Manage risk with error budgets (balance innovation and reliability)
SRE accepts that 100% uptime is impractical and typically too expensive. Instead, teams set Service Level Objectives (SLOs) that define acceptable reliability and use error budgets to quantify allowable failure. When a service is within its error budget, teams can safely ship features; when the budget is spent, the priority shifts to stability and remediation.
Ask the right questions early (influence design and reduce surprises)
SREs get involved at design and planning stages to influence trade-offs and reduce operational risk. Useful, repeatable questions to ask service owners include:- How can this service fail?
- How will we detect that it failed?
- What actions must be taken when it fails?
- What context and runbook steps are required to respond effectively?

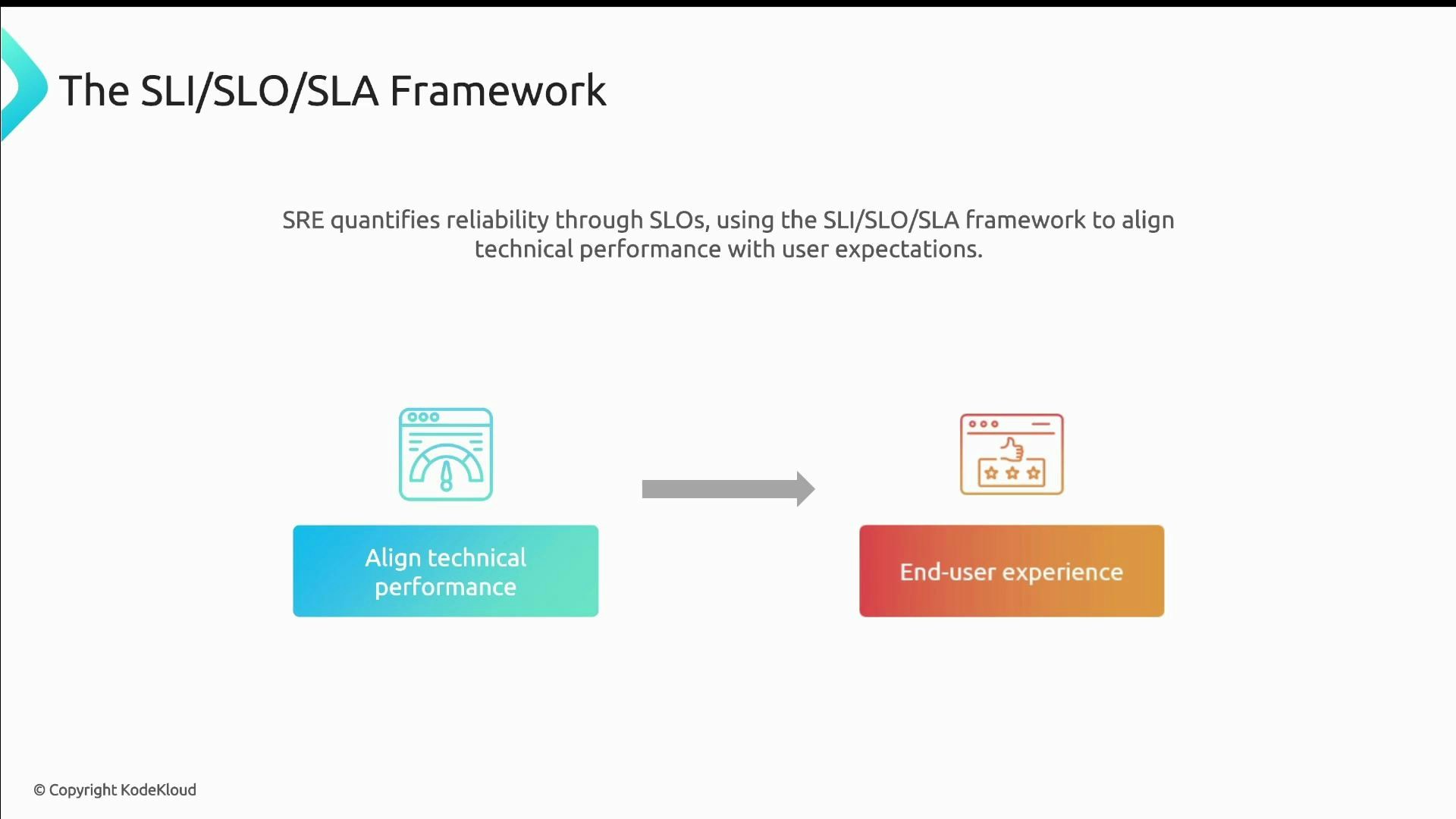
Measure reliability: the SLI → SLO → SLA model
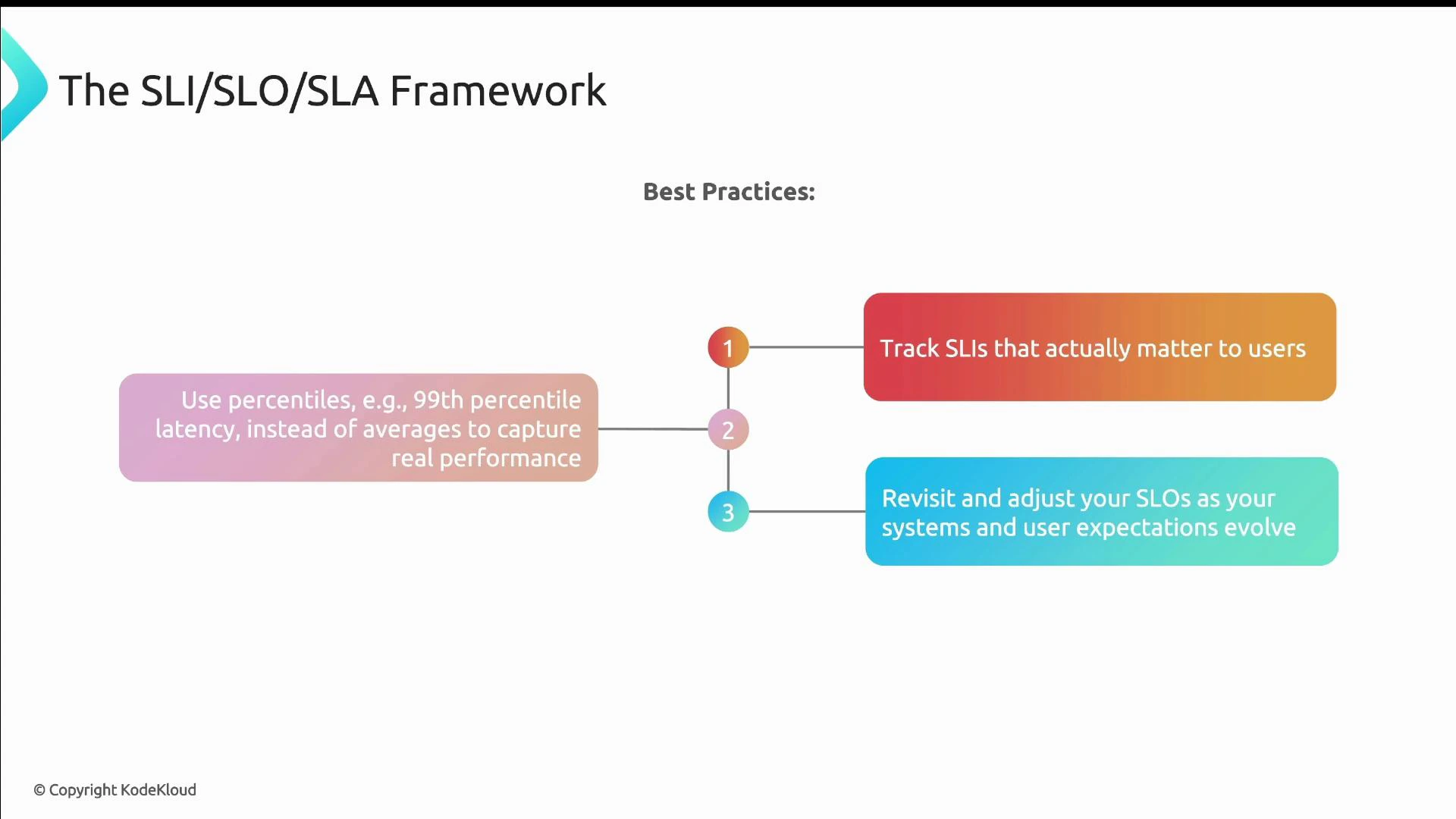
SRE quantifies reliability with a three-part model:- Service Level Indicators (SLIs): metrics that reflect user experience (latency, error rate, availability).
- Service Level Objectives (SLOs): internal targets for SLIs that guide trade-offs.
- Service Level Agreements (SLAs): external, contractual commitments tied to customer expectations or penalties.
| Resource | Purpose | Example SLI |
|---|---|---|
| SLI | Measures user-facing behavior | 99th percentile request latency |
| SLO | Target for an SLI over a time window | 99.9% successful responses per month |
| SLA | Customer-facing contract | 99.95% uptime with financial credits on breach |
Use SLIs to reflect actual user experience, and let SLOs guide trade-offs between feature velocity and reliability—this is what the error budget enforces.
Eliminate toil through automation (free time for engineering)
Toil is manual, repetitive work that scales with the system and yields little long-term value. SREs aim to automate recurring operational tasks—backups, routine incident tasks, and deployment steps—to reduce toil and free engineers for design and reliability improvements. A common target is to keep toil below 50% of SRE time to maintain capacity for engineering work. Automation is iterative: automating tasks reveals deeper system behaviors and drives further automation opportunities.

Automate thoughtfully. Blind automation of poorly understood processes can create hard-to-debug failures. Ensure automation is observable, tested, and reversible.
Invest in monitoring and observability (see how systems behave in production)
Monitoring shows how systems actually behave under real load. Focus on symptoms (what the user experiences) as well as causes, and prioritize observable signals that map to user impact. A practical starting point is Google’s four golden signals: latency, traffic, errors, and saturation. Measure the right things—if you don’t measure them, you can’t improve them.
Foster a blameless culture (enable learning and improvement)
Psychological safety is a prerequisite for learning. Blameless postmortems focus on system and process weaknesses rather than individual fault. This encourages open knowledge sharing, surfaces systemic fixes, and reduces repeat incidents. Look to other safety-critical industries (e.g., aviation) for proven incident investigation and learning practices.
Prefer simplicity (reduce failure modes and speed recovery)
Simple systems are easier to reason about, fail less often, and recover more quickly. Simplicity means avoiding unnecessary complexity, preferring composition over reinvention, and evaluating design decisions from the user’s perspective. Simplicity improves safety for change and makes incident response more effective.
Summary — how these principles work together
These core principles are not isolated rules; they form a coherent approach:- Use SLOs and error budgets to balance reliability with product velocity.
- Instrument systems and ask the questions that reveal failure modes.
- Automate routine work to focus on engineering improvements.
- Observe production using meaningful SLIs and the four golden signals.
- Build a blameless culture to learn from failures.
- Keep architecture and operational practices simple.
- Google SRE Book — Monitoring Distributed Systems (Four Golden Signals)
- Kubernetes Documentation
- Docker Hub
- Define SLIs that matter to users, set SLOs to guide priorities, and treat SLAs as contractual obligations.
- Keep toil low through deliberate automation and make automation observable and reversible.
- Monitor symptoms from the user’s point of view and cultivate a blameless culture for continuous improvement.