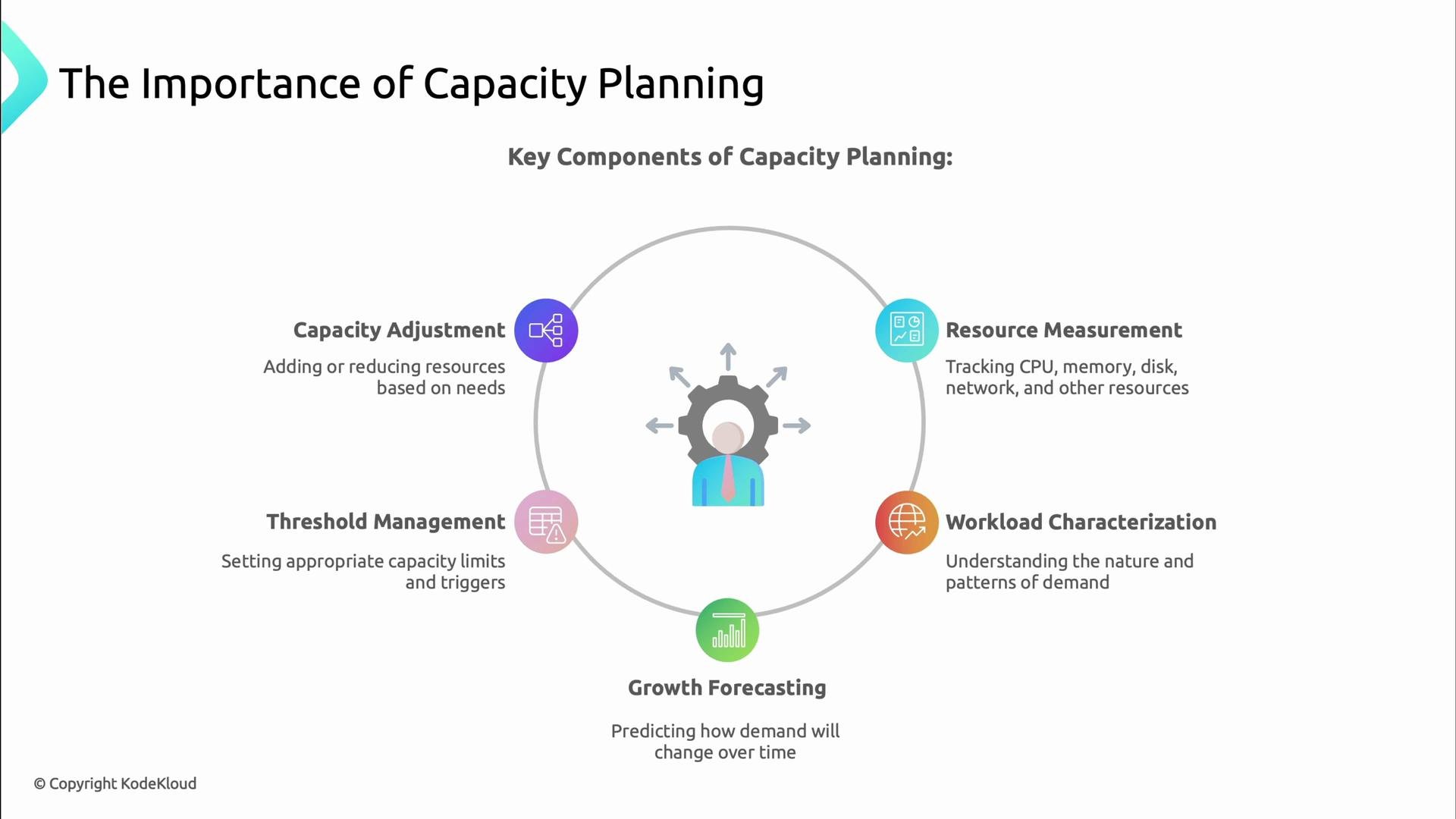
Main components
Capacity planning is built from a few repeatable activities:- Resource measurement — track CPU, memory, disk, network, and application-level metrics.
- Workload characterization — map request patterns, peaks, and steady-state behavior.
- Growth forecasting — predict future demand from historical trends and business drivers.
- Threshold management — define warnings and critical limits and the actions they trigger.
- Capacity adjustment — automate scaling and schedule planned provisioning.
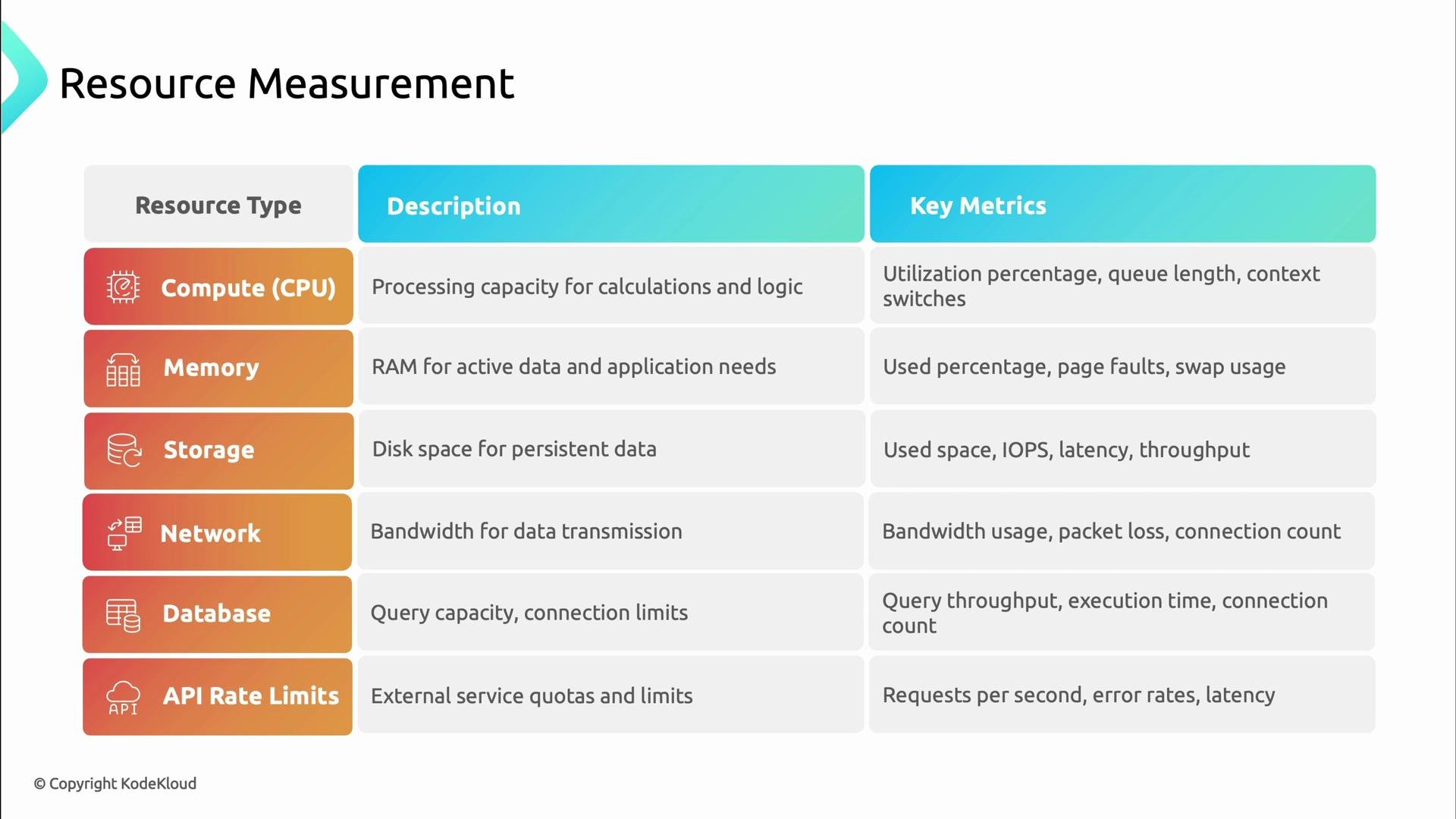
Resource types and metrics
Track the resources that directly affect reliability and performance. Use the table below to decide what to collect, visualize, and alert on.
Collect these metrics consistently so forecasting, alerting, and scaling decisions can be data-driven.
Example metric signals
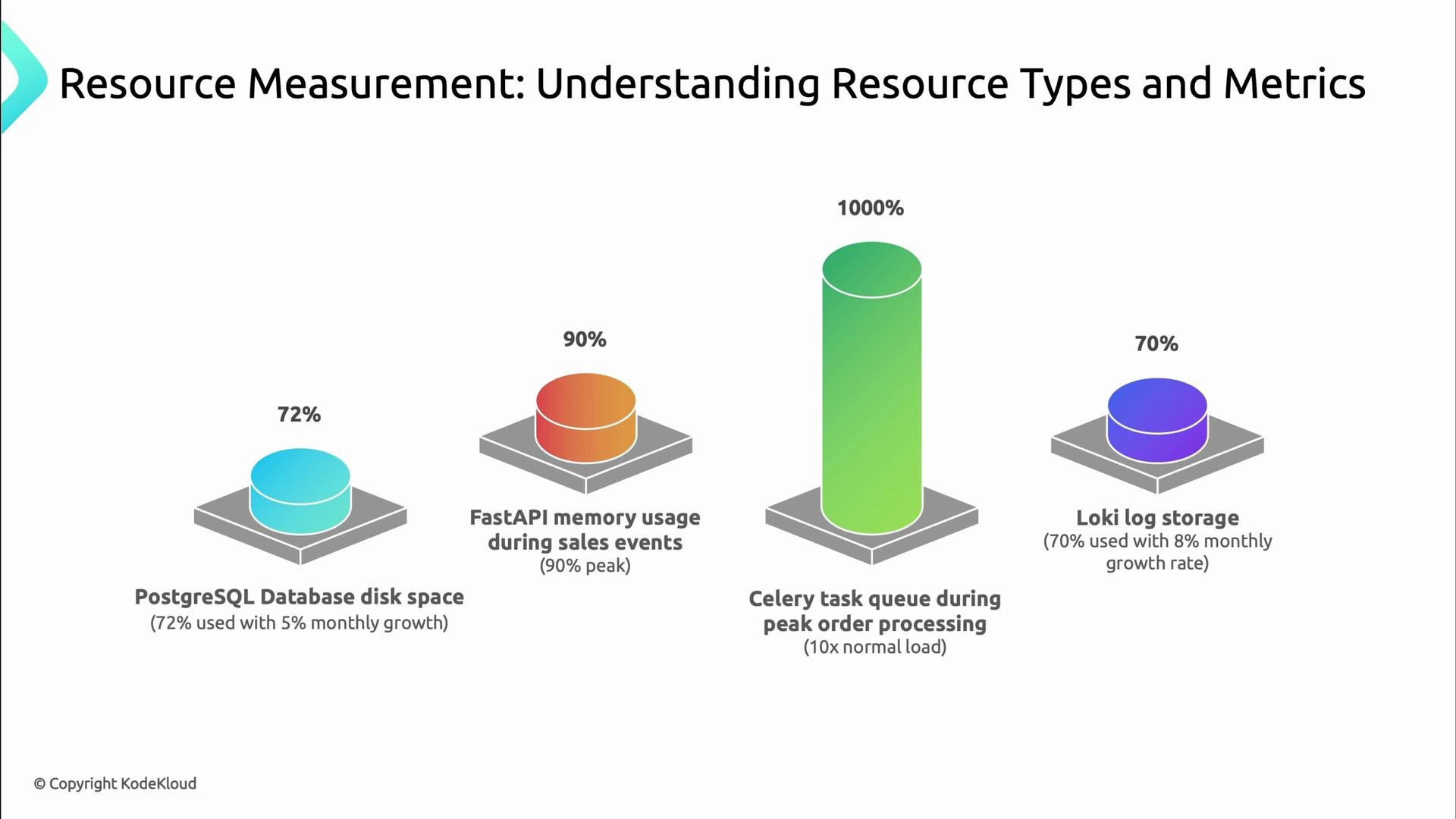
Real-world signals tell you when to act:- PostgreSQL disk usage: 72% used, growing at 5% monthly — schedule additional storage or reduce retention.
- FastAPI memory: peaks at 90% during sales — investigate leaks or increase pod memory and HPA targets.
- Celery task queue: 10× normal load during peak — add workers or throttle producers.
- Loki log storage: 70% used, growing at 8% monthly — change retention or add storage.
Example topology metrics
Below is an example snapshot of per-component metrics from a sample application. Use this structure to feed dashboards, alerts, and capacity models.Monitoring and visibility
Metrics only help when collected, stored, and visualized. Build dashboards that show trends (not just current values), wire alerts into incident workflows, and enable automated responders where safe. Without observability, forecasting and right-sizing are guesswork.Capacity forecasting
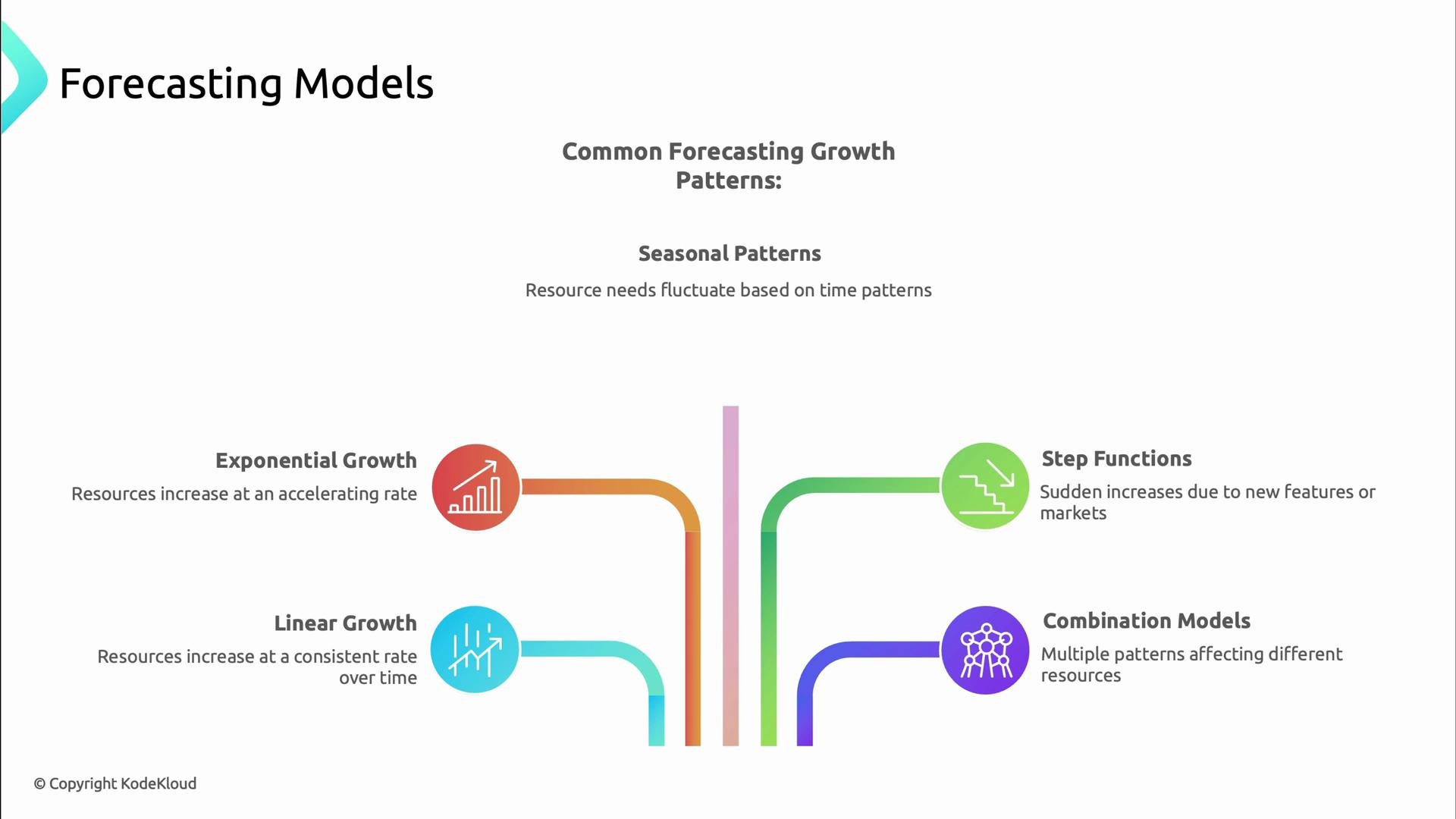
Forecasting uses historical signals and business context to predict future demand. Choose models that match observed behavior:- Linear growth — steady increase tied to predictable user growth.
- Exponential growth — viral adoption or new product launches.
- Seasonal patterns — daily/weekly/holiday cycles.
- Step functions — sudden jumps after marketing pushes or launches.
- Combination models — mixtures of the above patterns.
Proactive vs reactive
Both proactive and reactive controls are necessary:- Proactive: forecast demand, load-test, schedule upgrades, and right-size infrastructure ahead of peaks.
- Reactive: auto-scale, throttle, queue, or gracefully degrade when unexpected spikes occur.

Proactive planning reduces the number of emergency scale-ups you must perform, while reactive mechanisms keep the service available during unpredicted spikes. Both are necessary.
Reactive strategy example: Kubernetes HPA
Kubernetes Horizontal Pod Autoscaler (HPA) is a common reactive tool that scales pods based on CPU, memory, or custom metrics. HPA complements capacity planning by absorbing short-term bursts while longer-term capacity is provisioned.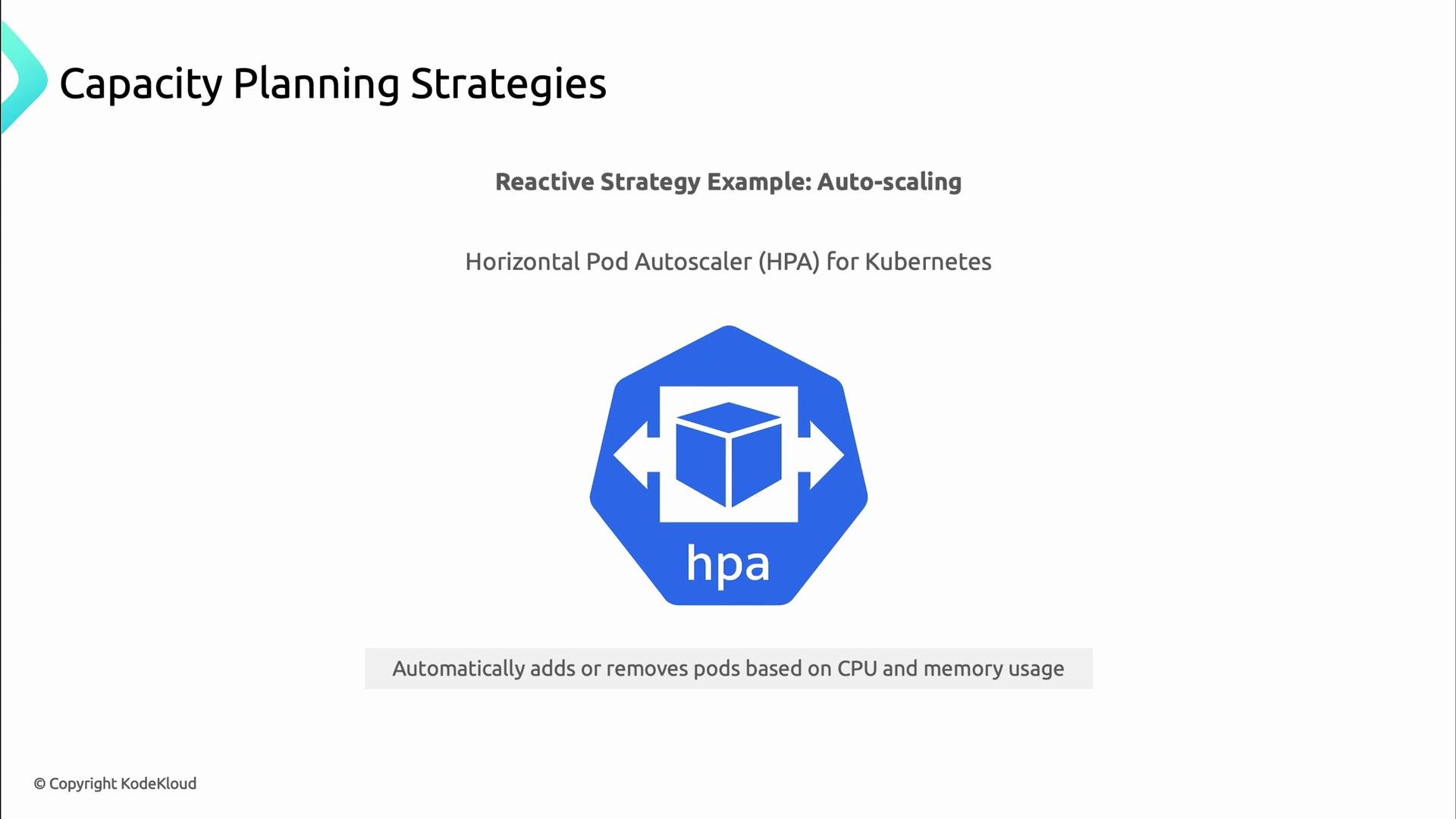
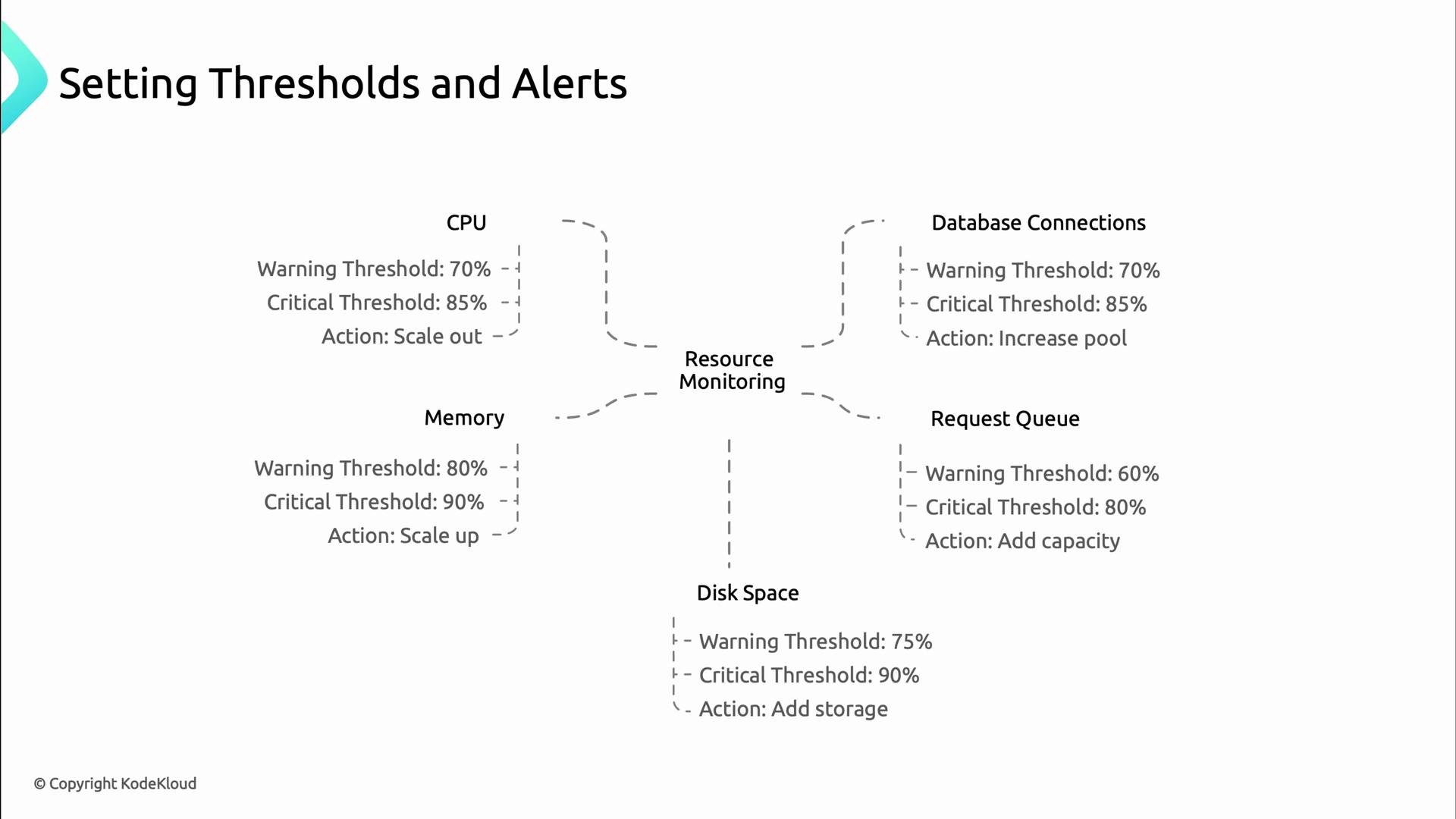
Thresholds and alerts
Translate metrics into actionable alerts with thresholds that give you time to act while minimizing false positives.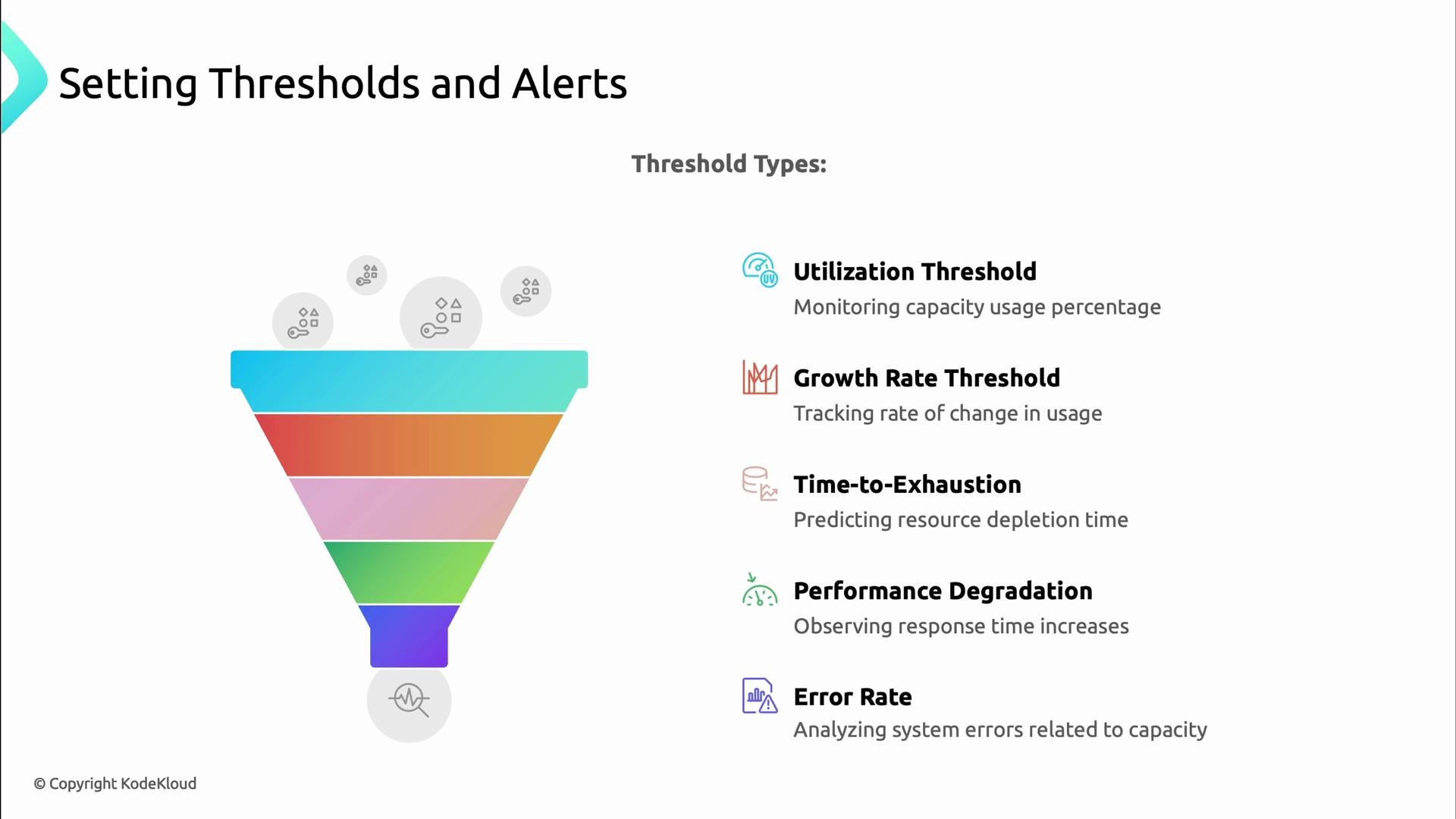
- Utilization thresholds (CPU %, memory %).
- Growth rate thresholds (rate of change).
- Time-to-exhaustion (predict when a resource will be depleted).
- Performance degradation (p95/p99 latency increases).
- Error-rate thresholds (5xx spike).
Summary
Effective capacity planning combines measurement, forecasting, sensible thresholds, and automation. Build visibility with observability tools, choose forecasting models that reflect your workload, and implement both proactive strategies (planning and testing) and reactive controls (autoscaling and graceful degradation). This approach reduces outages, controls cost, and supports growth while keeping users happy.Links and references
- Kubernetes Autoscaling (HPA)
- Prometheus: Monitoring System
- PostgreSQL Documentation
- Loki (Grafana Loki) Logs