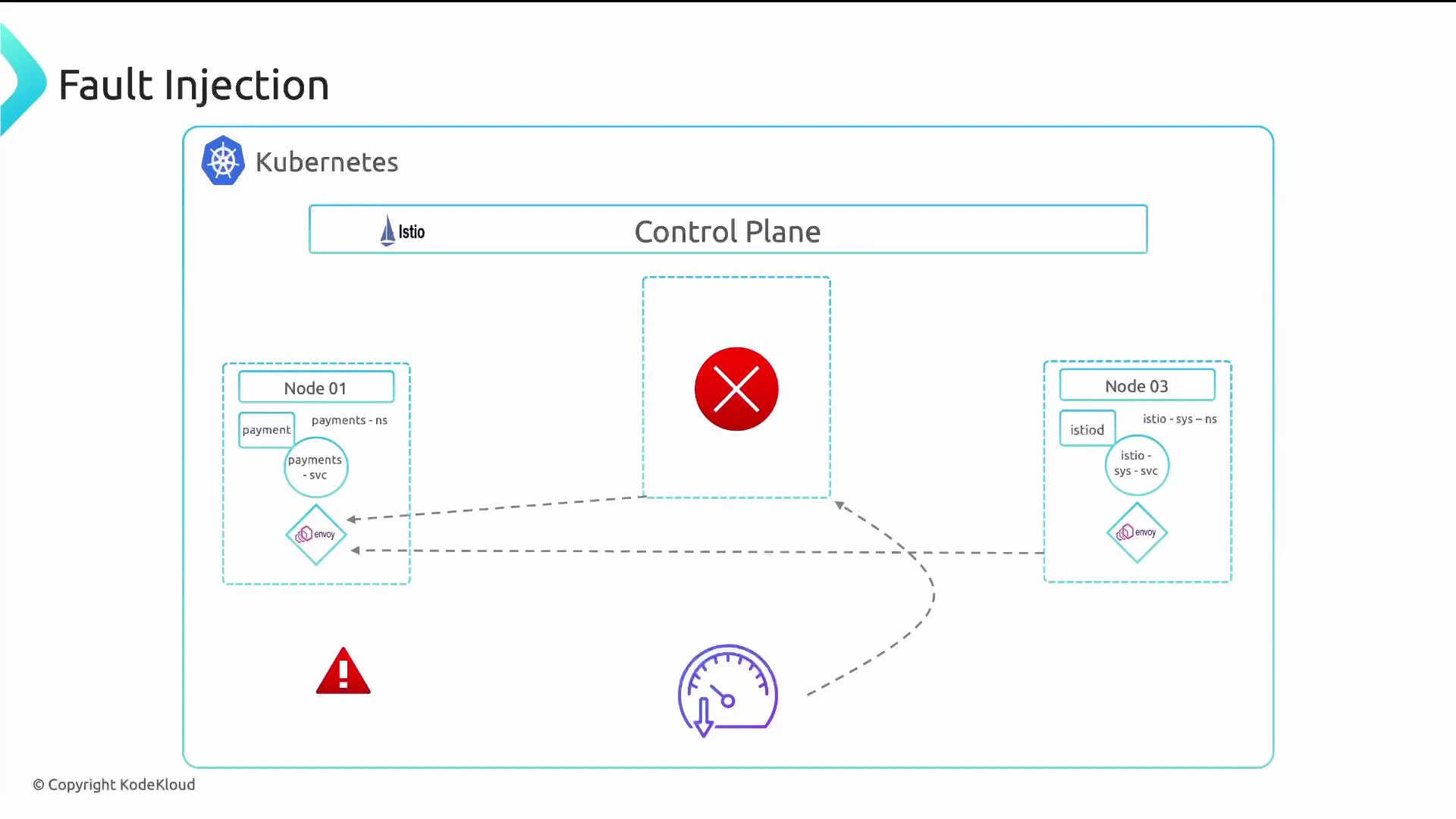
- Validate how applications respond to slow or failing dependencies.
- Test fallback logic and ensure graceful degradation (e.g., return cached results, use a backup service, or return a friendly error).
- Ensure timeouts and retry policies prevent cascading failures.
- Detect bugs, misconfigurations, and missing error handling early in the CI/CD pipeline.
- Build confidence in resilience through repeatable experiments (chaos engineering). A well-known example is Netflix’s Chaos Monkey.

Fault injection provides a safe, repeatable way to validate reliability, fallbacks, and recovery strategies before a real outage occurs.
fault section on http routes. The two primary types are:
- Delay: injects artificial latency (e.g.,
fixedDelay: 5s) for a percentage of requests. - Abort: returns an HTTP error code (e.g.,
httpStatus: 400) or a gRPC status for a percentage of requests.
| Fault Type | Purpose | Key fields | Typical use |
|---|---|---|---|
| Delay | Simulate increased latency | fault.delay.fixedDelay, percentage.value | Test timeouts, circuit breakers, and slow downstream services |
| Abort | Simulate error responses | fault.abort.httpStatus or fault.abort.grpcStatus, percentage.value | Test error handling, fallbacks, and retry logic |
app-svc in the frontend namespace:
- Abort a small percentage to simulate intermittent client errors.
- Inject delays only for traffic from specific sources (e.g., production labeled traffic) to limit blast radius.
ratings-route: abort 10% of requests with HTTP 400.reviews-route: inject a 5-second delay for 10% of requests coming from sources labeledenv: prod.
- Use
percentage.valueto control the blast radius. Start small (e.g., 1–5%) when testing in production-like environments. - Combine fault injection with observability (metrics, logs, tracing) so you can measure impact and validate fallback behavior.
- Prefer targeted matches (source labels, headers, or subsets) to limit scope.
Be careful when running fault injection in production. Always limit the impact with percentage-based targeting, source filters, and monitoring. Do not enable broad, 100% faults against critical services without coordinated rollback plans.
- Istio Fault Injection: https://istio.io/latest/docs/tasks/traffic-management/fault-injection/
- Chaos engineering inspiration: Netflix Chaos Monkey — https://netflix.github.io/chaosmonkey/