
What is toil?
- In SRE, toil is manual, repetitive operational work that provides no enduring value and tends to increase linearly as a system scales.
- Toil consumes engineer time and energy without improving the system. Without deliberate automation or design changes, toil grows with the service.
Common signs that work is toil
Look for these characteristics to determine whether a task is toil:- Requires direct human involvement to execute.
- Repetitive tasks that could be automated.
- No cumulative value — doing it again tomorrow yields the same result.
- Triggered repeatedly by the same conditions or occurs on a schedule.
- Tactical focus: addresses symptoms rather than root causes.
- Workload grows proportionally with the service.
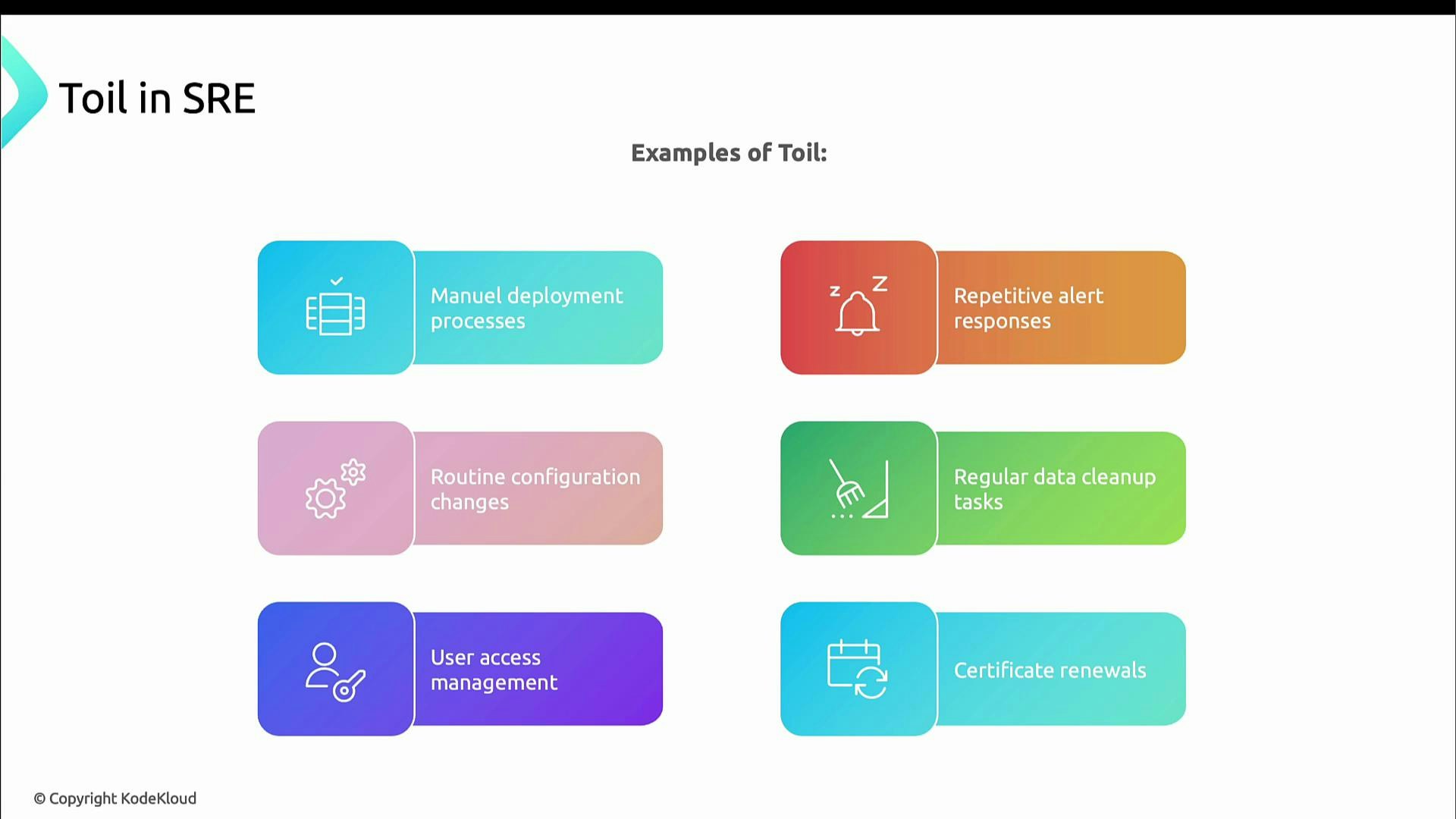
Concrete examples
- Manual deployment processes with many manual steps or frequent interventions.
- Repetitive alert responses where incidents require the same manual actions.
- Routine configuration changes performed by hand.
- Regular data cleanup tasks conducted manually.
- User access management without self-service tooling.
- Certificate renewals that are not automated.
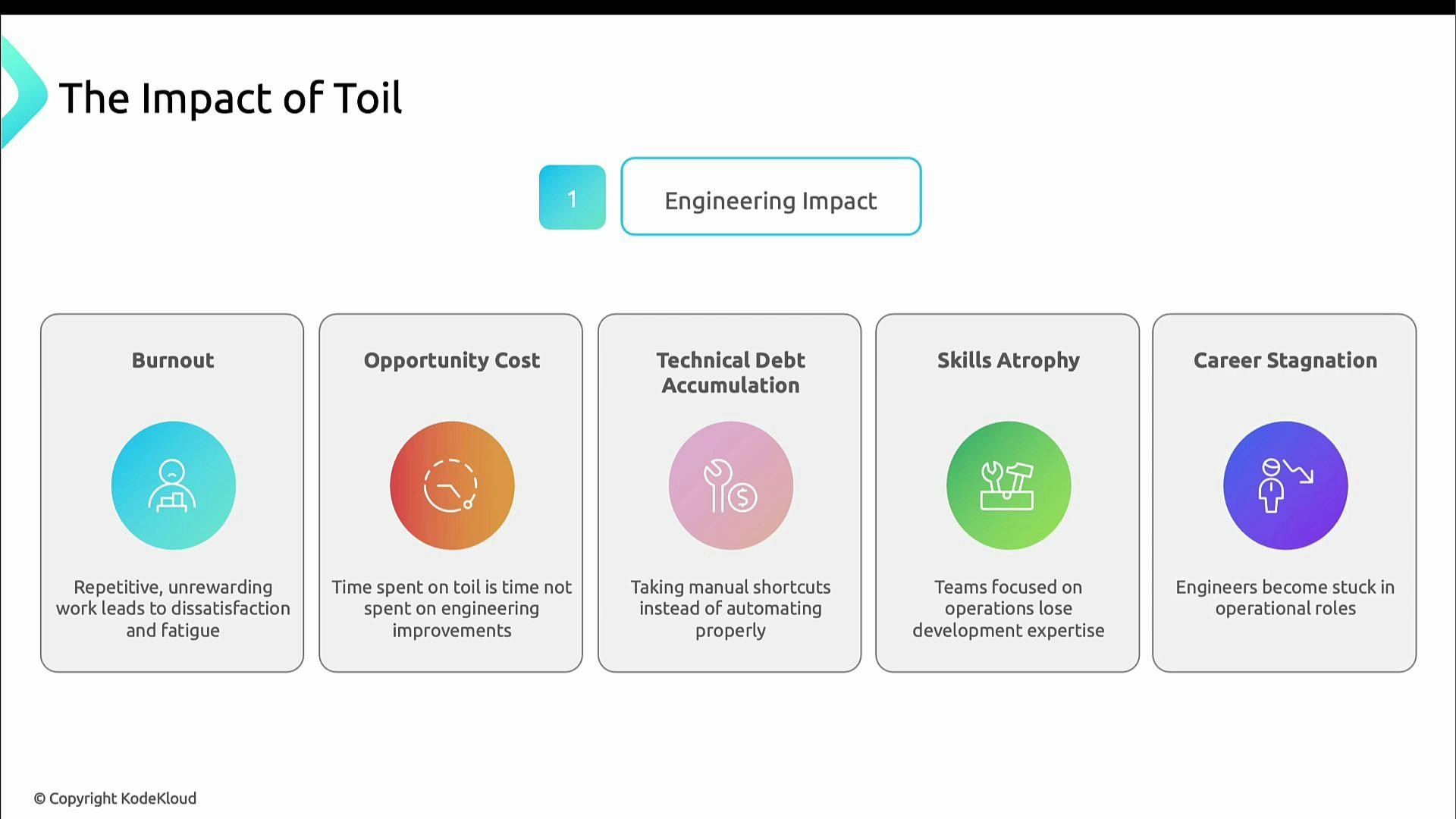
Impact of toil
Toil affects engineering teams, business outcomes, and long-term competitiveness.Engineering impacts
- Burnout: Repetitive, unrewarding work leads to fatigue and lower morale.
- Opportunity cost: Time spent on toil is time not spent building improvements.
- Technical debt: Short-term manual fixes accumulate as long-term cruft.
- Skills atrophy: Teams focused on firefighting lose practice in development and design.
- Career stagnation: Engineers trapped in operational routines miss growth opportunities.
Business impacts
- Slower time to market: Manual processes create bottlenecks.
- Higher operational costs: More headcount required as systems grow.
- Reduced reliability: Human steps are error-prone.
- Scaling limitations: Manual operations do not scale effectively.
- Competitive disadvantage: Teams burdened by toil innovate more slowly.

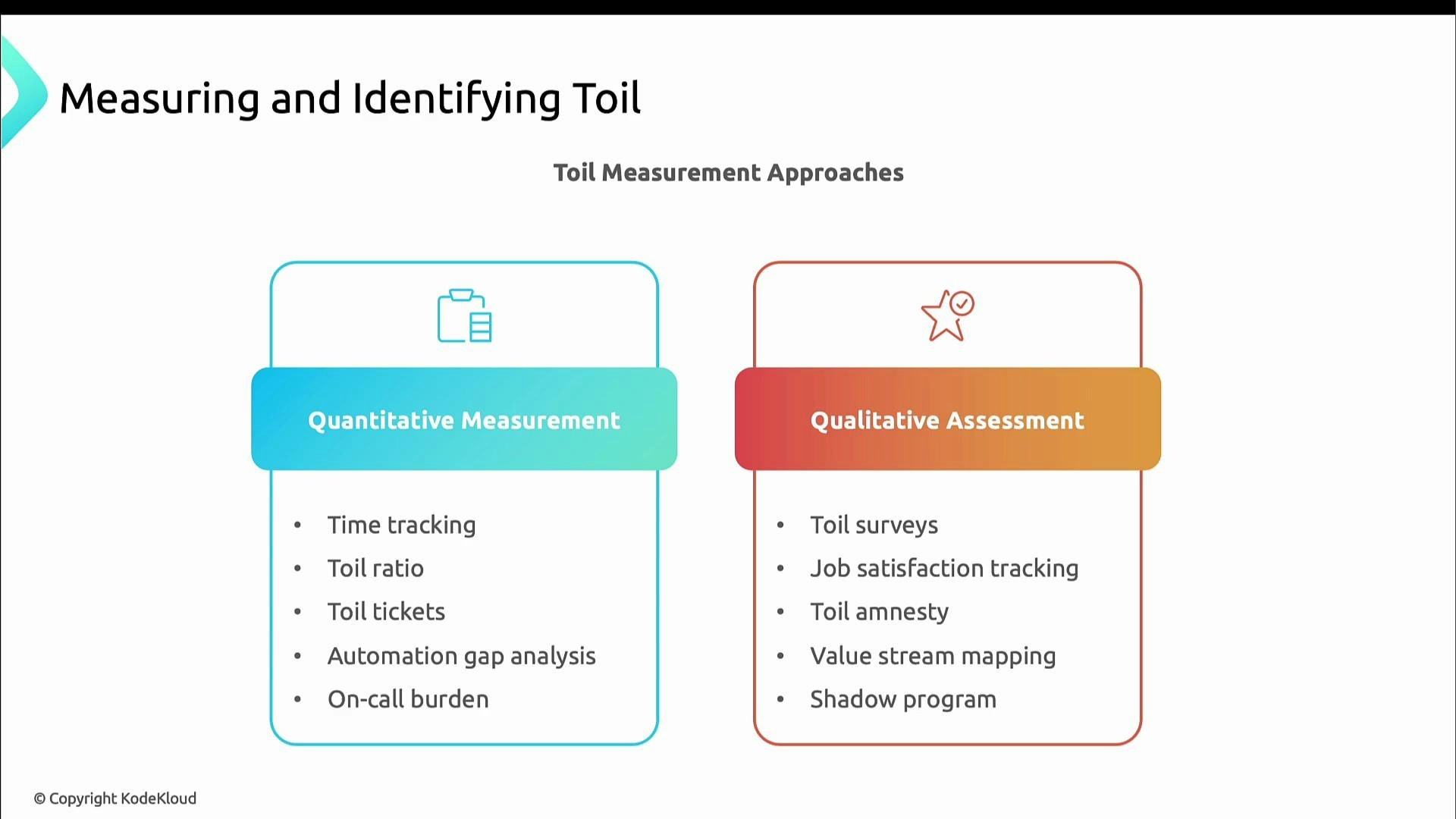
Measuring and identifying toil
Use a mix of quantitative and qualitative signals to locate and size toil. Combining both approaches helps prioritize which processes to eliminate or automate first.
Quantitative details:
- Time tracking: Log hours by category (deployments, incident response, manual maintenance).
- Toil ratio: Percentage of time spent on purely operational tasks vs. engineering.
- Toil tickets: Count tickets classified as pure operational work.
- Automation gap analysis: Document manual steps in workflows.
- On-call burden: Measure manual alert response hours.
- Toil surveys: Ask engineers for their primary pain points.
- Job satisfaction tracking: Correlate morale with toil metrics.
- Toil amnesty: Provide a safe way to report embarrassing or overlooked toil.
- Value stream mapping: Visualize handoffs and manual steps.
- Shadow programs: Observe and document undocumented operational work.
Hierarchy of approaches to reduce toil
Prioritize changes from most to least effective:Prefer elimination or automation where possible. Batching and delegation are last-resort options when elimination or automation are not feasible immediately.
Calculating the true cost of toil
To get budget and team buy-in, quantify direct and indirect costs. Direct costs:- Labor hours: engineer time × hourly rate.
- Incident costs: downtime and remediation resulting from manual errors.

- Opportunity cost: engineering improvements deferred because of toil.
- Attrition cost: turnover, recruitment, and lost tribal knowledge.
- Velocity impact: slower feature delivery and reduced competitiveness.
- Team size: 8 engineers
- Toil per engineer: 15 hours/week
- Hourly rate: $75/hour

Culture and process for sustainable reduction
Making toil reduction enduring requires process, incentives, and psychological safety:- Value engineering over heroics: Reward automation, refactoring, and systems thinking rather than heroic firefighting.
- Dedicated time budget: Allocate explicit time (e.g., an “engineering improvement” sprint) for removing toil.
- Psychological safety: Encourage raising and solving toil without blame.
- Knowledge sharing: Make runbooks and automation common knowledge, not tribal information.
- Continuous improvement: Treat toil reduction as an ongoing investment in reliability and velocity.
Do not treat toil as a rite of passage or a badge of honor. Normalizing manual firefighting hides systemic problems and increases long-term cost and risk.
Final thoughts
Toil is a symptom, not pride. Use measurement to prioritize elimination and automation, and build cultural practices that make toil reduction sustainable. This frees engineering capacity for durable improvements and better reliability. That concludes the lesson on managing complexity, risk, and toil. Next: incident management — change introduces instability, and effective incident practices determine how well a team recovers and learns.Links and references
- Site Reliability Engineering (SRE) concepts
- Kubernetes documentation — concepts overview
- CI/CD best practices
- Automation patterns and practices