Welcome to Module Two. In this lesson we cover the fundamentals of Site Reliability Engineering (SRE), trace its origin at Google, and follow how its practices evolved into the reliability engineering methods used across industry today. Before SRE, most organizations kept development and operations strictly separated. Development teams prioritized rapid feature delivery with limited production visibility, while operations teams focused on uptime and stability, using manual incident workflows and risk-averse practices. These silos created friction, conflicting incentives, and a lack of shared accountability—problems that magnified as systems scaled.Documentation Index
Fetch the complete documentation index at: https://notes.kodekloud.com/llms.txt
Use this file to discover all available pages before exploring further.
- Linear, sequential development lifecycles (development → testing → deployment) that slowed delivery and reduced agility.
- Broken feedback loops, where operations rarely gave developers timely, actionable production feedback.
- Poor scalability and adaptability: legacy architectures and manual processes struggled with rapid change and high load.

- Hire software engineers to solve operations problems with engineering practices and software tooling.
- Automate manual processes and build internal tools to reduce human toil.
- Embrace measured risk: recognize that 100% uptime is usually infeasible and balance reliability with feature velocity using Service Level Objectives (SLOs) and error budgets.
- Eliminate toil: minimize repetitive manual work so engineers can focus on automation, reliability engineering, and system design.

Error budgets are operational levers: if the budget is exhausted, teams throttle risky releases and prioritize remediation; if budget remains, teams can accelerate feature work. Use error budgets to align product and reliability goals.

Reliability requires explicit targets, monitoring, and change controls. Don’t treat uptime as an afterthought—define SLOs, track error budgets, and automate rollouts and rollbacks.
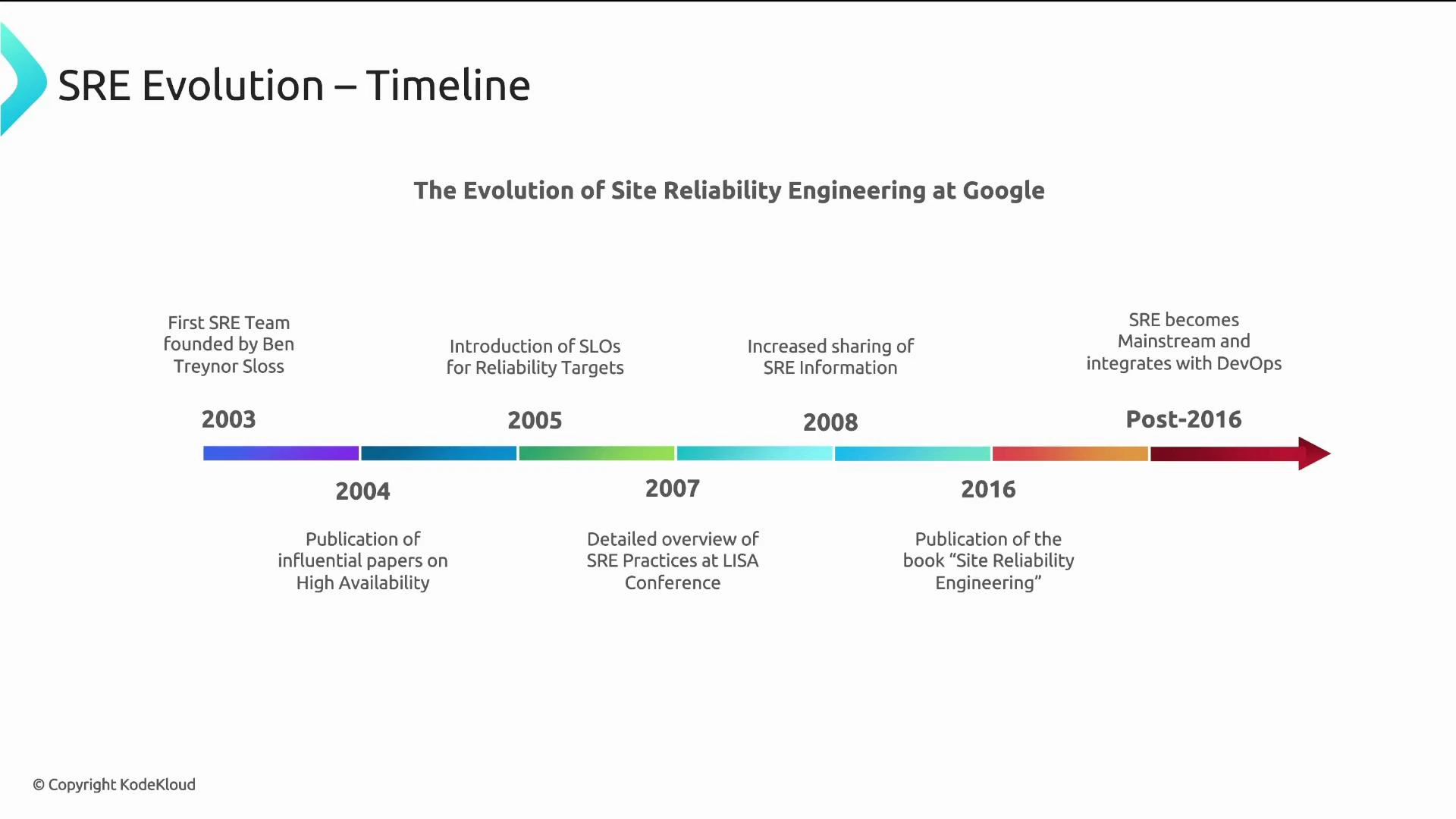
| Year / Period | Milestone | Notes |
|---|---|---|
| Early 2000s | Google scales rapidly | Traditional ops could not keep up; engineering principles applied to operations. |
| 2003 | First official SRE team founded | Ben Treynor Sloss formalized the role and charter. |
| 2004 | Early high-availability papers | Laid the groundwork for SRE practices. |
| 2005 | SLOs introduced | Service-level objectives began to define and measure reliability targets. |
| 2007–2008 | Public SRE presentations | Concepts shared in conferences and talks increased external visibility. |
| 2016 | Google publishes Site Reliability Engineering book | A foundational, public resource as SRE reached broader adoption. |
| Post-2016 | Mainstream adoption | Many companies adopted and adapted SRE alongside DevOps. |

| Company / Model | Approach |
|---|---|
| Embedded SREs inside product teams to promote developer ownership of reliability. | |
| Meta | Production engineering: a hybrid that combines SRE principles with infrastructure/tooling responsibilities. |
| Uber | Adopted SRE practices to address rapid scaling and large operational complexity. |
- AI/ML for reliability: anomaly detection, predictive analysis, and automation-assisted remediation.
- Cloud-native SRE: containerization, microservices, and orchestrators (e.g., Kubernetes) shaping operational practices.
- Platform engineering: centralized internal platforms that provide reusable tools and abstractions for developers.
- Shift-left reliability: design-for-reliability earlier in development, with testing and observability integrated into CI/CD.
- Cost optimization and FinOps: balancing cloud costs and performance while meeting SLOs.

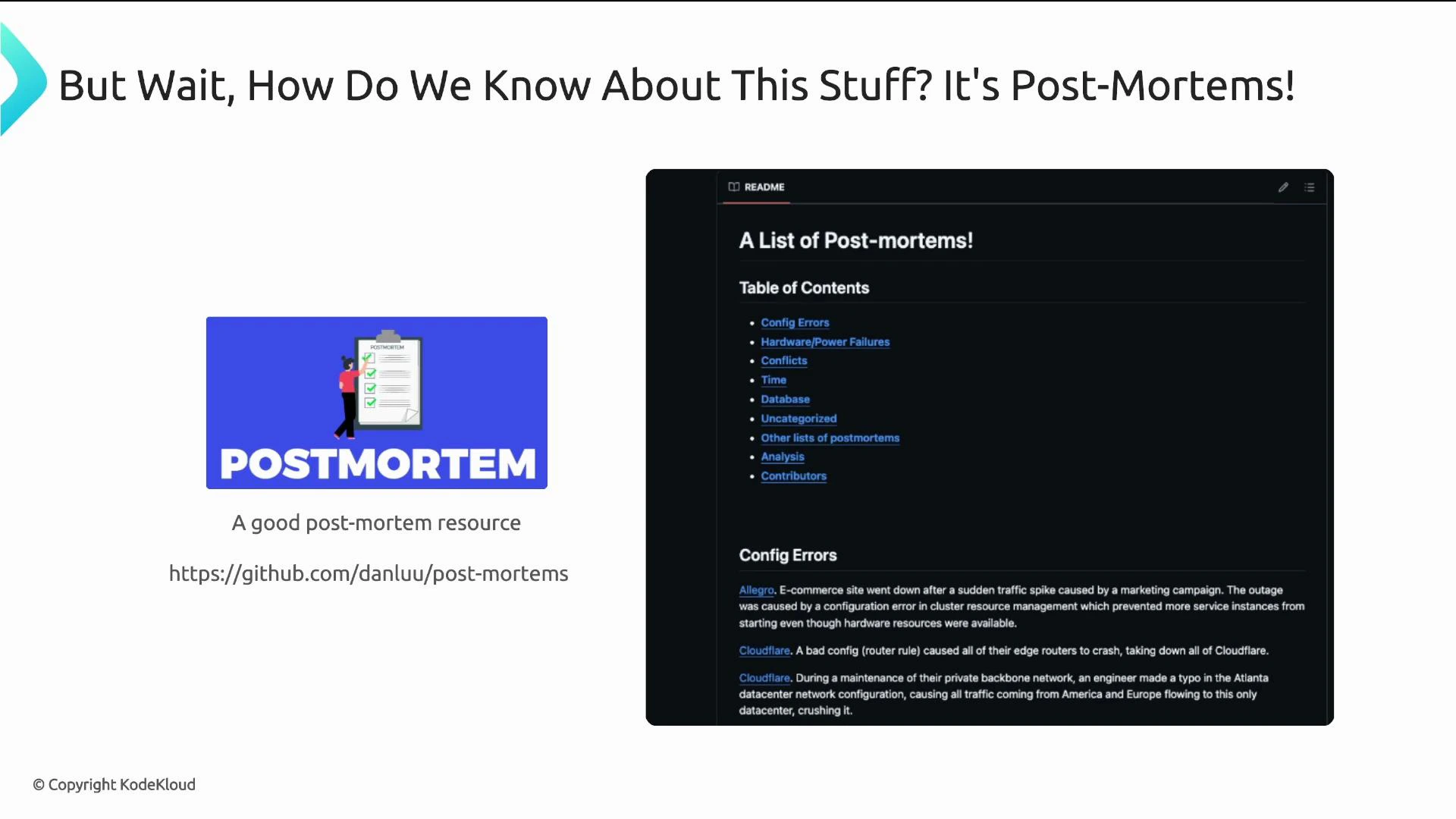
- Site Reliability Engineering (book) — https://sre.google/books/
- Collections of public postmortems and incident reports (search GitHub and engineering blogs for “postmortem” and “incident report”)
- DevOps and SRE guidance from cloud providers and standards bodies (e.g., Kubernetes docs, cloud provider reliability guides)