This guide covers resilience and disaster recovery, focusing on high availability, disaster recovery planning, and cloud-based tools for business continuity.
In this final section of our security architecture guide, we dive into resilience and disaster recovery. This guide covers critical topics such as high availability, disaster recovery planning, and leveraging cloud-based tools to ensure overall business continuity.
Key considerations include designing for high availability, understanding downtime measurements, and selecting appropriate disaster recovery sites.
High availability is achieved by constructing an architecture that minimizes downtime through fault tolerance and redundancy across servers, routers, switches, and data centers.
Systems designed for high availability are typically measured in “nines.” For a system expected to run 24 hours a day, 365 days a year, the goal is near 100% uptime by subtracting the total allowed downtime. For example:
99.999% uptime (“five nines”) permits approximately 5 minutes and 15 seconds of downtime per year.
99.99% uptime (“four nines”) allows roughly 52 minutes and 34 seconds of downtime annually.
When designing for high availability, consider the impact on the attack surface. Introducing redundancy can increase potential vulnerability areas, so ensure that the same security controls protecting your primary systems are equally applied to redundant resources.
Furthermore, it is essential to design efficient recovery processes. An optimal high-availability setup not only minimizes downtime but also streamlines the procedures for restoration in case of failures.
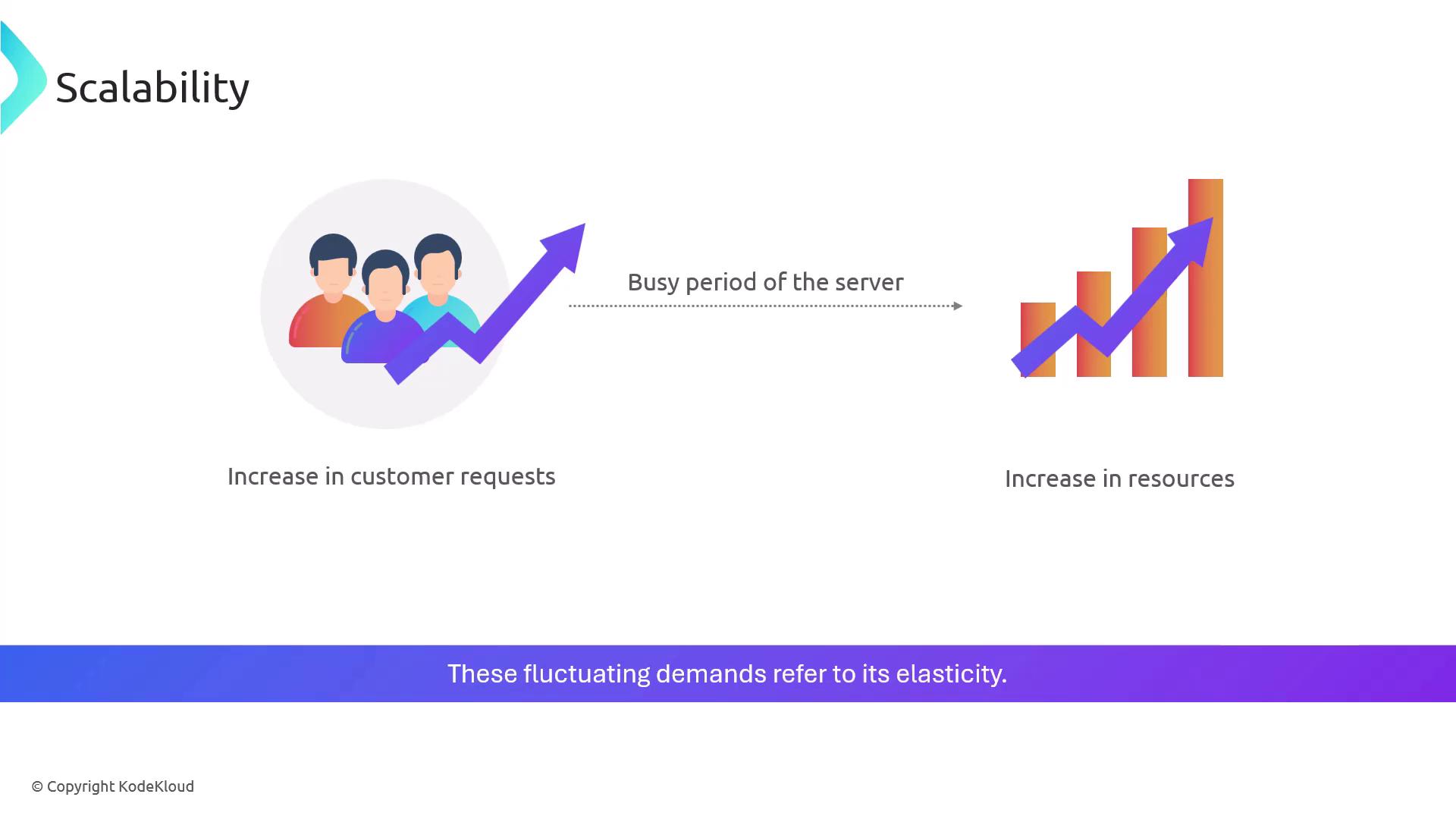
Scalability denotes a system’s capability to dynamically adjust its resources to match fluctuating demands. For instance, during peak times when customer requests surge, the system should seamlessly allocate additional resources. This flexibility is commonly referred to as elasticity.
Fault tolerance ensures that systems continue operating normally even when one or more components fail. Implementing fault tolerance usually requires integrating redundant components that can immediately take over if a failure occurs.
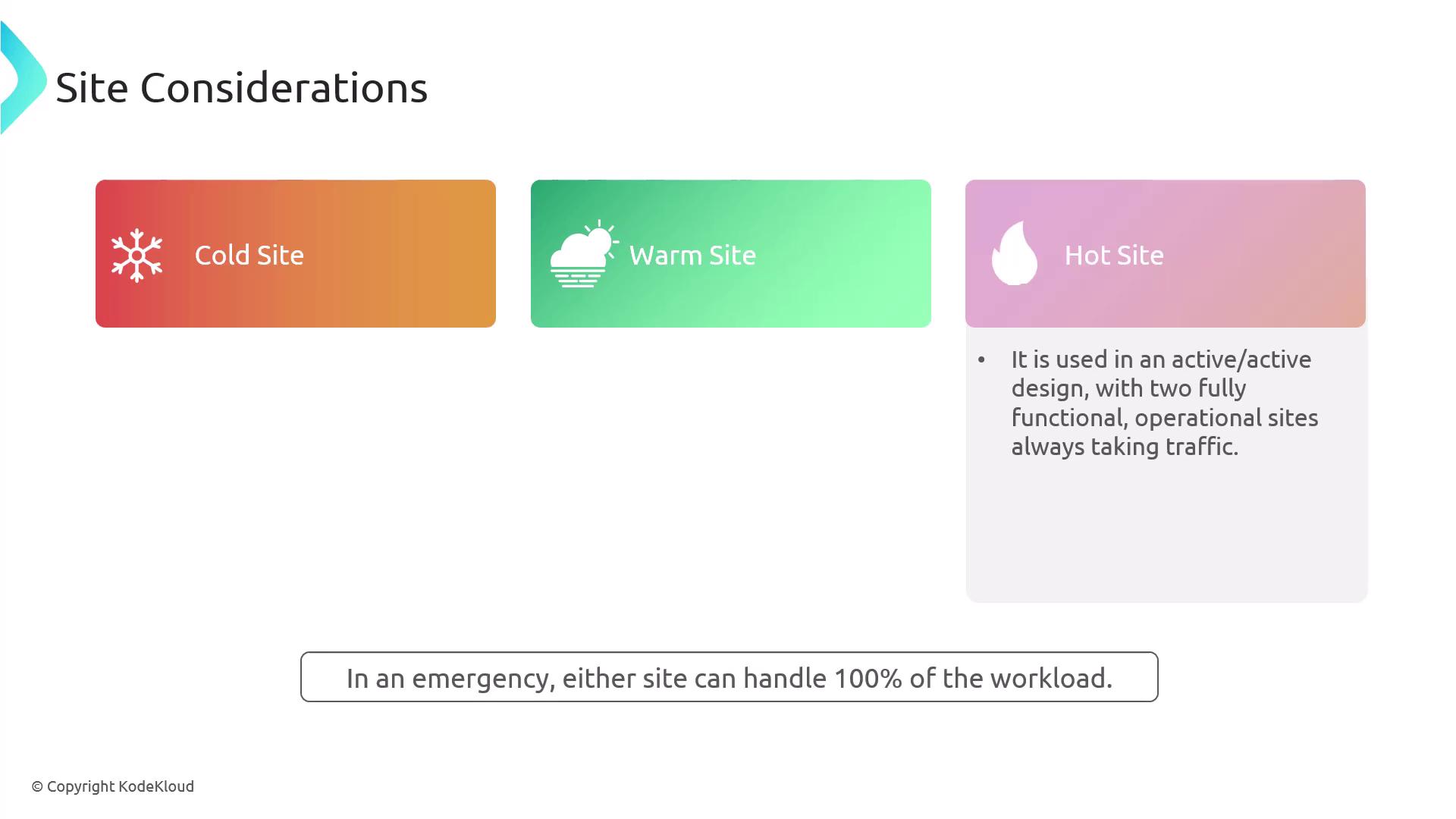
Disaster recovery planning involves identifying and preparing backup sites that can take over in the event of a major incident. There are three primary types of disaster recovery sites:
Cold Site:
A location with no pre-installed equipment. All necessary components must be transported and configured during an emergency. This option typically incurs the longest recovery time.
Warm Site:
A site that comes with some pre-installed equipment that can be activated when a disaster strikes, offering faster recovery than a cold site.
Hot Site:
A fully operational site that runs concurrently with the primary site. In a crisis, either site can assume full workload responsibilities without delay.
When selecting a disaster recovery site, ensure it is geographically distant enough from the primary location to avoid being affected by the same disaster event. Ideally, the failover site should be located in a different state or even another country.
Designing a resilient system requires a holistic approach that incorporates high availability, scalability, fault tolerance, redundancy, and robust disaster recovery strategies. Each element is crucial in maintaining operational continuity and ensuring rapid recovery from unexpected failures.For more detailed information on security architecture, consider exploring additional resources on Kubernetes Documentation, Docker Hub, and the Terraform Registry.