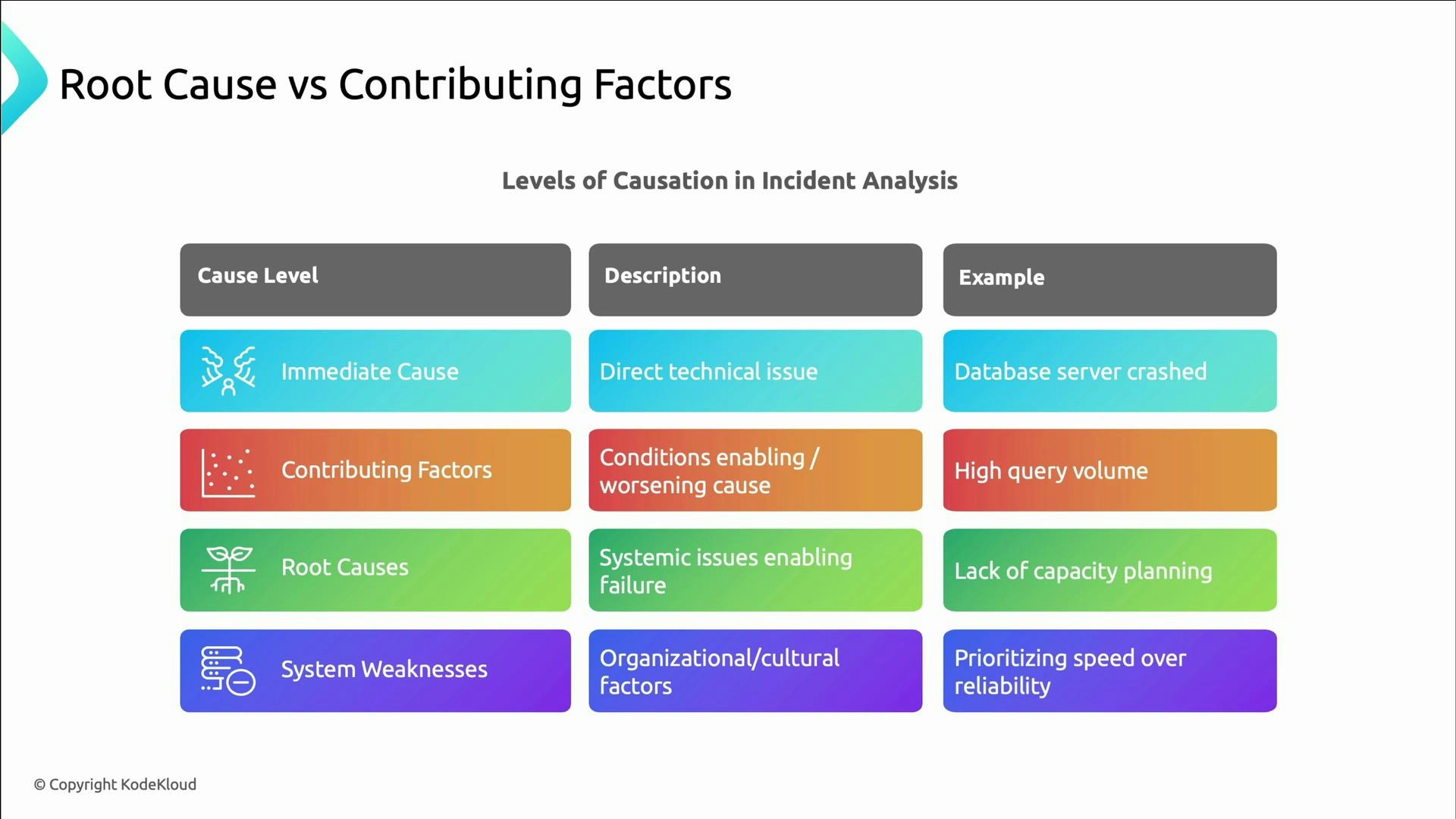
- Root cause: the underlying reason the incident occurred (e.g., a faulty configuration or missing safeguard).
- Contributing factors: conditions that amplified impact or delayed recovery (e.g., insufficient alerts or overloaded queues).
- Immediate cause: the direct technical failure (e.g., the database server crashed).
- Contributing factors: conditions that worsened the outcome (e.g., sudden spike in traffic).
- Root causes: systemic gaps that permitted the failure (e.g., lack of capacity planning).
- System weaknesses: cultural or organizational patterns (e.g., prioritizing speed over reliability).
- While debugging a billing system, an engineer accidentally removed more capacity than intended.
- That capacity supported S3’s index and placement systems — core to S3 operations.
- Restarting those subsystems at scale caused a cascading failure and a multi‑hour outage in US‑East‑1.

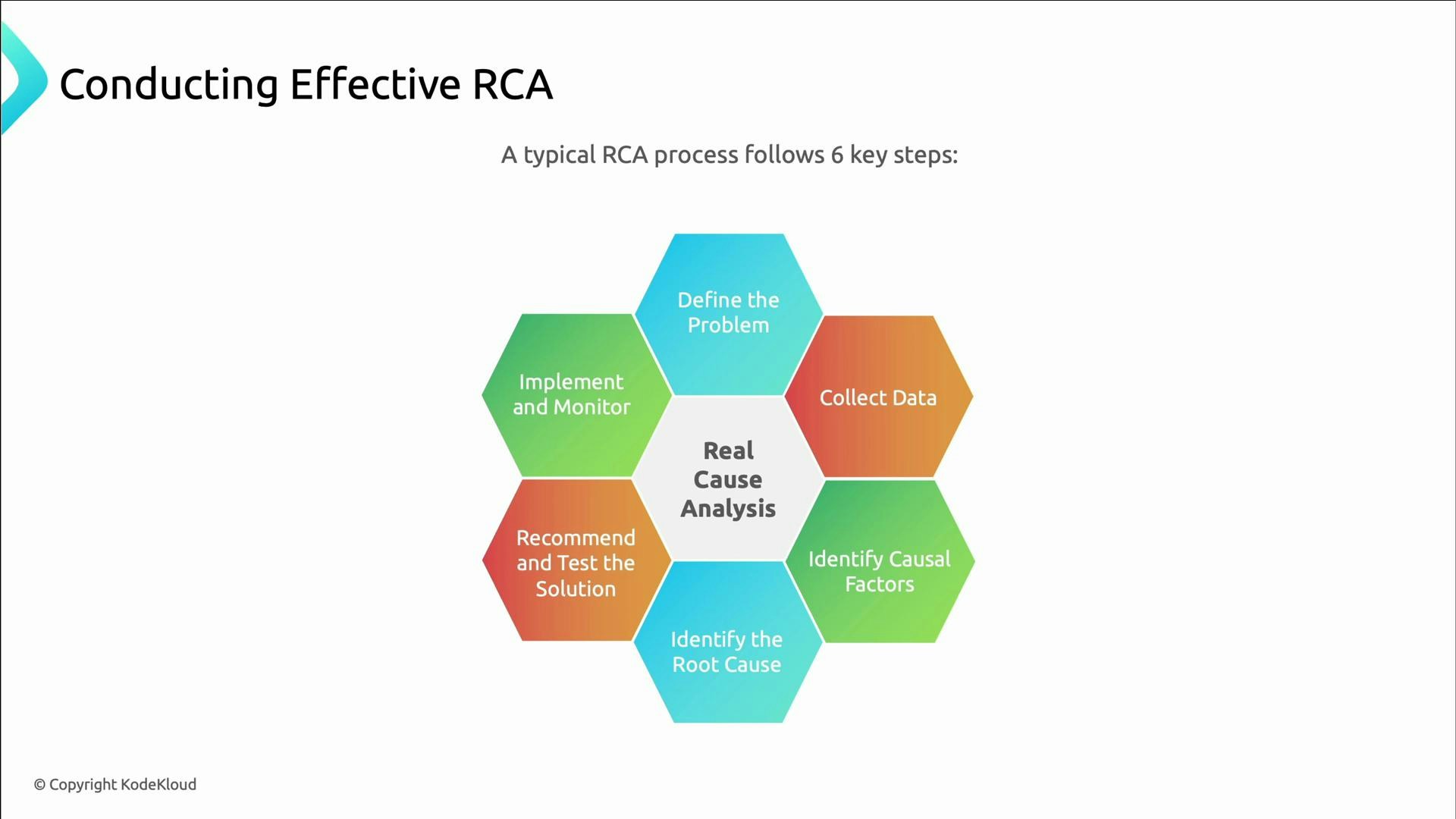
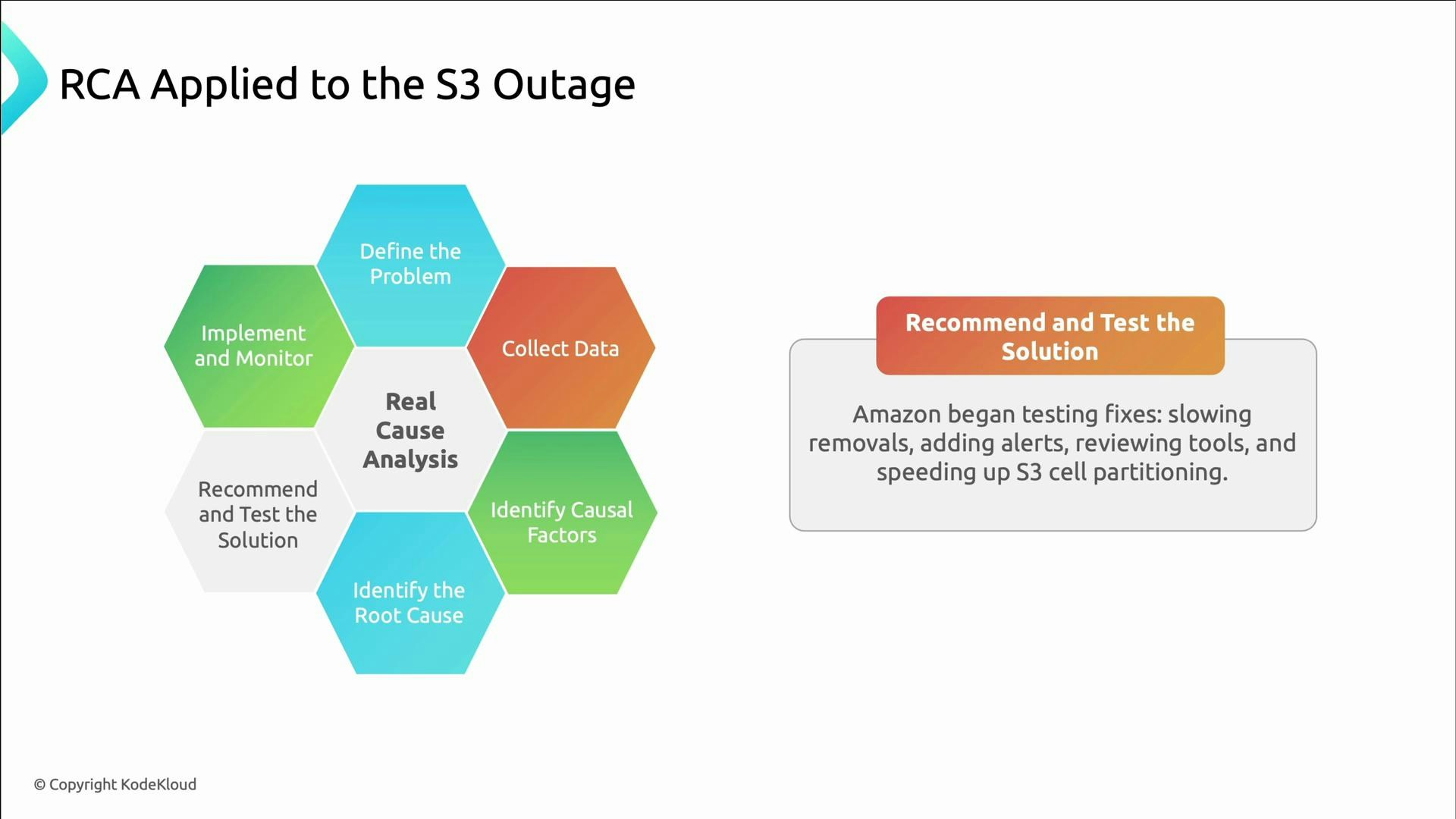
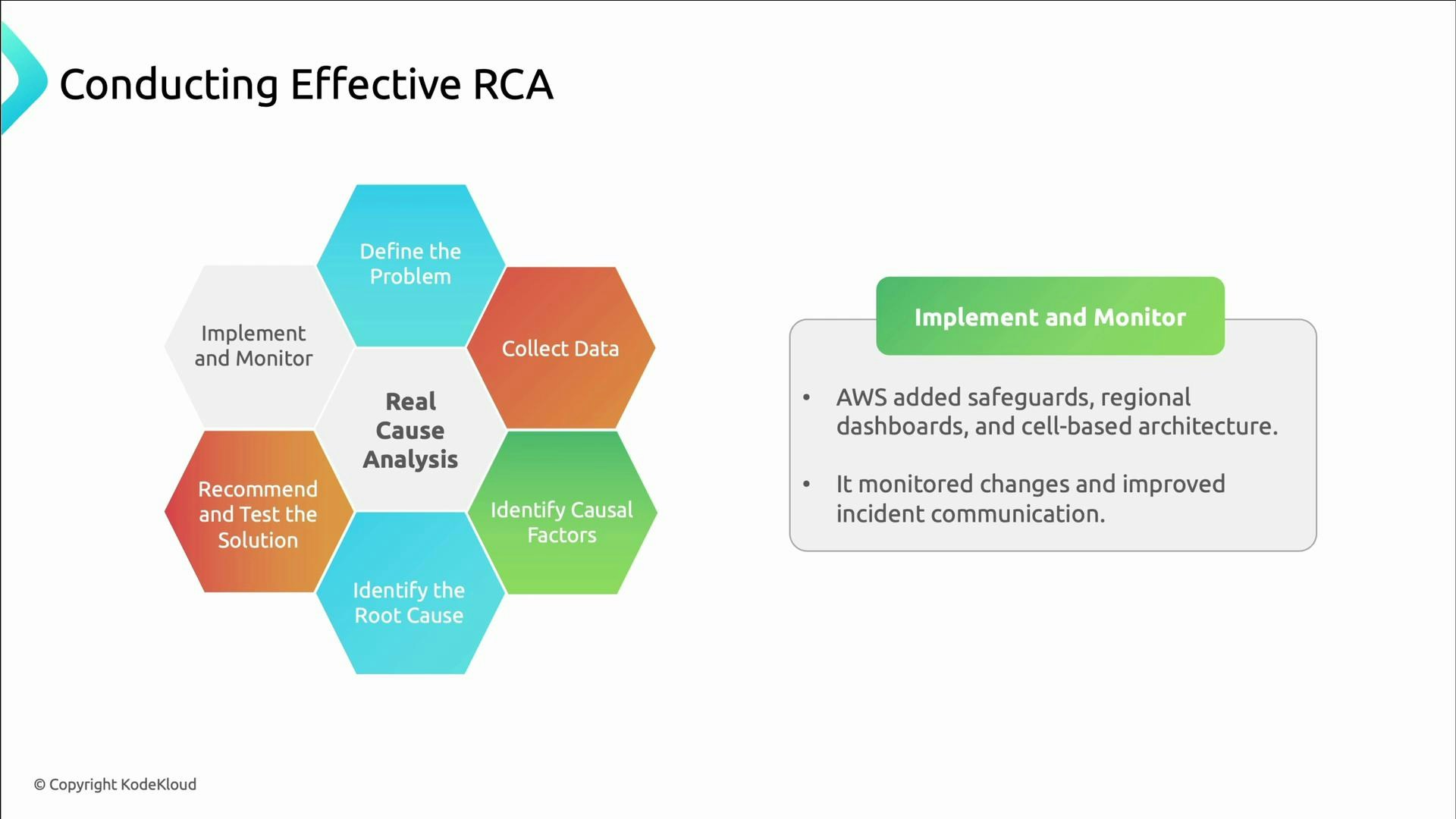
- Define the problem clearly.
- Collect relevant data.
- Identify causal factors.
- Determine the root causes.
- Recommend and test solutions.
- Implement solutions and monitor results.
- Define the problem: In US‑East‑1, S3 failed to service GET/PUT/LIST operations, disrupting many AWS services for hours.
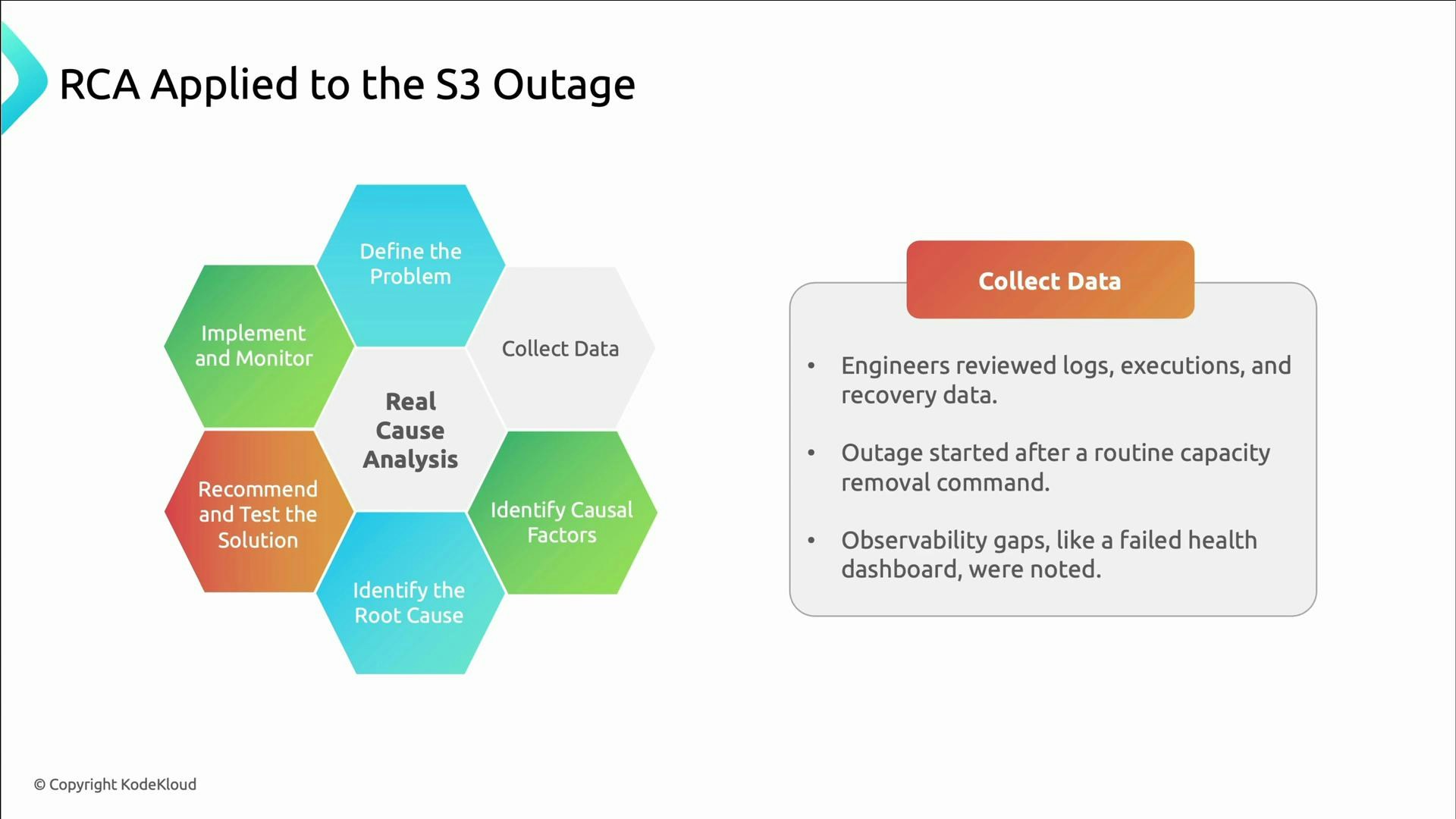
- Collect data: Engineers reviewed logs, execution histories, and recovery timelines; they traced the outage to a routine capacity-removal command and found observability gaps (the S3 dashboard also failed).
- Identify causal factors: Too many servers were removed at once, and safeguards that would limit impact were missing.
- Determine root causes and recommend fixes (examples follow), test mitigations, then deploy changes and monitor outcomes.
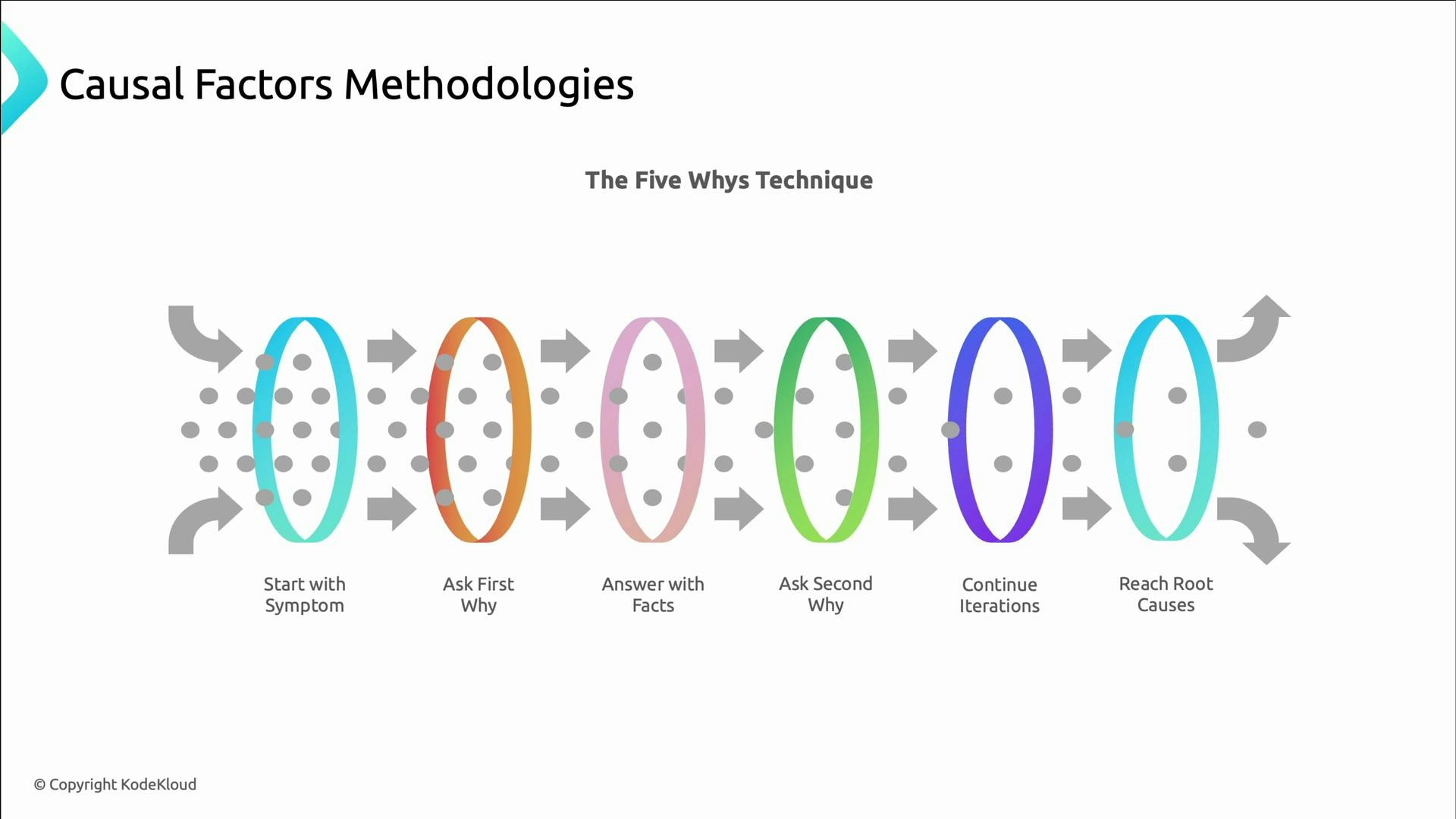
- Five Whys: repeatedly ask “why” to move from symptom to deeper causes. The goal is to reach actionable root causes; the number five is a guideline, not a rule.
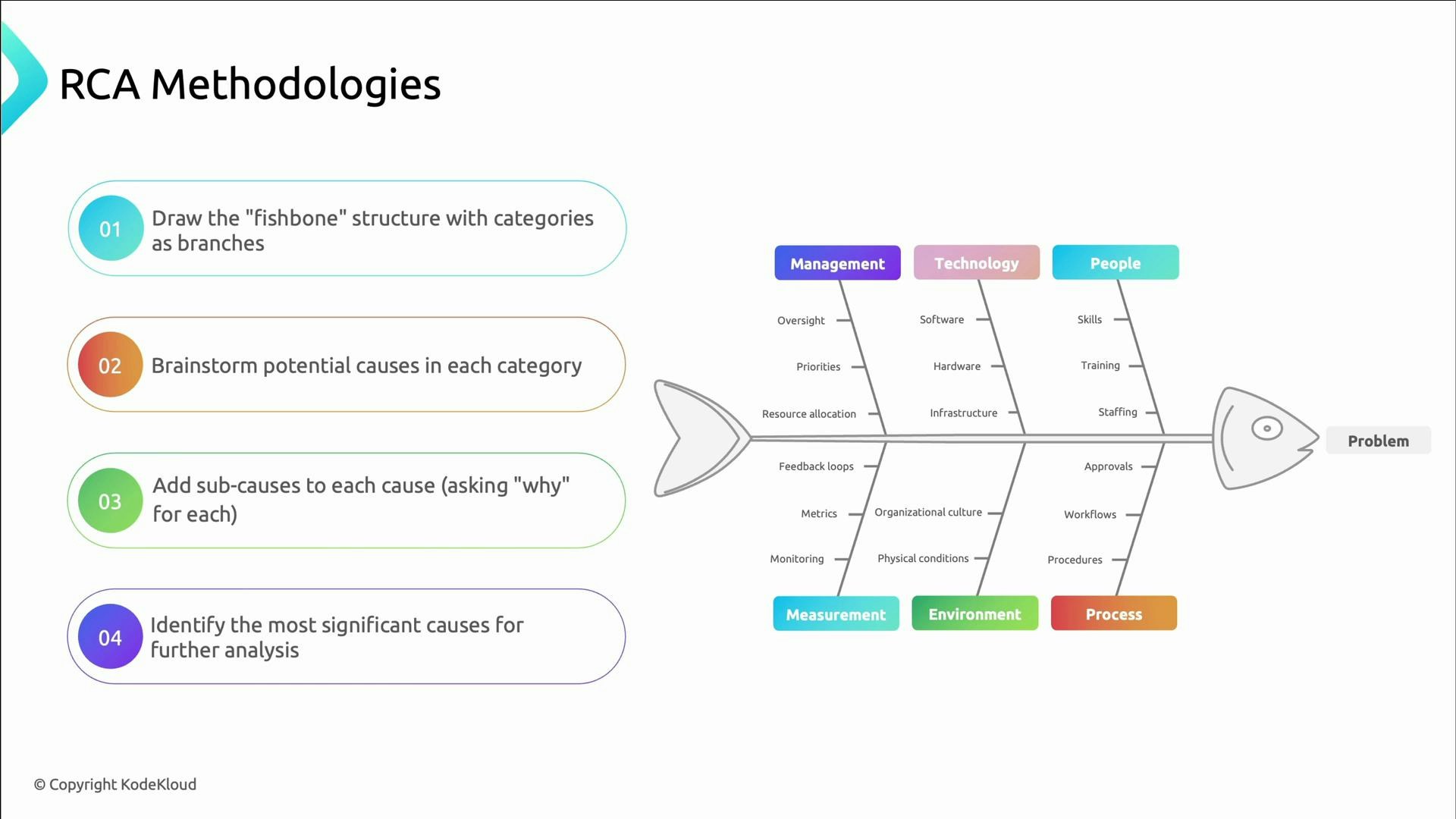
- Fishbone (Ishikawa) diagrams: structure brainstorming into categories (People, Process, Tools/Technology, Environment, Measurement) to avoid tunnel vision and ensure broad analysis.
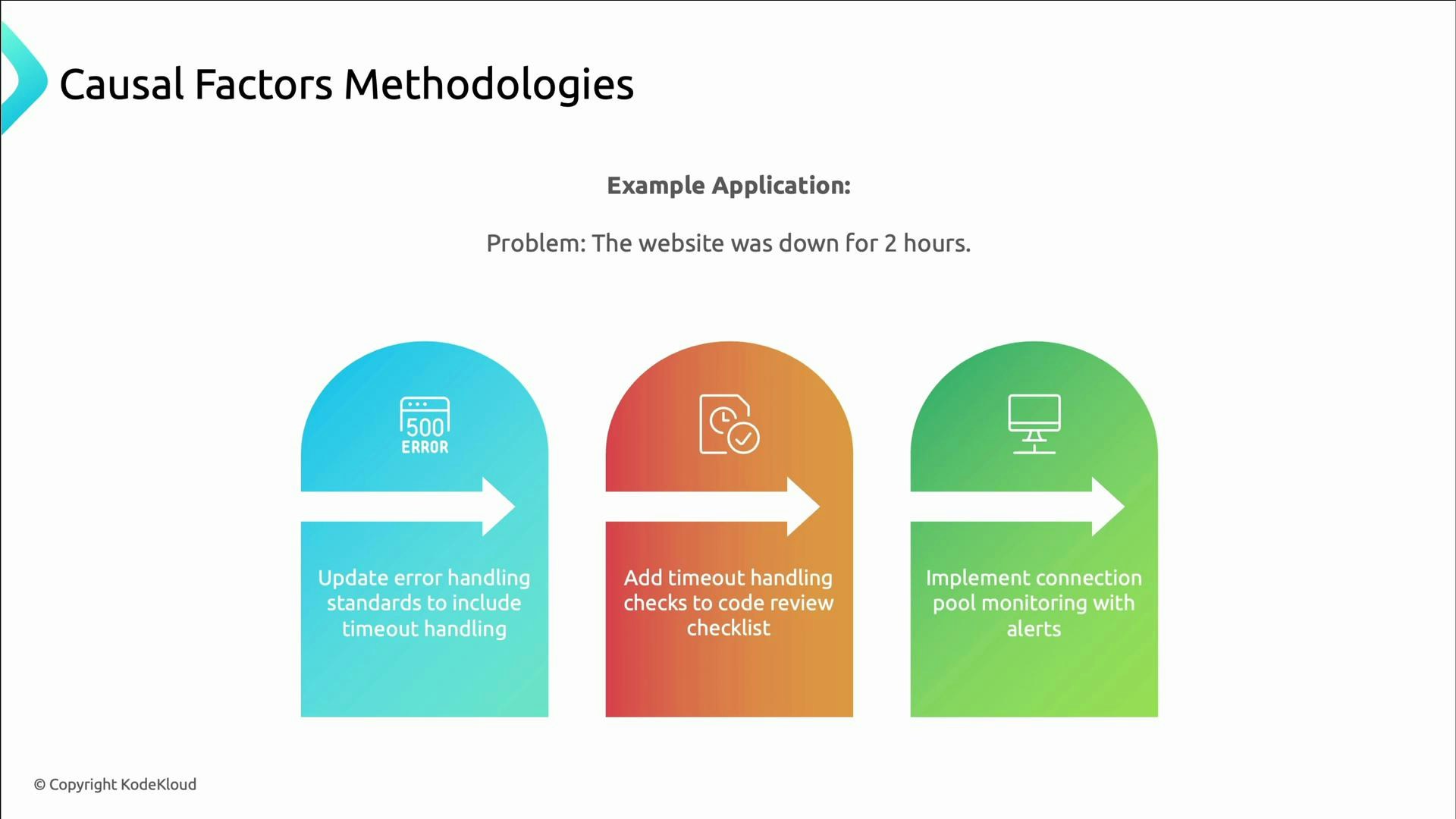
- Symptom: Website down for two hours.
- Why 1: Database server ran out of connections.
- Why 2: Too many connections were created and not closed.
- Why 3: The connection pooling mechanism failed.
- Why 4: Timeouts weren’t properly handled in the codebase.
- Why 5: No coding standards for timeout handling and code reviews didn’t check for them.

Good RCAs produce actionable, testable recommendations — not vague platitudes. Each action should measurably reduce either the probability or the impact of the failure mode you identified.
- Update error-handling standards to include timeouts.
- Add timeout checks to the code-review checklist.
- Implement connection-pool monitoring with alerts.
- Use main branches such as People, Process, Technology, Environment, and Measurement.
- Brainstorm causes under each branch, keep asking why to reveal sub-causes, then prioritize the most significant contributors for investigation and mitigation.

Avoid vague, unverifiable action items. Without an owner, deadline, and success criteria, an action item will likely never produce measurable improvement.
- Deploy mitigations, then measure their effectiveness using new or updated observability.
- Iterate: if a mitigation doesn’t reduce risk as expected, revisit the causal analysis and refine the solution.
- AWS’s follow-up to the S3 outage included rolling out safeguards, distributing the health dashboard across regions, adopting cell partitioning, and improving incident communication — changes that reduced the chance and impact of repeat failures.
- Technical patterns: insufficient monitoring, poor capacity planning, missing error handling, silent failures, cascading dependencies without safeguards.
- Process patterns: inadequate testing of failure modes, unclear service ownership, inconsistent deployment procedures, missing or outdated runbooks, and weak knowledge transfer.
- Organizational patterns: prioritizing features over reliability, rushed onboarding, siloed teams, time pressure that accumulates technical debt, and normalizing warning signs.

- AWS summary of the S3 Feb 2017 outage postmortem.
- Intro to Root Cause Analysis and post-incident processes: Google SRE book — Postmortem Culture.