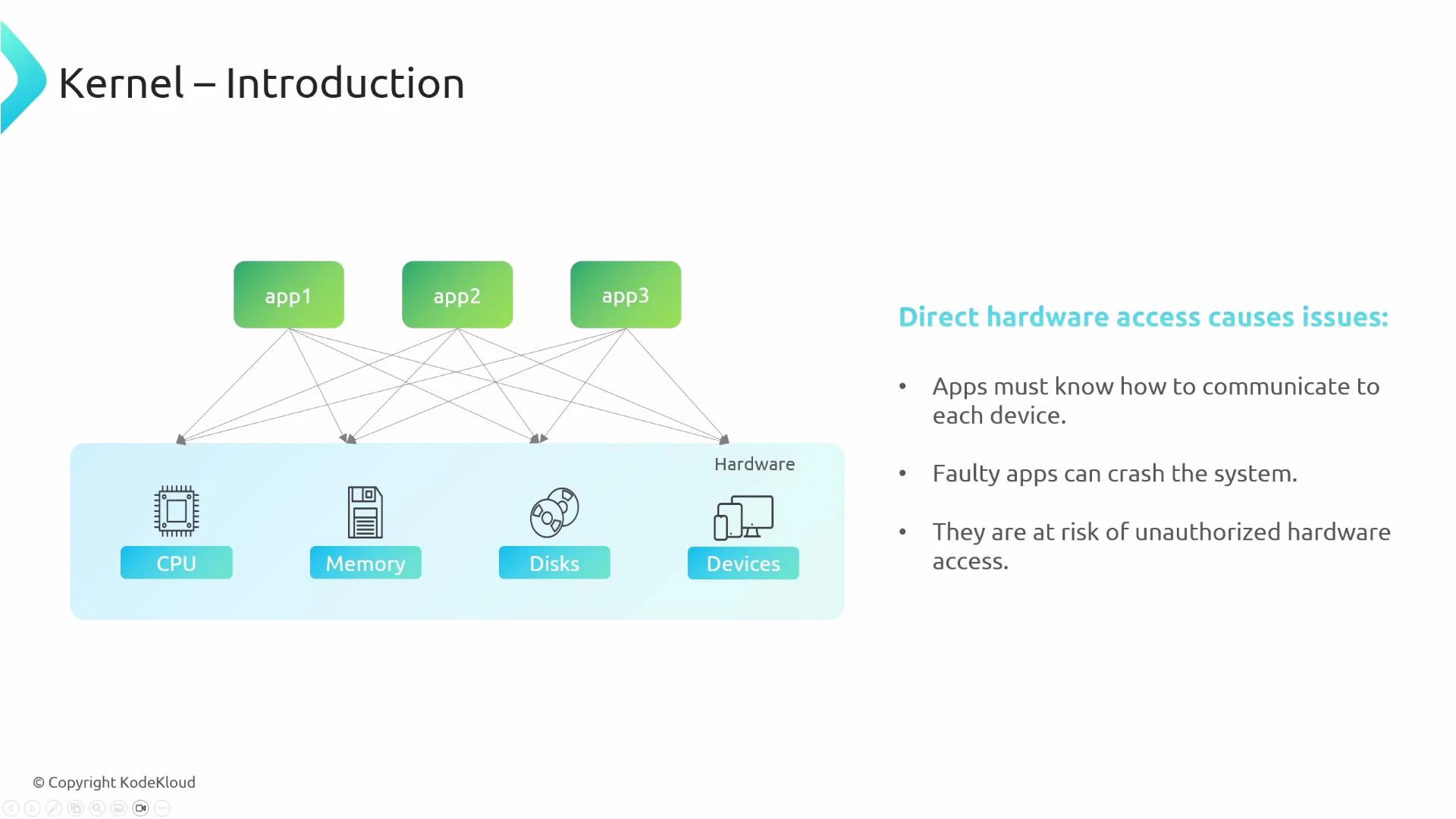
- Applications would need device-specific logic and drivers, increasing complexity.
- A buggy or malicious application could crash the whole system.
- Direct access increases the attack surface and enables abuse of hardware/data.
- Allocate CPU time, memory, and I/O devices among processes.
- Enforce memory and execution isolation so one process cannot corrupt another.
- Provide a controlled interface for applications via system calls.
- Load and manage device drivers that implement hardware-specific logic.
- Kernel space — privileged code with full access to hardware and CPU features.
- User space — unprivileged applications that must request kernel services via system calls.
- Security: limit what processes can do.
- Stability: confine crashes to user processes rather than the whole OS.
- Multitasking: kernel arbitrates resource sharing and context switching.
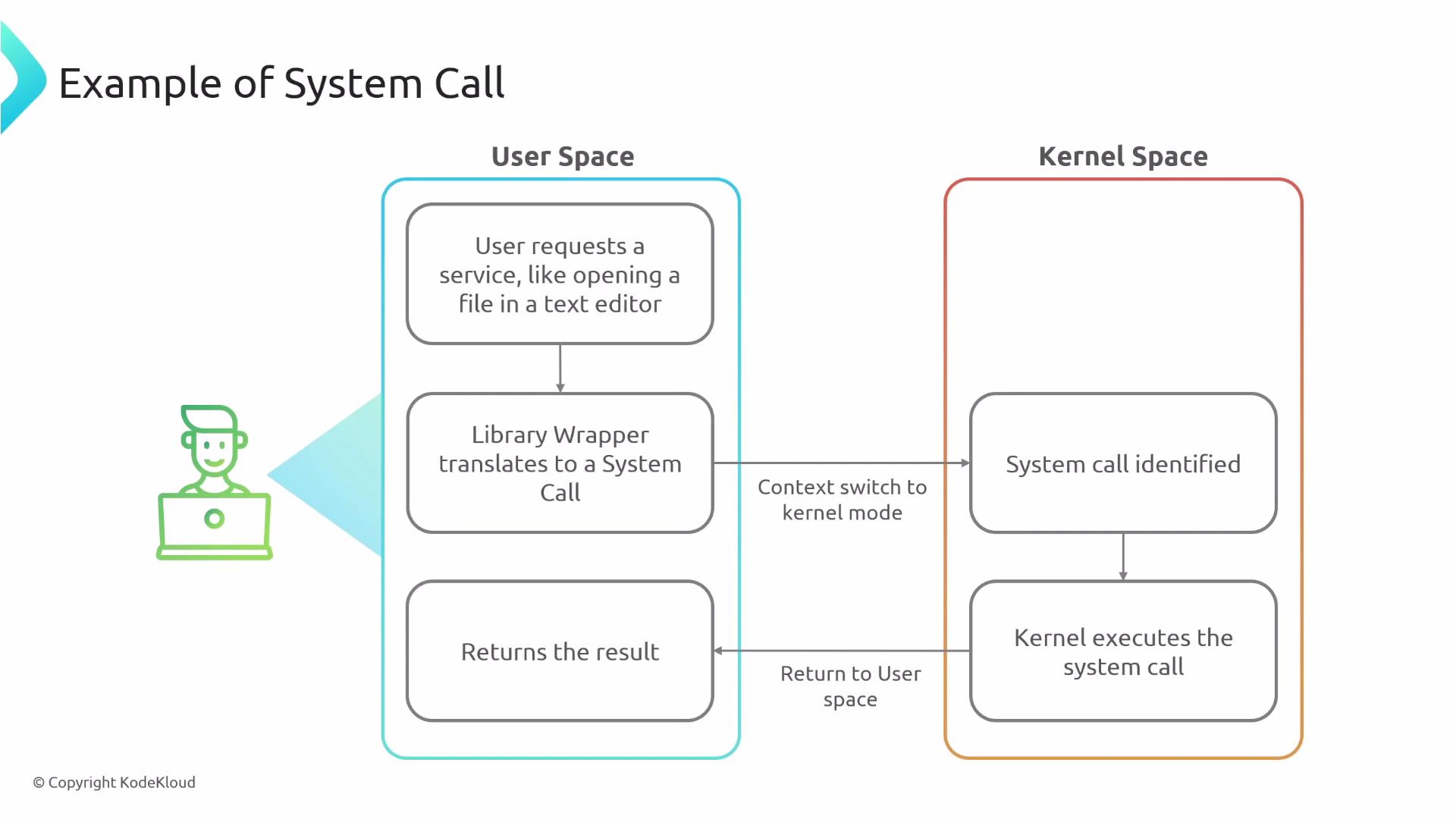
Example syscall flow when an application opens a file:
- User-space application calls a library wrapper (e.g., libc
open()). - The wrapper issues the kernel system call, which transitions execution into kernel space.
- The kernel performs the operation using drivers and hardware access.
- Results are returned to user space and the application resumes.
eBPF programs are verified and sandboxed by the kernel verifier, and communicate with user-space via BPF maps. Once verified, eBPF bytecode can be JIT-compiled for high throughput and low latency. Learn more at the official eBPF site: https://ebpf.io/.
- No kernel-source changes or per-kernel-module builds.
- Dynamic load/unload without reboot.
- Kernel verifier reduces risk of crashes and undefined behavior.

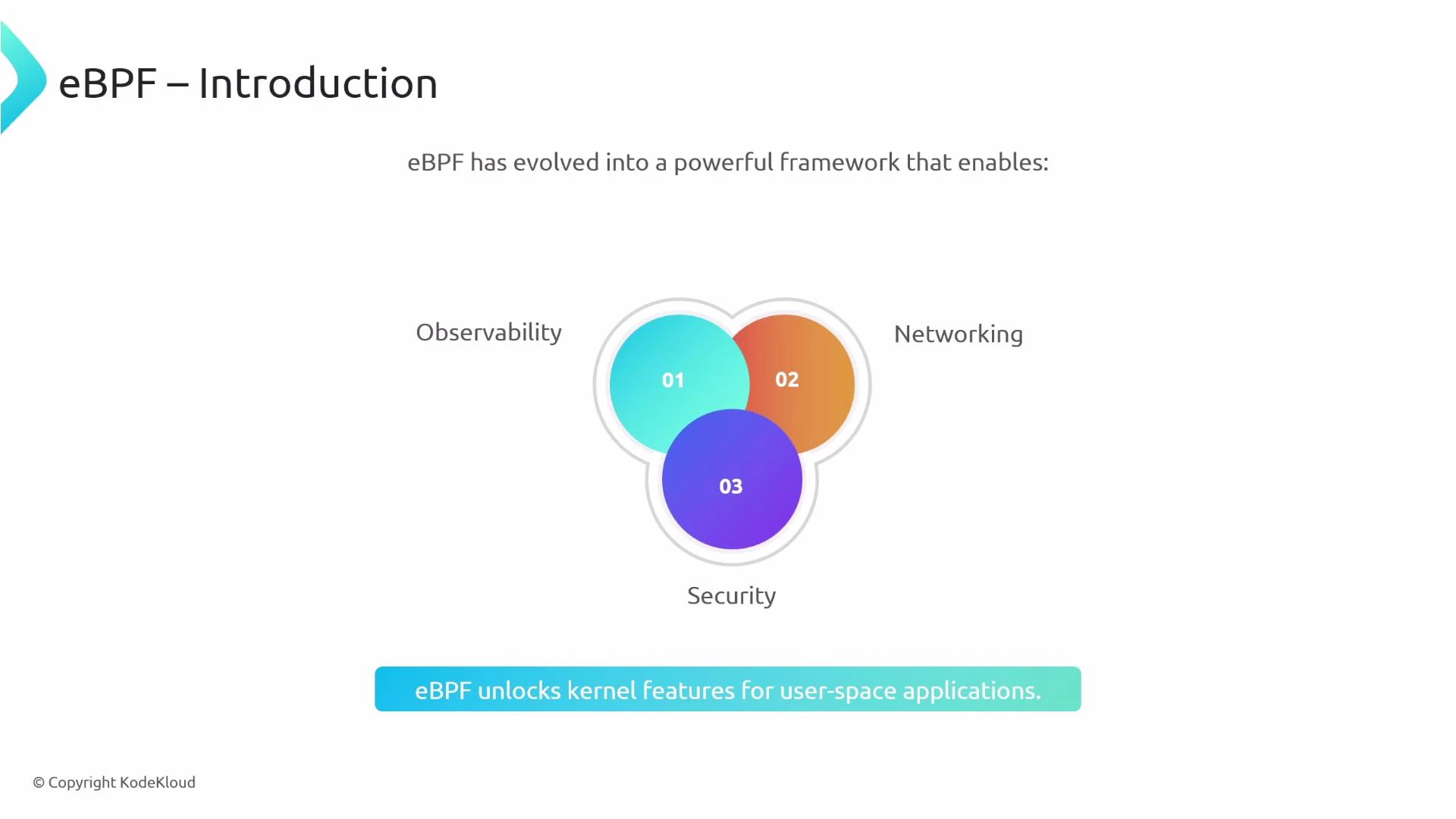
- Collect and aggregate observability data, exposing it to user space via BPF maps.
- Inspect, filter, modify, or redirect packets at various kernel hook points.
- Attach to syscalls, kprobes/uprobes, tracepoints, or cgroup hooks for runtime tracing or enforcement.
- Be updated or unloaded by user-space controllers without a kernel reboot.
- Observability overhead: Traditional instrumentation often relies on polling or intrusive tracing that increases overhead. eBPF enables event-driven, low-overhead tracing of syscalls, kernel events, and user-space interactions in near real time.

- Visibility into kernel ↔ user interactions: Getting safe, fine-grained insight into syscalls, memory allocation, and network traffic was historically intrusive. eBPF makes real-time tracing safe and efficient.
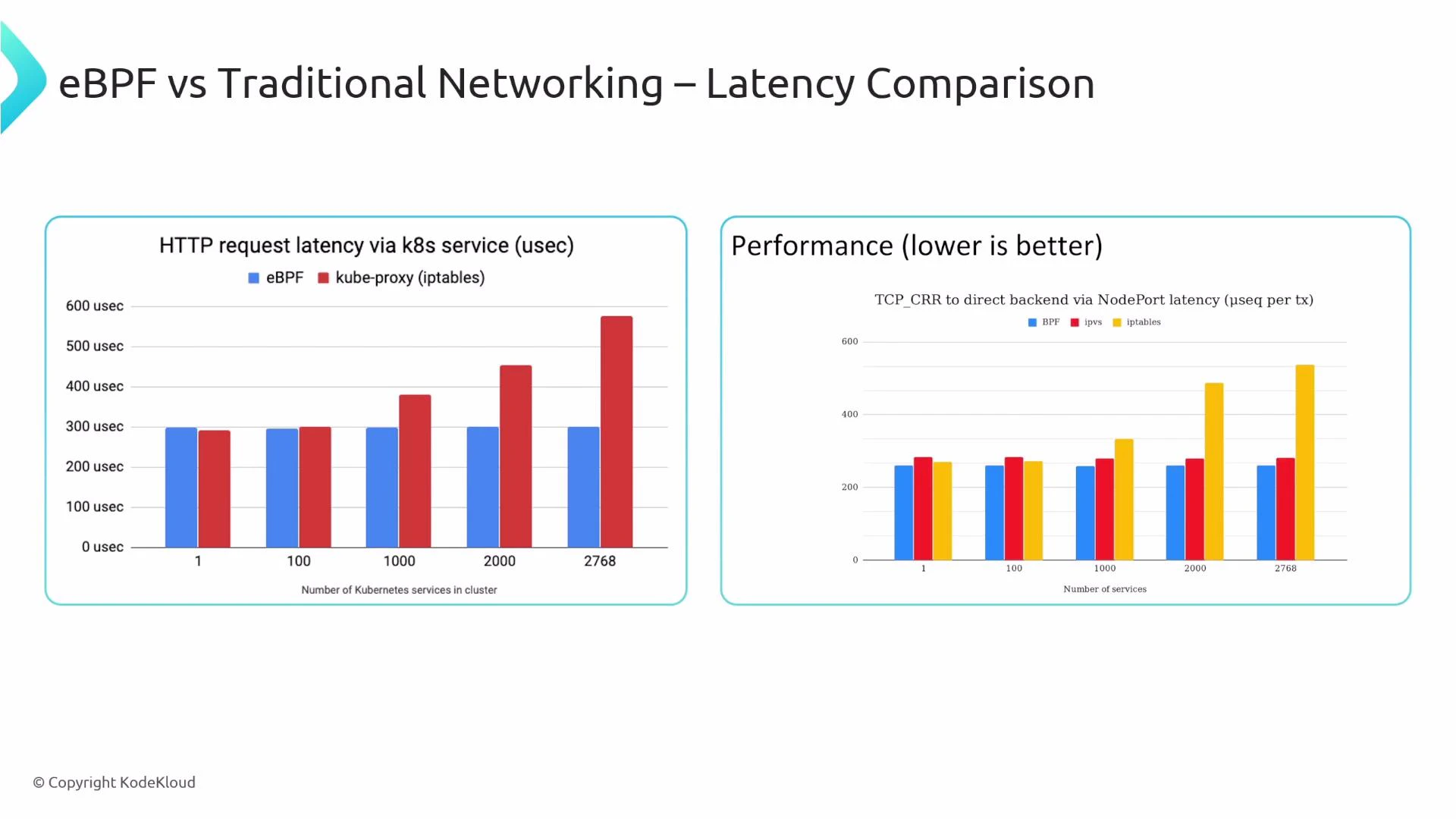
- Network packet processing latency: eBPF programs (including XDP) can filter and process packets at kernel hook points far earlier than the traditional network stack. This enables much lower latencies and higher throughput than iptables/nftables in high-scale scenarios.
- Runtime security and enforcement: Detecting and stopping malicious behavior (suspicious syscalls, kernel rootkits, anomalous memory access) is hard with classic tools. eBPF enables dynamic policy enforcement and behavioral analysis in real time.

One important eBPF-based framework: XDP (eXpress Data Path). XDP allows eBPF programs to attach at the earliest packet receive hook—inside the NIC driver—so packets can be accepted, modified, redirected, or dropped before they go through the kernel network stack. This yields ultra-low-latency packet handling for DDoS mitigation, load balancing, and other high-performance networking tasks.
XDP programs run at the earliest receive hook (NIC/driver level) and are ideal for high-performance packet ops such as drop/redirect/modify. XDP is widely used when ultra-low latency and extreme throughput are required.
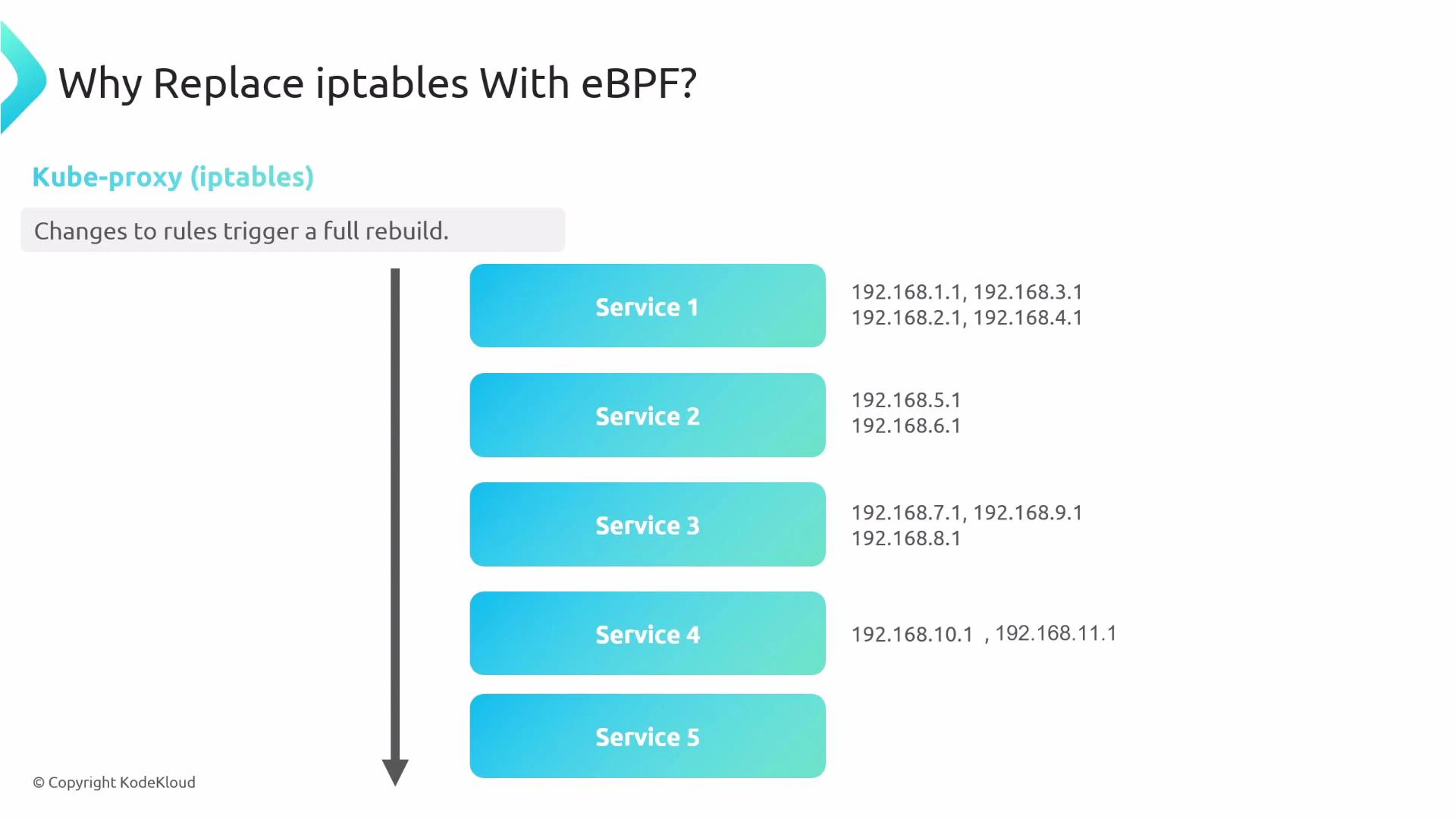
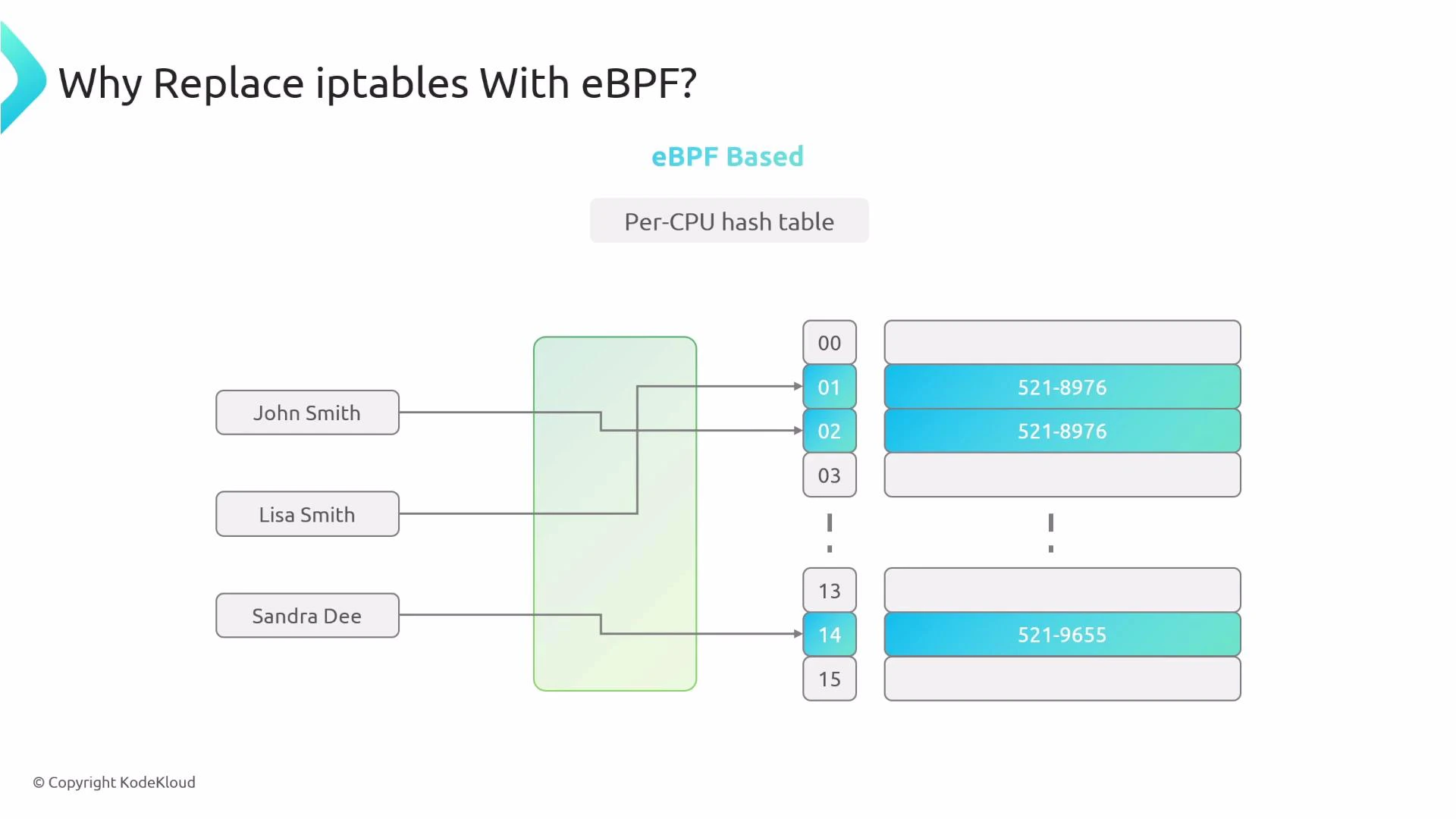
- In-node packet forwarding is implemented with eBPF programs (replacing large iptables rule sets).
- Service load balancing can be implemented in-kernel with eBPF instead of kube-proxy + iptables.
- Network policies are enforced at packet hooks via eBPF.
- Observability (flows, metrics, tracing) is integrated into the eBPF datapath.
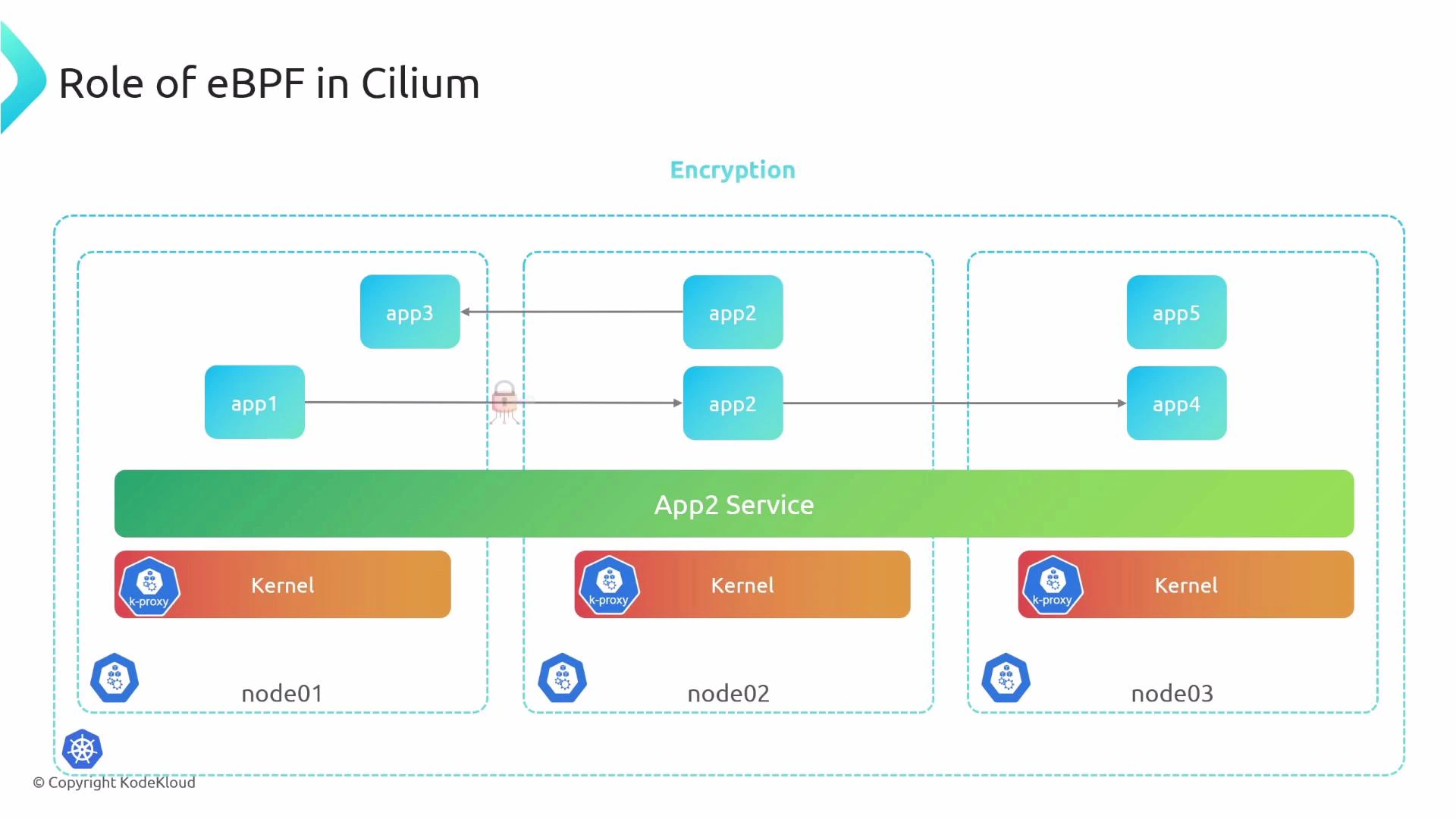
- Additional features (encryption, multi-cluster connectivity, scalable load balancing) are accelerated by eBPF.
- Direct hardware access by applications creates complexity, instability, and security issues. The kernel mediates hardware access safely.
- Device drivers let the kernel control hardware devices.
- System calls are the interface user-space programs use to request kernel services.
- Kernel space is privileged; user space runs with restricted privileges and uses syscalls to access features.
- eBPF enables small, verified programs to run within the kernel without adding unsafe modules. eBPF programs use BPF maps to communicate with user space and are verified for safety.
- eBPF use cases include observability, tracing, packet processing, load balancing, runtime security, and performance tuning.
- Cilium leverages eBPF to replace kube-proxy, implement load balancing, enforce policies, and deliver built-in observability and encryption.
- XDP is an eBPF-based framework that operates at the NIC/driver level for ultra-low-latency packet processing.


- eBPF official site: https://ebpf.io/
- Cilium: https://cilium.io/
- Kubernetes kube-proxy documentation: https://kubernetes.io/docs/reference/command-line-tools-reference/kube-proxy/
- iptables: https://netfilter.org/projects/iptables/index.html
- nftables: https://wiki.nftables.org/